
Insights from Paper - Monarch: Google's Planet Scale InMemory Time Series Database

Monarch is Google’s globally-distributed in-memory time series database.
Using Monarch, Google monitors the availability, correctness, performance, performance, load, and other aspects of billion-user scale applications and systems.
Monarch stores close to a petabyte of compressed time series data in memory. Every second, the system ingests terabytes of time series data into memory and serves millions of queries.
Monarch has a regionalized architecture for reliability and scalability.It has global query and configuration planes.
Borgmon was the initial system at Google responsible for monitoring internal applications and infrastructure behavior. Borgmon has the following limitations:
Borgmon’s architecture encourages a decentralized operational model where each team sets up and manages its Borgmon instances.
Borgmon doesn’t have schematization for measuring dimensions
and metric values.Borgmon does not have good support for a distribution value type.
Borgmon requires users to shard a large number of monitored entities manually.
Google designed Monarch to scale with continued traffic growth and
support an ever-expanding set of use cases. Monarch provides multi-tenant monitoring as a single unified service for all teams. It has a schematized data model.
This paper covers the following:
A multi-tenant, planet-scale in-memory time series database architecture.
Type-rich relational data model.
Scalable collection pipeline.
System Overview
Monarch’s design is determined by its primary usage for monitoring and alerting.
Monarch trades consistency for high availability and partition tolerance. The monarch must serve the most recent data in a timely fashion. Monarch continues to support monitoring and alerting needs in case of a network partition. It has mechanisms to indicate that the underlying data may be incomplete or inconsistent.
Bigtable, Colossus( successor of The Google File System), Spanner, and Blobstore use Monarch for monitoring. So we cannot use them on
the alerting path to avoid a potentially dangerous circular dependency.
You can read my posts about Bigtable, Spanner, GFS and other papers at www.hemantkgupta.com.
The primary organizing principle of Monarch is local monitoring in regional zones combined with global management and querying. See the diagram below:

In the diagram, Components on the left (blue) persist state; those in the middle (green) execute queries; components on the right (red) ingest data.
Local monitoring allows Monarch to keep data near where it is collected. Global management and querying support the monitoring of global systems by presenting a unified view of the whole system.
Each Monarch zone is autonomous and consists of a collection of clusters. Components in a zone are replicated across the clusters for reliability.
Monarch stores data in memory. Monarch’s global components are geographically replicated and interact with zonal components using
the closest replica to exploit locality.
Monarch components can be divided by function into three categories: those holding state, those involved in data ingestion, and those involved in query execution.
The components responsible for holding states are:
Leaves- It stores monitoring data in an in-memory time series store.
Recovery Logs- The same data as above but on a local disk.
A Global Configuration server and its zonal mirrors — hold configuration data in Spanner.
The components responsible for ingestion are:
Ingestion routers — Route data to leaf routers
Leaf routers — Accept data to be stored in a zone
Range assigners —Manage the assignment of data to leaves
The components responsible for query execution are:
Mixers — Partition queries into sub-queries and merge subquery
results.Index servers — Index data for each zone and leaf
Evaluators — Periodically issue standing queries to mixers and write the results back to leaves.
Data Model
Monarch stores monitoring data as time series in schematized tables.
Each table consists of multiple key columns that form the time series key, and a value column for a history of points of the time series.
Key columns, also called fields, have two sources: targets and metrics.
Targets
Monarch uses targets to associate each time series with its source entity.
Each target represents a monitored entity and conforms to a target
schema that defines an ordered set of target field names and associated field types.
For example, the process or the VM that generates the time series. In the diagram below, there is a popular target schema named ComputeTask. Each ComputeTask target identifies a running task in a Borg cluster with four fields: user, job, cluster, and task num.

Each target schema has one field annotated as location; the value of this location field determines the specific Monarch zone to which a time series is routed and stored.
Within each zone, Monarch stores time series of the same target together in the same leaf because they originate from the same entity and are more likely to be queried together in a join.
Monarch groups target into disjoint target ranges.
