
Insights from paper - Google FlumeJava: Easy, Efficient Data-Parallel Pipelines

Abstract
MapReduce made the task of writing data-parallel code easy. But many real-world computations require a pipeline of MapReduce. Programming and managing such pipelines is difficult.
Google created a library called FlumeJava. The library makes developing, testing, and running efficient data-parallel pipelines easy.
The library has a couple of core classes representing immutable parallel collections. Each of these supports a modest number of operations for processing them in parallel.
Parallel collections and operations present a simple, high-level, uniform abstraction over different data representations and execution strategies. To enable parallel operations to run efficiently,
FlumeJava internally constructs an execution plan dataflow graph.
When the final results of the parallel operations are eventually needed, FlumeJava first optimizes the execution plan and then executes the optimized operations on appropriate underlying primitives (e.g., MapReduce).
All this yields an easy-to-use system with the efficiency of hand-optimized pipelines. FlumeJava is used in hundreds of pipelines within Google.
Introduction
MapReduce works well for computations that can be broken down into a map step, a shuffle step, and a reduce step.
A chain of MapReduce stages is required for many computations. These data-parallel pipelines require additional coordination code.
FlumeJava aims to support the development of data-parallel pipelines.
It is a Java library. It has classes to represent parallel collections. Parallel collections support parallel operations.
Parallel operations are composed to implement data-parallel computations.
Parallel collections abstract away the details of how data is represented. Data may be represented as an in-memory data structure, as one or more files, or as a database.
Parallel operations abstract away their implementation strategy. An operation may be implemented as a local sequential loop or a remote parallel MapReduce job.
These abstractions help develop and test the pipeline on small in-memory test data. It will run in a single process and can be debugged easily using IDEs.
Later this pipeline can be moved to production without any change for extensive data.
FlumeJava internally implements parallel operations using deferred evaluation. The invocation does not run the operation but records the operation and its arguments in an internal execution plan graph structure.
In this way, the execution plan for the whole computation is constructed.
FlumeJava optimizes the execution plan and finally runs the optimized execution plan. FlumeJava also creates and cleans any intermediate files needed within the computation.
In the real world, the optimized execution plan is typically several times faster than a MapReduce pipeline. The FlumeJava program is easier to understand and change than the hand-optimized chain of MapReduce jobs.
Background on MapReduce
Since FlumeJava builds on top of MapReduce. Let’s take a quick look at it.
You can read my post about MapReduce paper to know in depth.
A MapReduce has three phases:
Map: In this phase, first, we need to read the collection of values or key/value pairs. Then a user-defined map function(Mapper) is invoked on each element independently and in parallel.
Shuffle: The output of the map function in the previous phase is grouped together for the same key. Then it outputs each distinct key and its associated values for the next phase.
Reduce: In this phase, a user-defined reduce function (Reducer) is invoked on each distinct key and its associated values from the previous phase. Normally the reduce function aggregates all the values with a given key. Finally, the output is written to some persistent store.
An optional combiner function can be specified to partially combine values associated with a given key during the Map phase. The Reducer typically completes the combining step, combining values from different Map workers.
An optional user-defined sharder function can be specified that selects which Reduce worker machine should receive the group for a given key. A user-defined Sharder can be used to aid in load balancing.
MapReduce runtime implementation handles the low-level issues of selecting appropriate parallel worker machines, distributing the program to run, managing the temporary storage and flow of intermediate data between the three phases, and synchronizing the overall sequencing of the phases. It also handles transient failures of machines, networks, software, etc.
The FlumeJava Library
FlumeJava library provides constructs for the user’s logical computation and abstract away from the lower-level details. Let’s go through these constructs.
Core Abstractions
The library's most crucial core class is PCollection<T>.
It can either have a well-defined order, or elements can be unordered.
A PCollection<T> can be created from an in-memory Java Collection<T> or by reading a file.
The second core class is PTable<K,V>. It represents an immutable multi-map with keys of type K and values of type V.
PTable<K,V> is a subclass of PCollection<Pair<K,V>>.
The library defines only a few primitive data-parallel operations.
parallelDo()
The core data-parallel primitive is parallelDo(). It supports element-wise computation. over an input PCollection<T> to produce a new output PCollection<S>.
This operation takes as its main argument a DoFn<T, S>. It is a function-like object to map each value in the input PCollection<T> into zero or more values to the output PCollection<S>.
