
Insights from paper: C-Store: A Column-oriented DBMS

1. Abstract
The C-Store paper presents the design of a read-optimized relational DBMS. At the time of writing, most DBMS were write-optimized.
There are a few very different design decisions in the paper:
Storing of data by column rather than by row
Encoding of objects into storage and main memory
Storing an overlapping collection of columns
Non-traditional implementation of transactions
Extensive use of bitmap indexes in place of B-tree indexes
2. Introduction
Most DBMSs implement record-oriented storage systems, which means all the attributes of a record ( also called a tuple) are stored contiguously. That is why these DBMSs are also called row stores.
In row-store, a single disk write is sufficient to push all the attributes of a record to the disk. Due to this, they are considered write-optimized.
The system should be read-optimized if we are interested in ad-hoc querying large amounts of data. Data warehouses are these types of systems.
In column-store architecture, each column (or attribute) value is stored contiguously. DBMSs need to read only the values of columns required for processing a given query.
CPUs are getting faster at a much greater rate than disk bandwidth is increasing. A column store can use CPU cycles to save disk bandwidth in two ways.
First, it can code data elements into a more compact form.
Second, one should pack values densely in the storage.
Commercial relational DBMSs store complete tuples of tabular data along with auxiliary B-tree indexes.
In primary indexes, the rows of the table are stored in as close to sorted order on the specified attribute.
C-Store physically stores a collection of columns, each sorted on some attribute(s).
Groups of columns sorted on the same attribute are called “projections.”
The same column may exist in multiple projections.
C-Store allows redundant objects to be stored in different sort orders providing higher -retrieval performance and high availability.
There is a tension between providing updates and optimizing data structures for reading.
C-store solves this problem by combining the two different stores in one:
Aread-optimized column store
Update/insert-oriented writeable store
The two stores are connected by a tuple-mover, as shown in the below diagram.

Writeable Store (WS) - A small component to support high-performance inserts and updates.
Read-optimized Store (RS) - A more significant component capable of supporting large amounts of read information.
Queries are served from both stores. Inserts are sent to WS, and deletes are marked in RS for later purging.
The system uses a variant of LSM-tree with a merge-out process to move bulk data from WS to RS.
Read-only queries are run in historical mode. Using snapshot isolation, the query is semantically guaranteed to produce the correct answer at that point in history.
3. Data Model
Logical Data Model:
Tables and Attributes: Like traditional relational databases, C-Store logically organizes data into tables consisting of rows (tuples) and columns (attributes). However, data in C-Store is not physically stored using this logical data model; instead, each column is stored separately.
Projections: A projection is a subset of a table's columns, sorted by one or more of those columns.
As long as there is a valid foreign key relationship, a projection may include columns from other tables.
Each projection is stored as a separate entity, and the same column can appear in multiple projections, each potentially sorted by a different attribute.
Primary and Foreign Keys: Projections can be anchored to a table and may include attributes from other tables by following foreign key relationships. This enables efficient joins without needing to access full tables.
A projection has the same number of rows as its anchor table.
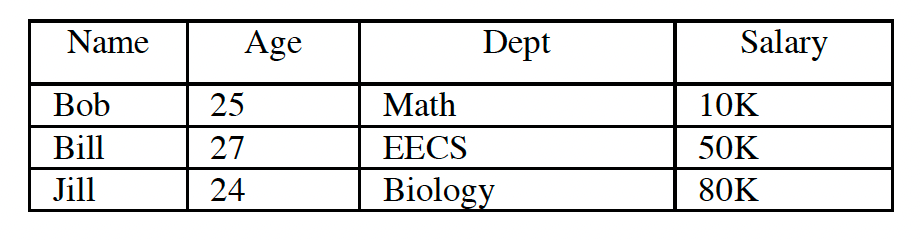
Possible projections for EMP and DEPT:
EMP1 (name, age)
EMP2 (dept, age, DEPT.floor)
EMP3 (name, salary)
DEPT1(dname, floor)A possible ordering for the projections:
EMP1(name, age| age)
EMP2(dept, age, DEPT.floor| DEPT.floor)
EMP3(name, salary| salary)
DEPT1(dname, floor| floor)The sort key can be any column in the projection. Tuples in a projection are sorted on the key(s) in left-to-right order. The sort order of a projection is written by appending the sort key to the projection separated by a vertical bar.
Physical Data Model:
Column Storage: Data is stored column-wise rather than row-wise. This means that for each projection, the columns are stored independently. This storage format reduces the amount of I/O required to read only the necessary columns during query execution.
Segments and Partitions: Projections are horizontally partitioned into segments based on the sort key. Each segment stores data within a specific key range, making distributing data across multiple nodes in a grid environment easier.
Storage Keys (SK): Within each segment, tuples (rows) are identified by storage keys, which are ordinal numbers assigned based on the tuple's physical position in the segment.
These keys are used to reconstruct rows across different columns and projections.
Join Indexes: C-Store uses join indexes to reconstruct rows from projections efficiently.
A join index maps tuples from one projection to another by storing the corresponding tuples' segment ID and storage key.