A target string represents a target by concatenating the target schema name and field values in order.
Target ranges are used for lexicographic sharding and load balancing among leaves.
Metrics
A metric measures one aspect of a monitored target, such as the number of RPCs a task has served, the memory utilization of a VM, etc.
Similar to a target, a metric conforms to a metric schema, which defines the time series value type and a set of metric fields.
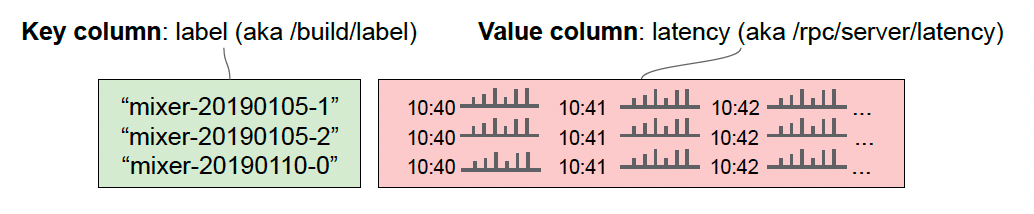
Metrics are named like files. In the previous diagram, an example metric called /rpc/server/latency is shown. It has two metric fields that distinguish RPCs by service and command.
The value type can be boolean, int64, double, string, distribution, or tuple of other types. There is one more distribution type, which is a compact
type that represents a large number of double values.
A distribution includes a histogram that partitions a set of double values into subsets called buckets and summarizes values in each bucket using overall statistics such as mean, count, and standard deviation.
Scalable Collection
Data Collection Overview
The two levels of routers perform two levels of divide-and-conquer.
1. Ingestion routers regionalize time series data into zones according to location fields
2. Leaf routers distribute data across leaves according to the range assigned.
There are four steps for writing data in Monarch:
1. A client sends data to one of the nearby ingestion routers distributed across all our clusters.
2. The ingestion router finds the destination zone based on the value of the target’s location field and forwards the data to a leaf router in the destination zone. The location-to-zone mapping is specified in the configuration to ingestion routers and can be updated dynamically.
3. The leaf router forwards the data to the leaves responsible for the target ranges containing the target. Time series are sharded lexicographically by their target strings. Each leaf router maintains a continuously-updated range map that maps each target range to three leaf replicas. Leaf routers get updates to the range map from leaves instead of the range assigned.
4. Each leaf writes data into its in-memory store and recovery logs.
Leaves do not wait for acknowledgment when writing to the recovery logs per range. Leaves write logs to distributed file system instances in multiple distinct clusters and independently failover by probing the health of a log.
Intrazone Load Balancing
The lexicographic sharding of data in a zone uses only the key columns corresponding to the target schema.
In a single write message, a target can send one-time series points each for hundreds of different metrics. It means that the write message only needs to go to up to three leaf replicas.
Range assigners balance load. They split, merge, and move ranges between leaves. For example, the following events occur once the range assigner decides to move a range, say R, to reduce the load on the source leaf:
1. The range assigner selects a destination leaf with light load and assigns R. The destination leaf starts to collect data for R by informing leaf routers of its new assignment of R, storing time series with keys within R, and writing recovery logs.
2. After waiting one second for data logged by the source leaf to reach disks, the destination leaf starts to recover older data within R, in reverse chronological order, from the recovery logs.
3. Once the destination leaf fully recovers data in R, it notifies the range assigner to unassign R from the source leaf. The source leaf then stops collecting data for R and drops it from its in-memory store.
Collection Aggregation
There are some monitoring scenarios where storing time series data exactly as written by clients is too much expensive.
Collection aggregation solves this problem by aggregating data during ingestion. Monrach uses following techniques:
Delta time series — Collection aggregation requires originating targets to write deltas between adjacent cumulative points instead of cumulative points. The leaf routers accept the writes and forward all the writes for a user to the same leaf replicas. The deltas can be pre-aggregated in the client and the leaf routers, with final aggregation done at the leaves.
