
Insights from paper-(Part I) Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service

Introduction
Amazon DynamoDB is a database as a service (DBaaS) in AWS. It is a fast NoSQL database. It evolved from Dynamo key-value base storage system, which I covered in two parts (part I and part II) post.
To understand how fast we are talking about, the paper mentions, “The goal of the design of DynamoDB is to complete all requests with low single-digit millisecond latencies.”
DynamoDB is used internally in Amazon for Amazon.com, Alexa, all fulfillment centers, and AWS services like AWS Lambda, AWS Lake Formation, Amazon SageMaker, etc. Externally it has hundreds of thousands of customers.
DynamoDB was launched in 2012, and this paper was published in 2022. In these ten years, it has evolved a lot.

DynamoDB has the following six fundamental system properties:
DynamoDB is a fully managed cloud service — Directly create tables and read and write.
DynamoDB employs a multi-tenant architecture — Stores data from different customers on the same physical machines.
DynamoDB achieves boundless scale for tables — No predefined limits for the data each table can store.
DynamoDB provides predictable performance — Same AWS Region apps see latencies in the low single-digit ms range for a 1 KB item.
DynamoDB is highly available — Replicates data across multiple data centers(AZs) and geo-replicated across selected Regions.
DynamoDB supports flexible use cases — Tables don’t have a fixed schema.
What is captured in this paper?
How has it adapted customers’ traffic patterns for physical partitioning?
How has it performed continuous verification of data-at-rest?
How has it maintained high availability as the system evolved?
How has it been designed to provide predictable performance over absolute efficiency?
History
DynamoDB has Dynamo as its predecessor, so its design is motivated by Dynamo. Let’s first look into what Dynamo was.
It was the first NoSQL database developed by Amazon.
It was highly available, scalable, and had a predictable performance.
It was a single-tenant system, and teams managed their own Dynamo installations.
The most challenging part was that each team using Dyanmo had to become experts on various aspects of the Database.
At the same time, Amazon had S3 and SimpleDB, which were fully managed services, and engineers preferred to use them.
Amazon SimpleDB is a fully managed elastic NoSQL database service. It provides multi-datacenter replication, high availability, and high durability. It had some limitations. One limitation was that the table capacity was a maximum of 10 GB. Another limitation was the unpredictable query
and write latencies.
The solution was to combine the best of both Dynamo and Simple DB. It is quoted in the paper.
“We concluded that a better solution would combine the best parts of the original Dynamo design (incremental scalability and predictable high performance) with the best parts of SimpleDB (ease of administration of a cloud service, consistency, and a table-based data model that is richer than a pure key-value store).”
Finally, Amazon DynamoDB, a public service launched in 2012.
Architecture
Basics
A DynamoDB table is a collection of items, and each item is a collection of attributes. A primary key uniquely identifies each item.
The primary key contains a partition key or a partition and sort key (a composite primary key).
The partition key’s value is hashed and combined with the sort key value (if any) to determine where the item will be stored.
In addition to that, there are secondary indexes. A secondary index allows querying the data in the table using an alternate key ( beyond the primary key).
DynamoDB provides a (Get/Put/Update/Delete)Item calls to store and retrieve the items. A condition can be specified in the call, which must be satisfied to succeed in the call.
One important thing to note is that DynamoDB supports ACID transactions so that applications can update multiple items within a transaction.
Partitioning and Replication
A DynamoDB table is divided into multiple partitions. Each table partition hosts a disjoint and contiguous part of the table’s key range. Each partition has multiple replicas distributed across different AZs for high availability and durability.
All the replicas for a partition combined form a replication group. There is a leader replica in this group.
DynamoDb logically has two kinds of requests. One is writes or strongly consistent reads, and another is eventually consistent reads.
Writes or strongly consistent reads are served by the leader replica only, but eventually consistent reads can be served by any replica in the group.
Leader election and consensus inside a replication group are managed using the Multi-Paxos algorithm. Once a replica is elected as a leader, it can continue to become the leader if it can renew its leadership lease periodically.
If the replica leader is failure detected by any of its peers, the peer can propose a new round of election to elect itself as the new leader. The new leader won’t serve any writes or consistent reads until the previous leader’s lease expires.
A replication group consists of storage replicas that contain both the write-ahead logs and the B-tree that stores the key-value data. A replication group can also contain replicas that only persist recent write-ahead logs.
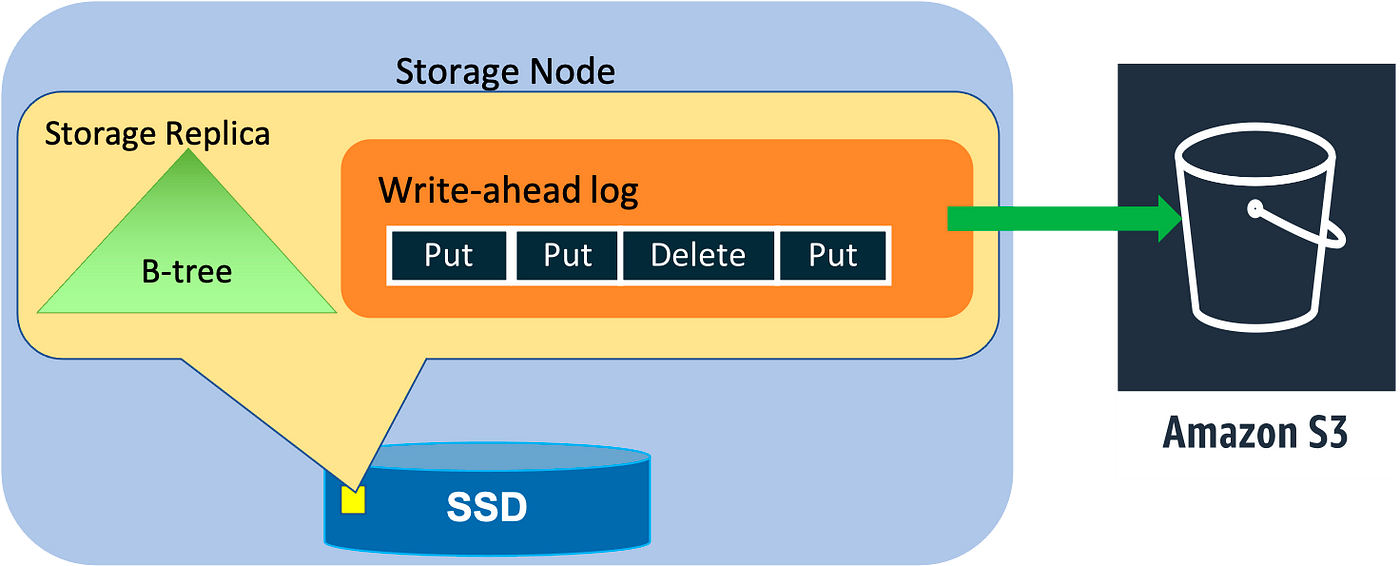

