
Insights from paper: Apache Arrow DataFusion: a Fast, Embeddable, Modular Analytic Query Engine

1. Abstract
Apache Arrow DataFusion is a fast, embeddable, and extensible query engine.
It is written in Rust programming language and uses Apache Arrow as its memory model.
The paper describes the technologies used to build it and discusses features, optimizations, architecture, and extension APIs.
DataFusion uses many old technologies but differs from other engines. It provides competitive performance and an open architecture. It can be customized using more than 10 major extension APIs.
2. Introduction
There are many high-performance analytic query engines available. Most of them are tightly integrated systems. Some examples are Vertica, Spark, and DuckDB.
Many analytical systems have been built in the industry, so the best boundaries between subsystems, such as file format, catalog, language front-ends, and execution engine, are known.
DataFusion is designed with these API boundaries in mind. Using standards helps build end-to-end systems from open, reusable, and high-quality components.
For example, the system uses Apache Arrow and Apache Parquet.
The paper makes the following contributions:
(1) It describes the ecosystem of technologies that power DataFusion.
(2) It describes several systems built with DataFusion.
(3) It describes DataFusion’s architecture, feature set, and optimizations.
(4) It defines DataFusion’s extension APIs.
(5) It evaluates DataFusion’s performance.
3. Foundation Ecosystem
DataFusion is possible because of a lot of lower-level technologies.
Apache Arrow’s in-memory columnar structure and compute kernels.
Parquet’s efficient columnar storage.
Rust provides high-performance and comprehensible implementation.
4. Use Cases
Arrow has a lot of use cases. Some of those are the following:
Tailored database systems
Execution run-times
SQL analysis tools
Table formats
4.1 Accelerating Apache Spark
Spark’s design allows replacing the execution engine with a specialized implementation such as Velox and Photon.
Blaze and the Apache Arrow DataFusion Comet project use the DataFusion ExecutionPlans as the engine through JNI interfaces with zero-copy data exchange via Apache Arrow.
Other things, like query front-ends, parsing, analysis, and optimization steps, are used as they are.
5. Deconstructed Databases
DataFusion and similar systems like Apache Calcite and Volex are becoming popular as they enable us to build specialized systems (“fit for purpose”) instead of general-purpose systems (“one size fits all”).
This trend has been called the Deconstructed Database.
5.1 Parallel with LLVM
Monolithic implementation to many specialized systems sharing an open-source foundation has occurred before.
For example, system programming languages recently underwent a similar transformation. Compilers evolved from tightly integrated with systems to modular design sharing the same LLVM backend.