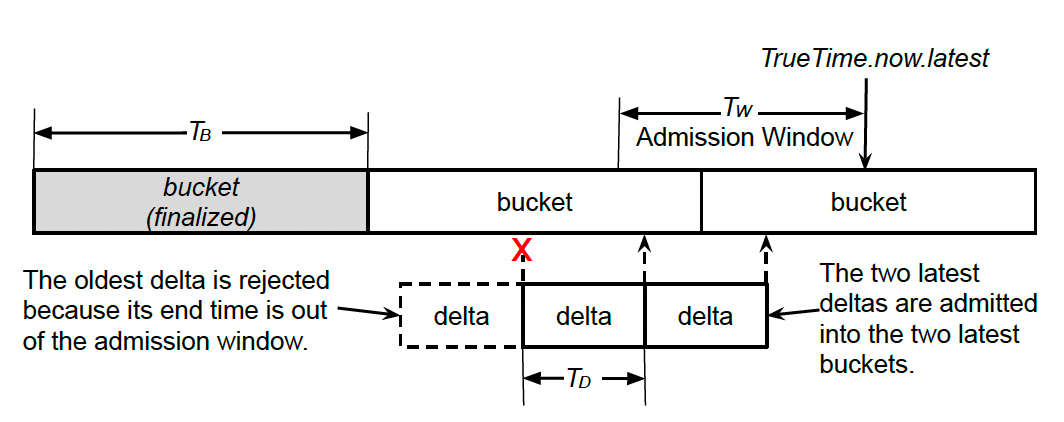
Bucketing — During collection aggregation, leaves put deltas into consecutive time buckets according to the end time of deltas, as shown in the above diagram. The bucket length TB is the period of the output time series and can be configured by clients. The bucket boundaries are aligned differently among output time series. Deltas within each bucket are aggregated into one point according to a user-selected reducer.
Admission window —Each leaf maintains a sliding admission window and rejects deltas older than the window length TW. Therefore, older buckets become immutable and generate finalized points that can be efficiently stored with delta and run-length encoding. Once a bucket’s end time moves out of the admission window, the bucket is finalized. The aggregated point is written to the in-memory store and the recovery logs.
Scalable Queries
Monarch provides an expressive language. It is powered by a distributed engine that localizes query execution.
Query Language
A Monarch query is a pipeline of table operations. Each operation takes zero or more time series tables as input and produces a single table as output. See below an example query:

The output of the query looks like the below diagram:
Query Execution Overview
There are two kinds of queries in the system: ad hoc queries and standing queries.
Ad hoc queries come from users outside of the system.
Standing queries are periodic materialized-view queries whose results are stored back into Monarch.
Standing queries can be evaluated by either regional zone evaluators or global root evaluators. Zone evaluators evaluate most standing queries. They send identical queries to corresponding zone mixers and write the output to their zone. Such queries are efficient and resilient to network partition.
Query tree- Global queries are evaluated in a tree hierarchy of three levels. A root mixer receives the query and fans out to zone mixers, each of which
fans out to leaves in that zone. The zonal standing queries are sent directly to zone mixers.
Level analysis- When a node receives a query, it determines the levels at which each query operation runs and sends down only the parts to be executed by the lower levels.
Replica resolution — To choose the leaf with the best data quality in terms of time bounds, density, and completeness, zonal queries go through the replica resolution process before processing data. Relevant leaves return the matched targets and their quality summary, and the zone mixer shards the targets into target ranges, selecting for each range a single leaf based on the quality.
User isolation. The resources on the query execution nodes are shared among queries from different users. For user isolation, the memory used by queries is tracked locally and across nodes, and queries are canceled if a user’s queries use too much memory.
Query Pushdown
Monarch pushes down evaluation of a query’s table operations as close to the source data as possible.
Pushdown to zone — The data is routed to zones by the value in the location target field. Data for a specific location can live only in one zone. If an output time series of an operation only combines input time series from a single zone, the operation can complete at the zone level.