Log replicas help in improving availability and durability. We will discuss that in the following sections.
DynamoDB consists of tens of microservices. Let’s understand those.
Metadata service —It stores routing information about the tables, indexes, and replication groups for keys for a given table or index.
Request routing service — is responsible for authorizing, authenticating, and routing each request to the appropriate server. The request routers look up the routing information from the metadata service.
Storage service — It is responsible for storing customer data on a fleet of storage nodes.
Autoadmin service — It is responsible for fleet health, partition health, scaling of tables, and execution of all control plane requests.

Provisioned to on-demand
In the original DynamoDB release, customers explicitly specified the throughput (called provisioned throughput) table required regarding read capacity units (RCUs) and write capacity units (WCUs) combined.
The original design splits a table into partitions that allow its contents
to be spread across multiple storage nodes and mapped to the available space and performance on those nodes. As the demands from a table changed, partitions could be further split and migrated to allow the table to scale elastically.
This tight coupling of assigning both capacity and performance to individual partitions became a problem in future.
If you have read my Dynamo Part II post, you know there was an Admission control system to handle background and foreground tasks in Dynamo. It is present in DynamoDB also and has evolved to a great extent in the last decade.
DynamoDB uses admission control to ensure that storage nodes don’t become overloaded. Admission control was the shared responsibility of all storage nodes for a table. Storage nodes independently performed admission control based on the allocations of their locally stored partitions.
DynamoDB enforced a cap on the maximum throughput allocated to a single partition considering a storage node has partitions from different tables. It also ensured that the total throughput of all the partitions hosted
by the storage node is less than or equal to the maximum allowed throughput on the node.
In the above case, the throughput allocated to partitions was adjusted only in two cases. Either the overall table’s throughput was changed, or its partitions were split into child partitions.
The uniform distribution of throughput across partitions is based on the assumption that an application uniformly accesses keys in a table, and splitting a partition for size equally splits the performance.
In the real world, there are non-uniform access patterns both over time and over key ranges. Splitting a partition and dividing performance allocation proportionately can result in a hot partition. This will lead to throttling for the application as throughput was capped for the partition.
So we have two widespread problems — Hot partitions and throughput dilution. To highlight the causes, let’s remember that a hot partition will occur when there is heavy traffic for a few items of tables, and throughput dilution will happen when the partition is split for size.
Initial improvements to admission control
Bursting
Not all partitions hosted by a storage node used their allocated throughput at the same time. DynamoDB introduced a concept of bursting, where it retained a portion of a partition’s unused capacity for a later time (up to 300
seconds). This unutilized capacity is called burst capacity. It can be utilized when the consumed capacity exceeds the provisioned capacity of the partition.
One crucial thing to note — A partition can use burst capacity only if at the storgate node level there is unused throughput otherwise it cannot.
2. Adaptive capacity
The challenge with burst capacity is that it cannot take care of long lived spikes. So how Adaptive capacity works?
It actively monitors the provisioned and consumed capacity of all the tables.
If a table experienced throttling and the table level throughput was not exceeded, then it would automatically increase (boost) the allocated
throughput of the partitions of the table.If the table was consuming more than its provisioned capacity then capacity of the partitions which received the boost would be decreased.
The autoadmin system ensured that partitions receiving boost were relocated to an appropriate node that had the capacity to serve the increased throughput.
One important point paper mentions that adaptive capacity eliminated over 99.99% of the throttling due to skewed access pattern.
I will cover the Global Admission Control, Durability and Availability in the next part of the post.
References
Amazon DynamoDB paper: https://www.usenix.org/system/files/atc22-elhemali.pdf
Dynamo: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
Amazon SimpleDB: https://aws.amazon.com/simpledb/.
Paxos made simple: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf