
Insights from Paper - Bitcask : A Log-Structured Hash Table for Fast Key/Value Data

Introduction
Before we go to talk about Bitcask, Let’s know What is Riak?
Riak is a distributed NoSQL database. It is highly available, fault-tolerant, and scalable.
As of now, it has three products:
riakkv - A key-value database
riakts - A NoSQL database for IoT/Time Series
riakcs - A distributed S3-compatible storage
One important thing we need to know is that Riak has a pluggable architecture for its core storage.
You know about Riak now, so we will move toward the Bitcask. Bitcask originated from Riak’s need for a storage system that should have below features:
Low latency for read and write
High throughput for random writes
Handle datasets much larger than RAM w/o degradation
Crash friendliness for fast recovery and no data loss
Ease of backup and restore
A simple and understandable code structure and data format
Predictable behavior under heavy access load or large volume
A license that allowed for easy default use in Riak
No storage system at that time could provide all these features.
Eric Brewer provided one insight to authors: hash table log merging can be as fast or faster than the LSM tree.
The authors took that suggestion and explored LSM trees to build Bitcask.
Data Model - Persistence Storage
The Bitcask system is just a directory on the underlying file system with many files inside it. And only one running process can access this directory for writing data at any time.
I want to repeat the above points to highlight how simple the system is. The whole Bitacask can be summarized as one Database server process with access to one active file to write on.
Let’s move ahead and explore the nitty-gritty.
The first point to note is that once an active file reaches a threshold value, a new file is created, and this new file becomes the active file. The old file is closed, and it is immutable now. An active file can be closed normally, or it can be closed abruptly. In both cases, the file becomes immutable after closure.
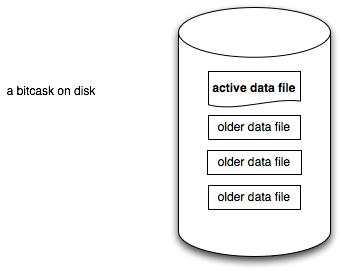
The next important point is that the active file is append-only. The active process with permission to write on this file has its last write position known on the disk, so it can write ( you can say append) very fast. It is one of the secret sauces of Bitcask.
Let’s talk about the data format on disk now. We have already mentioned that Bitcask is a key-value storage. It means the server process has to append the record of variable size. How does Bitcask handle that?
Bitcask carefully adds two headers in the record to store the size of the key and value along with the actual key and value.
The next question can be how the data integrity of key-value is maintained.
Bitcask has a CRC check stored as the first header for the whole record. See the below diagram.

You will be thinking about how the key value's edit or delete is handled. Bitcask considers them as new records and appends them to the active file. This creates a follow-up question of how the correct value is returned in response to a query. The answer is that Bitcask returns the latest value for a given key using the latest record of the key. The deleted key has a tombstone marker value on the record to identify.
It should be clear now that Bitcask needs a background process to do two things, remove the old key and delete records. Bitcask has a merge process to do actual this. It also combines immutable old files and creates new files of only required records to save disk space.
Finally, you can say the Bitcask data file will look like the below diagram:

Data Model - In-memory Storage
We have understood the persistence side of Bitcask. Now let’s explore how the in-memory part of the system works.
We need a way in memory to know where the record for a key exists in the file system directory to retrieve the key-value pair. We can do this if we have the file name and offset on that file for the record. Bitcask has that by a name called keydir in the memory. It is a hashtable where the value has a file identifier as file_id and offset as value_pos. See the diagram below for more details:

Let’s see the write-and-read flow in one go.
For a write operation, keydir is updated atomically with the location of the newest data.
For a read operation, the latest version of data from keydir is read. It needs only one seek operation on the disk to retrieve the value. See the data flow diagram below:

In real life, the operating system’s read-ahead cache can server the data without going to disk.
Let’s talk about the merge process we referred to earlier. So we have a lot of unnecessary data in data files as the keys are updated or deleted. To clean the system, there is a compaction process called merging. It iterates over all non-active (i.e., immutable) files in a Bitcask and produces as output a set of data files containing only the ”live” or latest versions of each present key.
A hint file is created next to each data file during the merge process. This file contains the position and size of the values within the corresponding data file.
Why Bitcask has these files?
The answer lies in its start process. When an Erlang process opens Bitcask, It checks if any other Erlang process is running in the VM using the Bitcask.
If such a process exists, the keydir is shared.
If not, the new Erlang process has to scan all the data files to build the keydir. At that time, hint files come into the picture. The process uses the hint file to quickly build the keydir hashtable instead of going through all source data files.
Goals - Assessment
It is time to see how we are doing against our initial goals.
Low latency for read and write → Early tests show a sub-ms median latency
High throughput for random writes → In a laptop, 5-6k writes per second.
Handle datasets much larger than RAM w/o degradation → 10X RAM size data
Crash friendliness for fast recovery and no data loss→Recovery is trivial
Ease of backup and restore→ It can be any system-provided method
A simple and understandable code → See the source code!
Predictable behavior under heavy access load or large volume→Tested for tens TB data
APIs
The Bitcask system has a very simple and intuitive, self-explanatory API structure.
open(DirectoryName, Opts) → BitCaskHandle | {error, any()}
Open a new or existing Bitcask datastore with additional options. **Valid options include read_write and sync_on_put.
open(DirectoryName) → BitCaskHandle | {error, any()}
Open a new or existing Bitcask datastore for read-only access.
get(BitCaskHandle, Key) → BitCaskHandle | {ok, value}
Retrieve a value by key from a Bitcask datastore.
put(BitCaskHandle, Key, Value) → BitCaskHandle | {error, any()}
Store a key and value in a Bitcask datastore.
delete(BitCaskHandle, Key) → ok | {error, any()}
Delete a key from a Bitcask datastore.
list_keys(BitCaskHandle) → [Key] | {error, any()}
List all keys in a Bitcask datastore.
fold(BitCaskHandle,Fun,Acc0) → Acc
Fold over all K/V pairs in a Bitcask datastore. Fun is expected to be of the form: F(K,V,Acc0) → Acc.
merge(DirectoryName) → ok | {error, any()}
Merge several data files within a Bitcask datastore into a more compact form.
sync(BitCaskHandle) → ok
Force any writes to sync to disk.
close(BitCaskHandle) → ok
Close a Bitcask data store and flush all pending writes to disk.
Conclusion
Bitcask is good for storing millions of key-value pairs. It is a very good choice where all key values can not fit into the in-memory hash map. A maximum of 1 IOPS is required for each read or write. If you are looking to store billions of records or may need very high write throughput, Bitcask is not a good choice; otherwise, it will shine.
References
Original paper: https://riak.com/assets/bitcask-intro.pdf
Source code: https://github.com/basho/bitcask
Riak: https://riak.com/
Not so good but easy Golang implementation: https://git.mills.io/prologic/bitcask
LSM tree : https://www.cs.umb.edu/~poneil/lsmtree.pdf