The first row of the Join Index means that EMP1’s first record (SID 1) is mapped to EMP3’s second record (Key 2).
4. RS
We have seen that RS is a read-optimized column store.
Any segment of any projection is broken into its constituent columns, and each column is stored in order of the sort key for the projection.
The storage key for each tuple in RS is the ordinal number of the record in the segment. This storage key is not stored but calculated as needed.
4.1 Encoding Schemes
In C-Store, the encoding schemes are essential for optimizing the storage and retrieval of data in a column-oriented database.
The system uses different encoding strategies based on the nature of the data in each column to compress the data efficiently.
Type 1: Self-order, Few Distinct Values
Use Case: This encoding is applied to columns sorted by their values (self-order) and contains a small number of distinct values.
Encoding Method:
The data is stored as a sequence of triples
(value, start_position, frequency).value: The actual value in the column.start_position: The position in the column where this value first appears.frequency: The number of times this value appears consecutively in the column.
Example:
If a column contains the sequence
[4, 4, 4, 5, 5, 6], it would be encoded as[(4, 1, 3), (5, 4, 2), (6, 6, 1)].
Benefits:
Efficient storage for columns with few distinct values.
It is easy to search and retrieve data.
Type 2: Foreign-order, Few Distinct Values
Use Case: This encoding is used for columns sorted by the values of another column (foreign-order) but with few distinct values.
Encoding Method:
The data is represented as pairs
(value, bitmap).value: The actual value in the column.bitmap: A bitmap that indicates the positions in the column where this value occurs.The bitmap is run-length encoded (RLE) to save space.
Example:
For a column with values
[0, 0, 1, 1, 2, 1, 0, 2, 1], the encoding would be:[(0, 110000100), (1, 001101001), (2, 000010010)].
Benefits:
Bitmap encoding allows for efficient queries.
Run-length encoding of the bitmap further reduces storage requirements.
Type 3: Self-order, Many Distinct Values
Use Case: It is used for columns sorted by their values (self-order) with many distinct values.
Encoding Method:
Data is encoded as a series of deltas.
The first value is stored as is, and each subsequent value is stored as a delta.
The column is divided into blocks, and each block starts with a base value followed by delta-encoded values.
Example:
For a column with values
[1, 4, 7, 7, 8, 12], it would be encoded as[1, 3, 3, 0, 1, 4].
Benefits:
Effective compression for columns with ordered data.
Delta encoding reduces the storage space required.
Type 4: Foreign-order, Many Distinct Values
Use Case: This is used for columns that are sorted by another column's values (foreign-order) and have a large number of distinct values.
Encoding Method:
This type generally does not apply compression.
A dense-packed B-tree is used for indexing.
Example:
The column is stored in its raw format.
Benefits:
Allows for efficient retrieval of data.
5. WS
We have seen that the Writeable Store (WS) component handles inserts, updates, and deletes in a system optimized for read-heavy operations.
WS is also a column store and implements the identical physical DBMS design as RS.
The storage key, SK, is explicitly stored in each WS segment for each record. A unique SK is given to each insert of a logical tuple in a table T. The execution engine must record this SK in each projection that stores data for the logical tuple.
For simplicity and scalability, WS is horizontally partitioned in the same way as RS. WS is trivial in size relative to RS. Each projection uses B-tree indexing to maintain a logical sort-key order.
Every column in a WS projection is represented as a collection of pairs (v, SK), where v is a column value and sk is its corresponding storage key.
Let’s understand the Join Index better now.
Every projection is represented as a collection of pairs of segments, one in WS and one in RS. For each record in the “sender,” we must store a corresponding record's sid and storage key in the “receiver.”
6. Storage Management
C-store has a storage allocator responsible for allocating segments to nodes in a grid system.
All columns in a single segment of a projection should be co-located. Other than there are a couple of things to take care of:
The Join Indexes should be co-located with their “sender” segments.
Each WS segment will be co-located with the RS segments that contain the same key range.
7. Updates and Transactions
In WS, an insert is represented as a collection of new objects. All inserts corresponding to a single logical record have the same storage key.
The storage key is allocated at the site where the update is received. Each node maintains a locally unique counter to which it appends its local site ID to generate a globally unique storage key.
Internally, WS is built on top of BerkeleyDB.
C-Store isolates read-only transactions using snapshot isolation.
C-Store allows read-only queries to access a consistent database snapshot as it existed at a specific time (timestamp or epoch).
The system divides time into epochs, each representing a period during which data modifications (inserts, updates, deletes) are tracked.
A timestamp authority manages the transition between epochs, ensuring the synchronization of all nodes in a distributed environment.
High Water Mark (HWM) and Low Water Mark (LWM):
The HWM represents the most recent epoch at which all data modifications have been committed.
The LWM is the earliest epoch that needs to be maintained to ensure consistency for historical queries.
7.1 Providing Snapshot Isolation
The key problem in snapshot isolation is determining which of the records in WS and RS should be visible to a read-only transaction running at effective time ET.
To provide snapshot isolation, the system cannot perform updates in place.
An update is turned into an insert and a delete. Hence, a record is visible if inserted before ET and deleted after ET.
The system maintains an insertion vector (IV) for each projection segment in WS, which contains the epoch in which the record was inserted for each record.
The tuple mover ensures that no records in RS were inserted after the LWM.
The system also maintains a deleted record vector (DRV) for each projection with one entry per projection record.
It is 0 if the tuple has not been deleted. Otherwise, the entry contains the epoch in which the tuple was deleted.
The runtime system can now consult IV and DRV to calculate each query's visibility on a record-by-record basis.
Maintaining the High Water Mark
Considering our distributed system, there should be a way to maintain the HWM consistently.
The system designates one site as the timestamp authority (TA), which is responsible for allocating timestamps to other sites. The system defines the initial HWM as epoch 0 and starts the current epoch at 1.
Periodically, the TA decides to move the system to the next epoch. It sends an end-of-epoch message to each site.
Each increments the current epoch from e to e+1. Also, each site waits for all the transactions that began in epoch e (or an earlier epoch) to complete and then sends an epoch-complete message to the TA.
Once the TA has received epoch-complete messages from all sites for epoch e, it sets the HWM to e and sends this value to each site. The process is shown in the below diagram.

7.2 Locking-based Concurrency Control
While C-Store uses snapshot isolation for read-only transactions, it employs traditional locking mechanisms for read-write transactions.
Two-Phase Locking (2PL)
C-Store uses strict two-phase locking (2PL) for read-write transactions, where locks are acquired during execution and released only after the transaction is committed.
This ensures serializability and prevents conflicts between transactions that modify the database.
Deadlock Handling
C-Store handles deadlocks by employing a timeout mechanism. If transactions are involved in a deadlock, they are aborted and rolled back.
UNDO Logging
C-Store logs only UNDO records, which are used to roll back transactions in case of an abort. This approach simplifies the logging process and reduces the overhead associated with traditional logging mechanisms.
Distributed COMMIT Processing
The commit process in C-Store is streamlined to reduce overhead while maintaining consistency across distributed nodes.
Master-Slave Architecture:
Each transaction has a master node that coordinates the execution and commit process across multiple slave nodes.
Single-phase Commit:
C-Store uses a single-phase commit protocol, where the master node waits for all slave nodes to complete their tasks before issuing a commit command.
This approach avoids the overhead of the traditional two-phase commit protocol, where a prepare phase would be required.
Recovery from Crashes:
If a node crashes before committing, C-Store can recover the transaction state from other nodes using the K-safety feature, which ensures system redundancy.
Transaction Rollback
Rolling back a transaction in C-Store involves reverting the changes made during the transaction using the logged UNDO records.
Logical Logging:
C-Store uses logical logging, where only the logical operations (e.g., “delete record X”) are logged, rather than the physical changes to the data.
Rollback Process:
In the event of a transaction abort, the system scans the UNDO log backward, applying the necessary changes to revert the database to its previous state.
Efficiency:
Focusing on logical operations makes the rollback process more efficient and requires less storage than physical logging.
7.3 Recovery
Recovery in C-Store is designed to ensure that the system can quickly return to a consistent state after a failure.
K-Safety:
C-Store is designed with K-safety, which can tolerate up to K simultaneous node failures without losing data.
This is achieved through data replication across multiple nodes.
Crash Recovery:
In the event of a crash, the system uses the UNDO log to roll back any incomplete transactions and then replays any queued updates that were not committed.
Tuple Mover Log:
The Tuple Mover can log which records were moved from WS to RS to facilitate recovery. This log helps the system identify and reconstruct records after a crash, minimizing the need to reprocess large amounts of data.
8. Tuple Mover
The tuple mover moves blocks of tuples in a WS segment to the corresponding RS segment and is also responsible for updating any join indexes in the process.
It runs in the background and performs a merge-out process, MOP when the required tuples are in the system.
MOP finds all records in the chosen WS segment with an insertion time at or before the LWM and then divides them into two groups:
Ones deleted at or before LWM. These are discarded
Some were not deleted or deleted after LWM. These are moved to RS.
MOP will create a new RS segment; let’s call it RS1. It reads blocks from the segment's columns, deletes any RS items with a value in the DRV less than or equal to the LWM, and merges column values from WS.
The merged data is then written out to the new RS1 segment. The most recent insertion time of a record in RS’ becomes the segment’s new t_lastmove and is always less than or equal to the LWM.
I am leaving the query optimization part as it is for advanced users who want to build the system and optimize it based on its performance.
8. Related Work
Data storage via columns has been implemented in several systems. A few of those are MonetDB and Bubba.
Monet is similar to C-Store in terms of design philosophy.
9. Conclusions
The paper presents the design of C-Store, which is radically different from the architecture of current DBMSs. Its innovative features are:
A hybrid architecture with a WS component optimized for frequent insert and update and an RS component optimized for query performance.
The redundant storage of table elements in several overlapping projections in different orders allows a query to be solved using the most advantageous projection.
Heavily compressed columns using one of several coding schemes.
A column-oriented optimizer and executor, with different primitives than in a row-oriented system.
High availability and improved performance through K-safety using a sufficient number of overlapping projections.
The use of snapshot isolation to avoid 2PC and locking for queries.