An example of DoFn:
PCollection<String> words =
lines.parallelDo(new DoFn<String,String>() {
void process(String line, EmitFn<String> emitFn) {
for (String word : splitIntoWords(line)) {
emitFn.emit(word);
}
}
}, collectionOf(strings()));FlumeJava includes subclasses of DoFn, e.g., MapFn and FilterFn, that provide simpler interfaces in special cases.
2. groupByKey()
The second primitive is groupByKey(). It converts a multi-map of type PTable<K,V> into a uni-map of type PTable<K, Collection<V>>. Each key in the uni-map maps to an unordered Java Collection of all the values with that key.
The below example computes a table mapping URLs to the collection of documents that link to them.
PTable<URL,DocInfo> backlinks =
docInfos.parallelDo(new DoFn<DocInfo, Pair<URL,DocInfo>>() {
void process(DocInfo docInfo, EmitFn<Pair<URL,DocInfo>> emitFn) {
for (URL targetUrl : docInfo.getLinks()) {
emitFn.emit(Pair.of(targetUrl, docInfo));
}
}
}, tableOf(recordsOf(URL.class), recordsOf(DocInfo.class)));PTable<URL,Collection<DocInfo>> referringDocInfos = backlinks.groupByKey();3. combineValues()
The third primitive is combineValues().
It takes an input PTable<K, Collection<V>> and an associative combining function on Vs and returns a PTable<K, V> where each input collection of values has been combined into a single output value.
For example:
PTable<String,Integer> wordsWithOnes = words.parallelDo(
new DoFn<String, Pair<String,Integer>>() {
void process(String word,
EmitFn<Pair<String,Integer>> emitFn) {
emitFn.emit(Pair.of(word, 1));
}
}, tableOf(strings(), ints()));
PTable<String,Collection<Integer>> groupedWordsWithOnes = wordsWithOnes.groupByKey();PTable<String,Integer> wordCounts = groupedWordsWithOnes.combineValues(SUM_INTS);4. flatten()
The fourth primitive is flatten().
It takes a list of PCollection<T>s and returns a single PCollection<T> containing all the input PCollections elements.
The flatten() does not copy the inputs but rather creates a view of them as one logical PCollection.
Normally, a pipeline concludes with operations that write the final result PCollections to external storage.
Derived Operations
The library includes a number of operations that are derived operations and are implemented in terms of previous primitives.
For example, the count() function takes a PCollection<T> and returns a PTable<T, Integer> mapping each distinct element of the input PCollection to the number of times it occurs.
Deferred Evaluation
FlumeJava’s parallel operations are executed lazily using deferred evaluation.
Each PCollection object is represented internally either in deferred (not yet computed) or materialized (computed).
A deferred PCollection holds a pointer to the deferred operation that computes it. A deferred operation, in turn, references the PCollections that are its arguments and the deferred PCollections that are its results.
The result of executing a series of FlumeJava operations is a directed acyclic graph (DAG) of deferred PCollections and operations. This graph is called an execution plan.
The diagram shows a simplified version of an execution plan.