DataFusion is being used as a backend for InfluxDB 3.0, GreptimeDB, and Coralogix in the database world.
6. DataFusion Features
6.1 Architecture Overview
DataFusion works out of the box.
It also provides extensive customization APIs.
The diagram below shows the architecture that allows users to quickly start with a basic, high-performance engine and specialize the implementation over time to suit their needs.
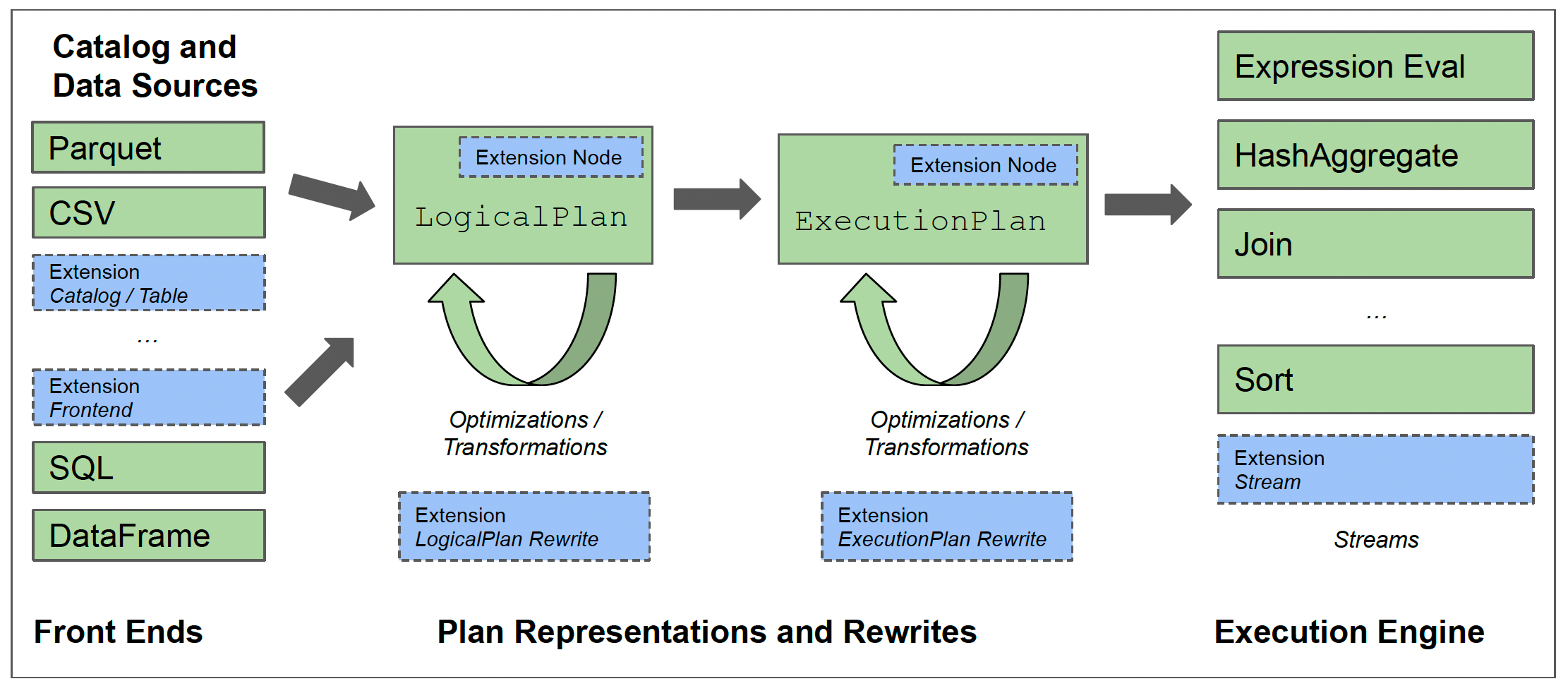
DataFusion’s implementation follows industrial best practices and focuses on well-known patterns like below:
6.2 Catalog and Data Sources
To plan queries, DataFusion needs a Catalog that provides metadata such as which tables and columns exist, their data types, statistical information, and storage details.
DataFusion comes with a simple in-memory catalog and another file-based catalog.
DataFusion includes TableProviders for commonly used file formats: Apache Parquet, Apache Avro, JSON, CSV, and Apache Arrow IPC files.
The built-in formats are also implemented via the exact same API as user-defined TableProviders and support many features.
6.3 Front Ends
DataFusion directly uses the Apache Arrow type system. During execution, operators exchange data as either Arrow Arrays or scalar (single) values.
DataFusion uses the sqlparser-rs library to parse SQL text and generates a LogicalPlan from the parsed query representation.
In addition to SQL, DataFusion also offers a DataFrame API (like pandas). The DataFrame API generates the same underlying LogicalPlan representation as the SQL API.
6.4 LogicalPlan and Optimizer
DataFusion’s API includes:
A full range of structures to represent and evaluate trees of expressions and relational operators, both at logical (Expr and LogicalPlan) and physical (PhysicalExpr and ExecutionPlan) levels.
Libraries to (de)serialize these structures from/to bytes suitable for
network transport, both using Protocol Buffers and Substrait.
DataFusion provides libraries for simplification, interval analysis, and range propagation.
DataFusion features a large library of built-in scalar, window, and aggregate functions. These functions are implemented using the same API as user-defined functions.
DataFusion includes an extensible plan rewriting framework, implemented as a series of LogicalPlan and ExecutionPlan rewrites.
6.5 Execution Engine
DataFusion uses a pull-based streaming execution model.
Streaming Execution: Whenever possible, all operators produce output incrementally as Arrow Arrays grouped into RecordBatches. The default size is 8192 rows. See the example code below.
impl Stream for MyOperator {
...
// Pull next input (may yield at await)
while let Some(batch) = stream.next().await {
// Calculate, check if output is ready
if Some(output) = self.process(&batch)? {
// "Return" RecordBatch to output
tx.send(batch).await
}
}
...
}Data flows between Streams as Arrow Arrays, allowing seamless user-defined operator integration.