Pushdown to leaf — The data is sharded according to target ranges across leaves within a zone. Therefore, a leaf has either none or all of the data
from a target. Operations within a target complete at the leaf level.
Field Hints Index
Monarch uses field hints index (FHI), stored in index servers, to limit the fanout when sending a query from parent to children, by skipping irrelevant children.
FHI works with zones with trillions of time series keys and more than 10,000 leaves while keeping the size small enough to fit in memory.
Despite their small sizes (a few GB or smaller), FHIs reduce query fanout by around 99.5% at zone level and by 80% at root level.
Reliable Queries
Monarch handles failures gracefully.
Monarch zones continue to function even during failures of the le system or global components.
Let’s discuss how we make queries resilient to zonal and leaf-level failures.
Zone pruning — Monarch needs to protect global queries from regional failures. Long-term statistics show that almost all (99.998%) successful global queries start to stream results from zones within the first half of
their deadlines. A zone is pruned if it is completely unresponsive by the soft query deadline defined at per zone level.
Hedged reads — A single query may still fanout to more than 10,000 leaves in a zone. To make queries resilient to slow leaf nodes, Monarch reads data from faster replicas.
Configuration Management
A centralized configuration management system is needed to give users convenient, fine-grained control over their monitoring and distribute con- figuration throughout the system.
Configuration Distribution
All configuration modifications are handled by the configuration server. The configuration data is stored in a global Spanner database.
The configuration server is also responsible for transforming high-level configuration to a form that is more efficiently distributed and cached by other components.
Configuration state is replicated to con guration mirrors within each zone, which are then distributed to other components within the zone, making it highly available even in the face of network partitions.
Aspects of Configuration
Users can install their own configuration to utilize the full exibility of Monarch while predefined configuration is already installed.
Followings are the major parts of users’ configuration state:
Schemas
Collection, Aggregation, and Retention
Standing Queries
Related work
Much of the recent research focuses on managing time series is in constrained hardware of wireless sensor network and the Internet of Things.
There are many open source time series databases like Graphite, InfuxDB, OpenTSDB, Prometheus, and tsdb. They store data on secondary storage. The use of secondary storage makes them less desirable for critical monitoring.
Gorilla is Facebook’s in-memory time series database. A Gorilla time series is identified by a string key, as opposed to Monarch’s structured data model. Gorilla lacks an expressive query language. Gorilla replicates data across regions for disaster recovery, limiting availability during a network partition.
Lessons Learned
Paper mentions a few learings as below:
Lexicographic sharding of time series keys improves ingestion and query scalability, enabling Monarch zones to scale to tens of thousands of leaves.
Push-based data collection improves system robustness.
A schematized data model improves robustness and enhances performance.
System scaling is a continuous process.
Running Monarch as a multi-tenant service is convenient for users, but challenging for developers.
Conclusion
Monarch is a planet-scale, multi-tenant in-memory time series database. Monarch operates efficiently and reliably while managing trillions of time series across data centers in many different geographical regions.
It adopts a novel, type-rich relational time series data model that allows efficient and scalable data storage. Monarch also provides an expressive
query language for rich data analysis.
Monarch uses a variety of optimization techniques for both data collection and query execution.
Monarch ingests terabytes of data per second, stores close to a petabyte of
highly-compressed time series data in memory, and serves millions of queries per second. Monarch is serving Google’s monitoring and alerting needs at billion-user scale.
References
Borgmon: SRE book — https://sre.google/sre-book/practical-alerting/
Gorilla: http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
Graphite: https://www.oreilly.com/library/view/monitoring-with-graphite/9781491916421/
InfluxDB: http://influxdata.com.
OpenTSDB: http://opentsdb.net.
Prometheus: http://prometheus.io/
tsdb: https://luca.ntop.org/tsdb.pdf
Bigtable: https://research.google.com/archive/bigtable-osdi06.pdf
Spanner: https://research.google.com/archive/spanner-osdi2012.pdf
The Google File System: https://research.google.com/archive/gfs-sosp2003.pdf