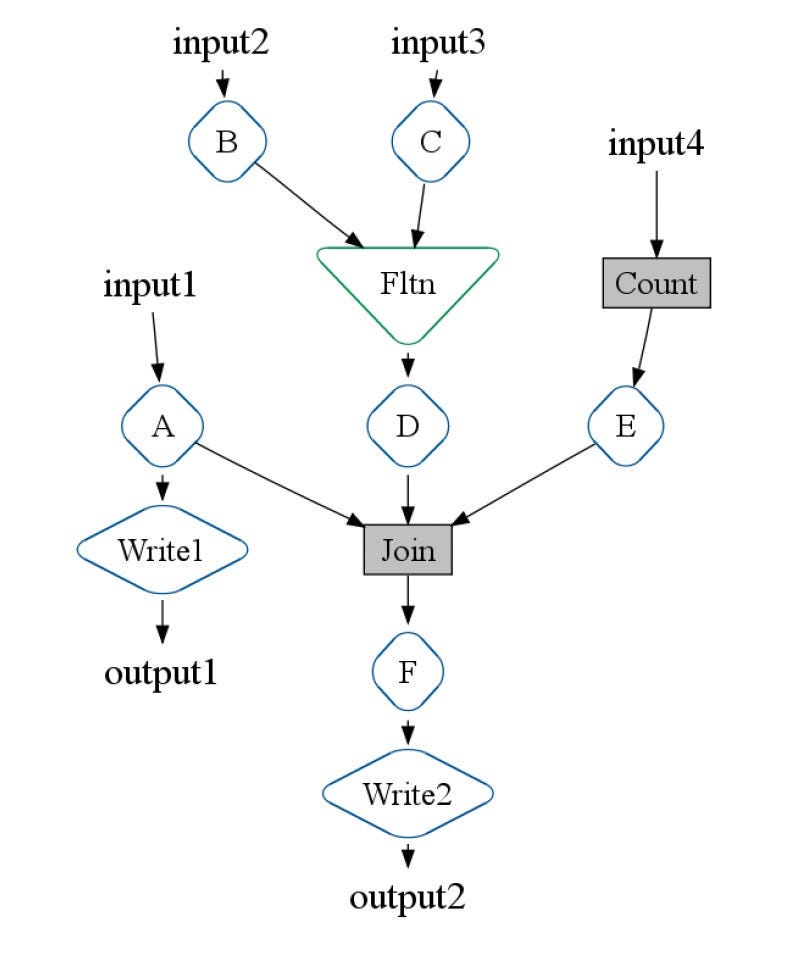
PObjects
FlumeJava hasa class PObject<T>. It is a container for a single Java object of type T.
It is used to inspect the contents of a PCollection. Like PCollections, PObjects can be either deferred or materialized. After a pipeline has run, the contents of a now-materialized PObject can be extracted using getValue().
PTable<String,Integer> wordCounts = ...;
PObject<Collection<Pair<String,Integer>>> result =
wordCounts.asSequentialCollection();
...FlumeJava.run();for (Pair<String,Integer> count : result.getValue()) {
System.out.print(count.first + ": " + count.second);
}In the above code, asSequentialCollection() operation is applied to a PCollection<T>. It yields a PObject<Collection<T>>. This PObject is inspected after the pipeline has run to read out all the elements of the computed PCollection as a regular Java in-memory Collection.
PCollection<Data> results = computeInitialApproximation();
for (;;) {
results = computeNextApproximation(results);
PCollection<Boolean> haveConverged =
results.parallelDo(checkIfConvergedFn(),
collectionOf(booleans()));PObject<Boolean> allHaveConverged =
haveConverged.combine(AND_BOOLS);
FlumeJava.run();if (allHaveConverged.getValue()) break;}In the above example, the combine() operation applied to a PCollection<T> and a combining function over Ts yields a PObject<T>.
Beyond this, The contents of PObjects also can be examined within the execution of a pipeline.
Optimizer
The FlumeJava optimizer is responsible for taking a user-constructed, modular execution plan and transforming it into an efficient one. Let’s discuss a couple of such transformations.
ParallelDo Fusion
It is the most straightforward and most intuitive optimization. It is a function composition or loop fusion.
In simple terms, Let’s consider one ParallelDo operation performs function f and another performs function g. If g can take output of f as input, then a single multi-output ParallelDo (called producer-consumer fusion) can be a replacement that computes both f and g of f.
ParallelDo sibling fusion applies when two or more ParallelDo operations read the same input PCollection.
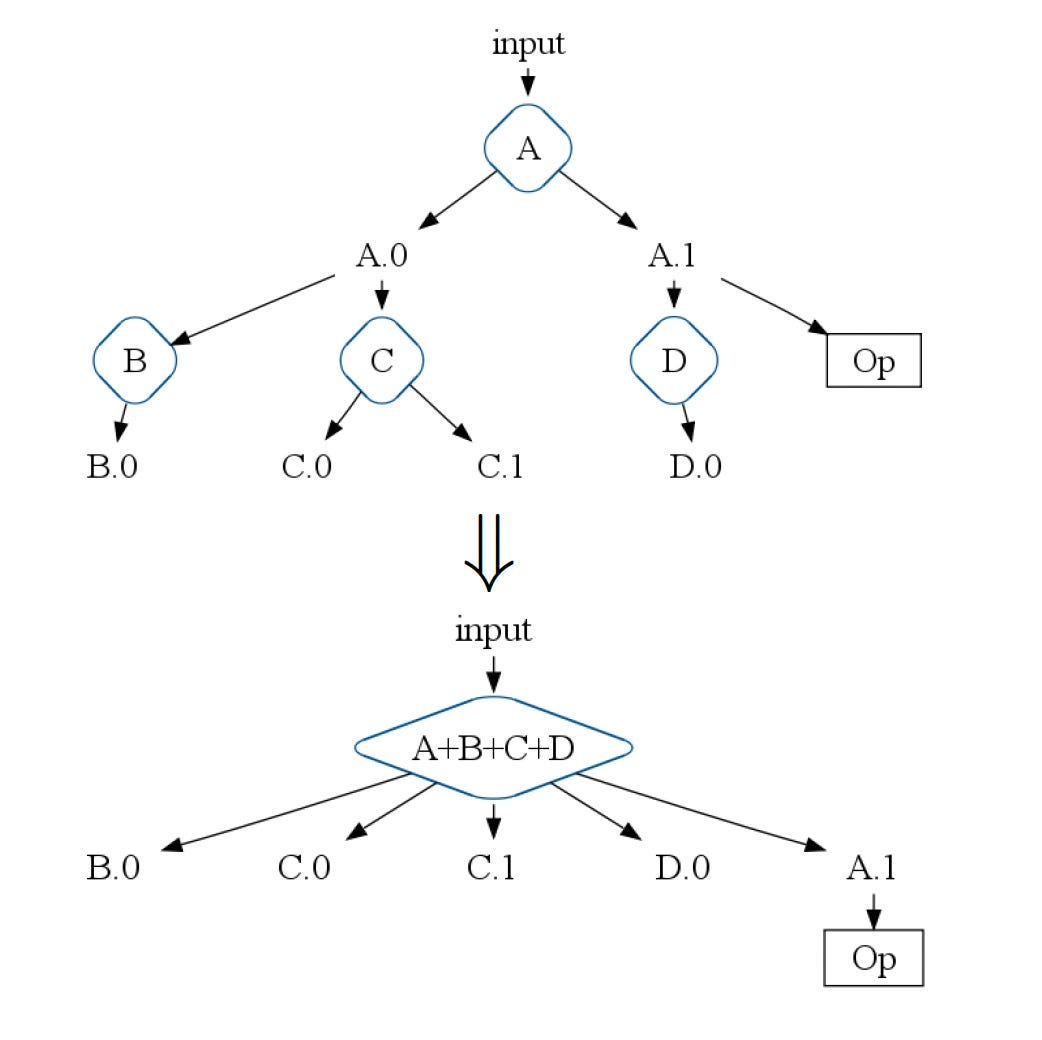
The above diagram shows both producer-consumer and sibling fusion. Here ParallelDo operations A, B, C, and D can be fused into a single ParallelDo A+B+C+D. The new ParallelDo also creates all the leaf outputs from the original graph, plus output A.1.
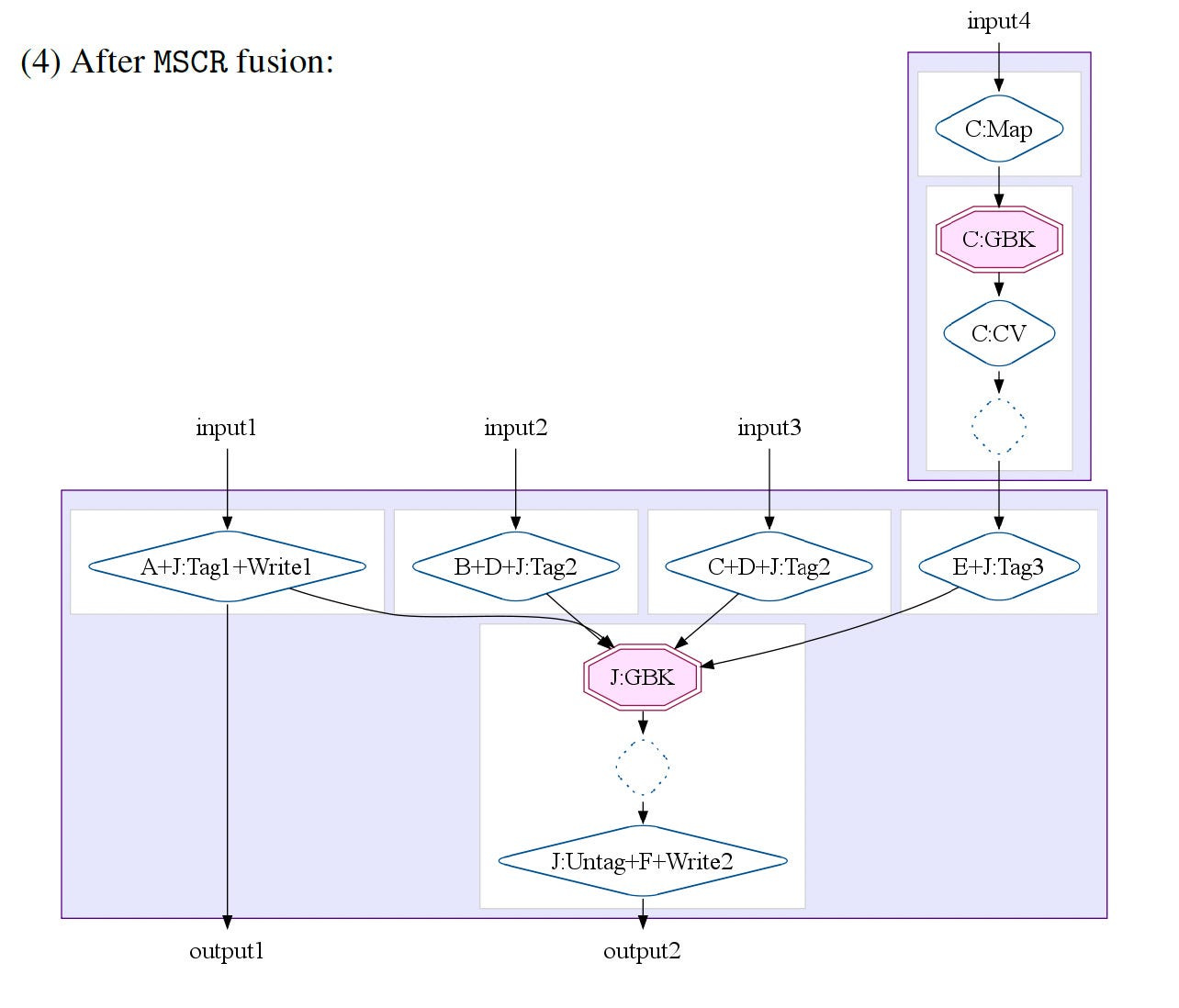
The MapShuffleCombineReduce (MSCR) Operation