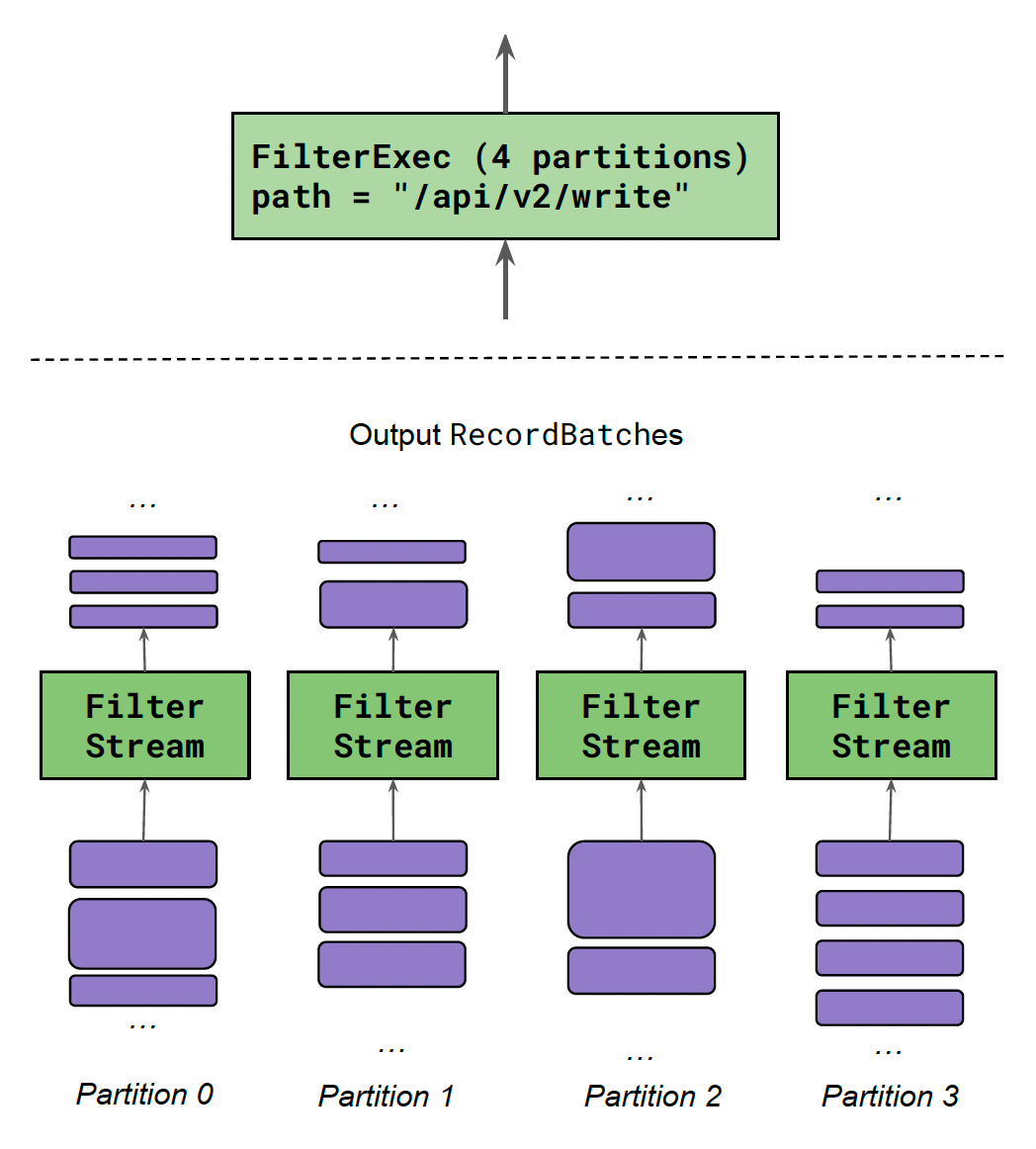
Multi-Core Execution:
Each ExecutionPlan is run using one or more Streams that execute in parallel.
Most Streams coordinate only with their input(s).
Some Streams coordinate with other Streams for HashJoinExec / RepartitionExec.
The number of Streams created for each ExecutionPlan is called its partitioning. It is determined at plan time. See the diagram below:
7. Optimizations
Let’s discuss what techniques are used by DataFusion to execute queries efficiently.
7.1 Query Rewrites
DataFusion includes a variety of query rewrites for both LogicalPlans and ExecutionPlans.