We have seen the four core primitives. The most important optimization is to transform a combination of these four ( ParallelDo, GroupByKey, CombineValues, and Flatten).
FlumeJava optimizer has an intermediate-level operation, the MapShuffleCombineReduce (MSCR) operation. An MSCR operation has M input channels and R output channels.
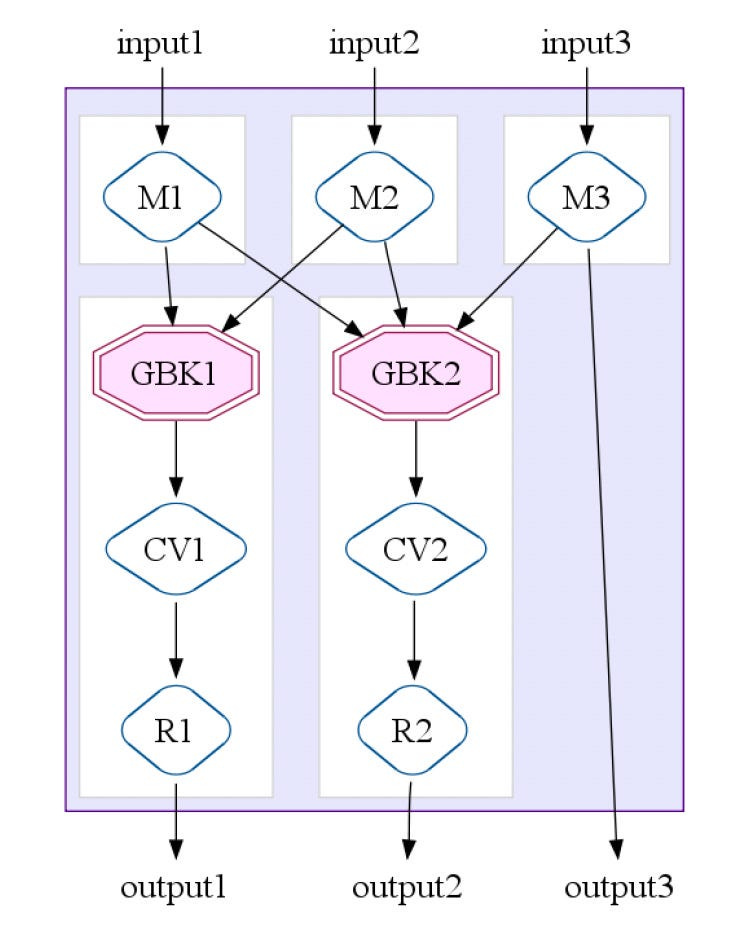
As shown in the above diagram, the input channel can emit only one or a few of its possible output channels.
MSCR generalizes MapReduce by allowing multiple reducers and combiners. It allows each reducer to produce multiple outputs and removes the requirement that the reducer must produce outputs with the same key.
Overall Optimizer Strategy
The optimizer performs a series of passes over the execution plan. The goal is to produce a best-optimized plan. During this process, it tries to do below things:
Sink Flattens.
Lift CombineValues operations.
Insert fusion blocks.
Fuse ParallelDos.
Fuse MSCRs.
Example: SiteData
In the below diagram, you can check how the overall strategy is playing out.


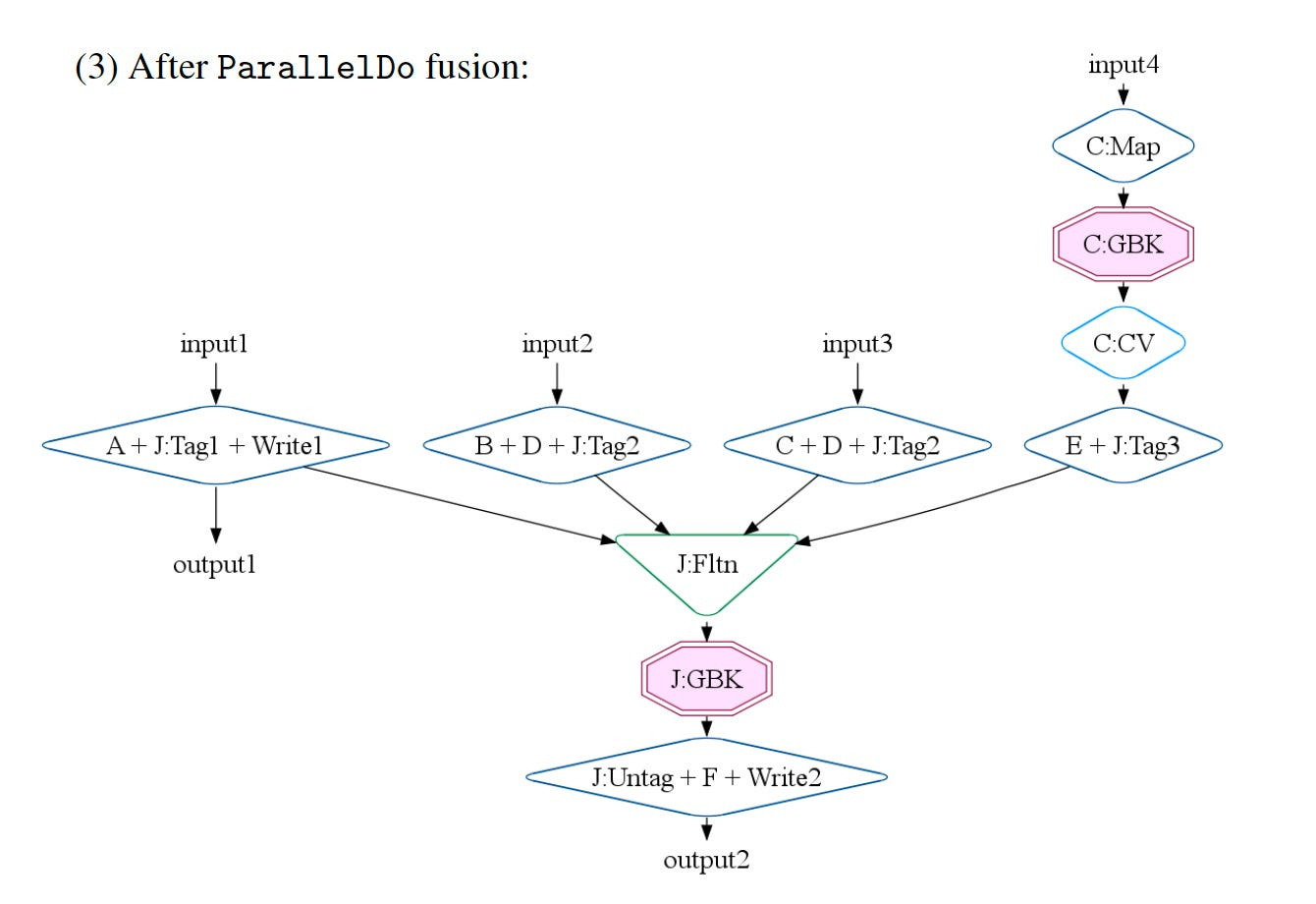
Executor
FlumeJava library runs the most optimized plan once it is created. FlumeJava supports batch execution.