LogicalPlan rewrites include projection pushdown, filter pushdown, limit pushdown, expression simplification, common subexpression elimination, join predicate extraction, correlated subquery flattening, and outer-to-inner join conversion.
ExecutionPlan rewrites include eliminating unnecessary sorts, maximizing parallel execution, and determining specific algorithms such as Hash or Merge joins.
7.2 Sorting
Sorting is one of the most expensive operations in an analytic system. DataFusion, like most commercial analytic systems, includes heavily optimized multicolumn sorting implementations.
7.3 Grouping and Aggregation
Grouping and aggregation are other most expensive operations.
DataFusion contains a two-phase parallel partitioned hash grouping implementation.
It features vectorized execution. When memory is exhausted, it can spill to the disk. It also handles no, partially, and fully ordered group keys.
7.4 Joins
DataFusion automatically identifies equality (equi-join) predicates.
It heuristically reorders joins based on statistics and pushes predicates through joins.
It introduces transitive join predicates and picks the optimal physical join algorithm.
The in-memory hash join is implemented using vectorized hashing and collision checking.
7.5 Window Functions
DataFusion supports SQL Window Functions.
DataFusion minimizes resorting by reusing existing sort orders, sorting only if necessary based on the PARTITION BY and ORDER BY clauses.
It evaluates window functions incrementally.
7.6 Normalized Sort Keys / RowFormat
DataFusion performs well on operations that are naturally vectorized.
DataFusion uses a RowFormat (a form of the normalized key), which permits byte-wise comparisons using memcmp and offers predictable memory access patterns.
The RowFormat is densely packed, one column after another, with specialized encoding schemes for each data type.
7.7 Leveraging Sort Order
DataFusion’s Optimizer knows and takes advantage of any pre-existing order in the input or intermediate results.
DataFusion tracks multiple sort orders and includes Streams optimized for sorted or partially sorted input.
7.8 Pushdown and Late Materialization
DataFusion pushes several operations down (towards the data sources).
Some of those are:
Projection, which removes unnecessary columns
LIMIT and OFFSET, which permit the plan to stop early
Predicates that move filtering closer (or in) to data sources
8. Extensibilities
Let’s discuss the extension points for DataFusion.
Batches of data are represented as ColumnarValues, either a single scalar value or an Arrow Array.
8.1 Scalar, Aggregate, and Window Functions
Systems built on DataFusion often add use case-specific functions that don’t belong in a general function library.
They can be window functions that compute derivatives, calendar bucketing for time series, and custom cryptography functions.
Systems can register the following types of functions dynamically, which receive ColumnarValues as input and produce ColumnarValues as output:
Scalar
Aggregate
Window
8.2 Catalog
Catalogs built with DataFusion use file metadata to avoid reading entire files or parts of files. These are built using a combination of the Catalog API and expression evaluation.
An example is Rust's implementation of the Delta Lake table format, which uses DataFusion to skip reading Parquet files based on filter predicates.
8.3 Data Sources
DataFusion has TableProvider trait. It can query data from different sources like in-memory buffers of Arrow Arrays, stream data from remote servers or read from custom file formats.
DataFusion’s built-in providers are implemented with the same API exposed to users and produce the same Rust async Stream of Arrow Arrays as ExecutionPlans.
8.4 Execution Environment
Execution environments vary widely from system to system.
DataFusion can be customized for different environments using resource management APIs.
MemoryPool can be used.
DiskManager creates reference counted spill files if configured.
CacheManager caches directory contents.
DataFusion comes with simple implementations, and users who require more tailored policies provide their implementations.
9. Related Work
The term “Deconstructed Database” was initially popularized in 2018. It was used in the paper titled - The Modern Data Architecture: The Deconstructed Database.
Velox and Apache Calcite provide components for assembling new databases and analytic systems.
DuckDB is an open-source SQL system that does not require a separate server. DuckDB is targeted at users who run SQL.
10. Conclusions
With the emergence of technologies like DataFusion, the need to build database systems from scratch should be reduced.
The team believes that DataFusion will attract the required investment from large open-source communities, provide a richer feature set, and perform better than all but the most well-resourced, tightly integrated designs.
Modular designs are not the only strategy for building systems; we continue to see new tightly integrated systems emerge.
References
DuckDB: an Embeddable Analytical Database
Velox: Meta’s Unified Execution Engine
Photon: A Fast Query Engine for Lakehouse Systems