FlumeJava traverses the operations in the plan in forward topological order. It executes independent operations simultaneously.
For MSCR operation, It decides whether the operation should be run locally and sequentially or as a remote, parallel MapReduce.
Typically for modest data size during the development and testing, the operation is run locally. For large data sizes, It launches a remote, parallel MapReduce.
FlumeJava automatically creates temporary files to hold the outputs of each operation it executes. It automatically deletes these temporary files when they are no longer needed.
FlumeJava library supports a cached execution mode. In this mode, rather than recomputing an operation, FlumeJava first attempts to reuse the result of that operation from the previous run.
Related Work
MapReduce combines simple abstractions for data-parallel processing with an efficient, highly scalable, fault-tolerant implementation.
FlumeJava builds on Java MapReduce, offering higher-level, more-composable abstractions and an optimizer for recovering good performance from those abstractions.
Sawzall is a domain-specific logs-processing language implemented as a layer over MapReduce.
Hadoop is an open-source Java-based re-implementation of MapReduce, with a job scheduler and distributed file system.
Cascading is a Java library built on top of Hadoop. Like FlumeJava, Cascading aims to ease the challenge of programming data-parallel pipelines and provides abstractions similar to those of FlumeJava. It explicitly constructs a dataflow graph.
Pig compiles a special domain-specific language called Pig Latin. The code runs on Hadoop.
The Dryad system implements a general-purpose data-parallel execution engine. SCOPE is a declarative scripting language built on top of Dryad.
Map-Reduce-Merge extends the MapReduce model by adding the Merge step.
Before FlumeJava, the team developed a system based on similar abstractions. It was available to users in the context of a new programming language named Lumberjack.
Conclusion
FlumeJava is Java library from Google. It provides simple abstractions for programming data-parallel computations.
The abstractions are built on the Map Reduce programming model and implementation.
FlumeJava’s run-time executor can select different implementation strategies. Those can be locally run or can run as remote MapReduce jobs.
References
The original paper: https://research.google.com/pubs/archive/35650.pdf
Cascading: http://www.cascading.org.
Hadoop: http://hadoop.apache.org.
Pig: http://hadoop.apache.org/pig.
SCOPE: Easy and efficient parallel processing of massive data sets: R. Chaiken, B. Jenkins, P.-A° . Larson, B. Ramsey, D. Shakib, S.Weaver, and J. Zhou. Proceedings of the VLDB Endowment (PVLDB), 1(2), 2008.
MapReduce: Simplified data processing on large clusters: J. Dean and S. Ghemawat. Communications of the ACM, 51, no. 1, 2008.
Dryad: Distributed data-parallel programs from sequential building blocks: M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. In EuroSys, 2007.
LINQ: reconciling objects, relations and XML in the .NET framework: E. Meijer, B. Beckman, and G. Bierman. In ACM SIGMOD International Conference on Management of Data, 2006.
Pig Latin: A not-so-foreign language for data processing: C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins. In ACM SIGMOD International Conference on Management of Data, 2008.
Map-reduce-merge: simplified relational data processing on large clusters : H.-c. Yang, A. Dasdan, R.-L. Hsiao, and D. S. Parker. In ACM SIGMOD International Conference on Management of Data, 2007.
Interpreting the data: Parallel analysis with Sawzall: R. Pike, S. Dorward, R. Griesemer, and S. Quinlan. Scientific Programming, 13(4), 2005.