
Insights from paper (part II) - Google Mesa: Geo Replicated, Near Real-Time, Scalable Data Warehousing

In the previous post, we learned a few basic concepts of the Google Mesa data warehousing system.
In this post, we will dive deep into architecture and other areas.
System Architecture
Mesa uses Colossus (Google File System) and Google BigTable. It runs in multiple data centers. Each data center runs one instance of Mesa.
Let’s first discuss how each single instance is designed. After that, we will discuss how these instances are integrated to create a multi-data center deployment.
Single Datacenter Instance
There are two subsystems for each instance.
Update and maintenance system
Querying system
Both these systems are decoupled and can be scaled independently.
All the metadata is stored in BigTable, and the data files are stored in Colossus.
Update/Maintenance Subsystem
This subsystem performs all necessary operations to ensure the data in the local Mesa instance is correct, up-to-date, and optimized for querying.
It runs various background operations such as loading updates, performing table compaction, applying schema changes, and running table checksums.
These operations are done by a collection of components known as the controller/worker framework shown in the below diagram.
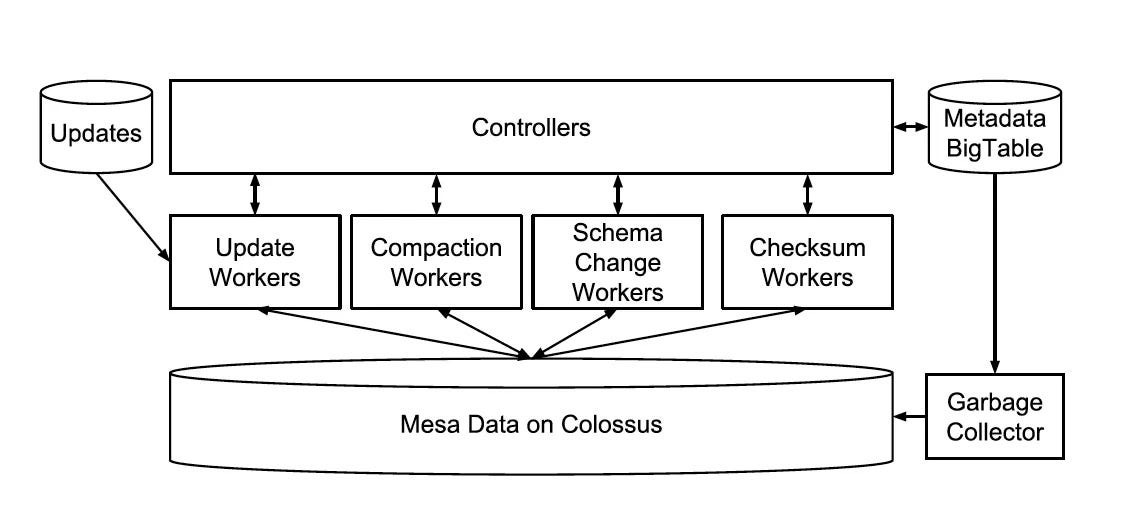
The controller/worker framework
There are three main things a controller does:
Manage table metadata
Act like a work scheduler
Act like a work queue manager
The first and most crucial thing is table metadata. It is stored in BigTable. It consists of the following things for state and operations for each table :
Entries for all delta files
Update versions associated with the table
Delta compaction policy assigned to the table
Accounting entries for current and previously applied operations
Before we proceed, let’s be clear that the controller/worker does not manipulate actual table data.
So the actual work of the controller is to be the exclusive writer of table metadata.
At startup, the controller loads table metadata from a BigTable.
The controller component subscribes to a metadata feed for table updates. This subscription is dynamically modified as tables are added or dropped.
We can divide the operations into two categories — one for local instance and the other for all instances across the deployment.
The controller maintains separate internal queues for different types of data manipulation work.
For local operations, the controller determines what work to queue.
For global operations, some other component outside the context of a single instance determines the work, and the controller only accepts those work requests by RPC and inserts them into the corresponding queues.
A few examples of global operations are schema changes and table checksums.
The worker components perform the data manipulation work within each Mesa instance.
There is a separate set of worker pools for each task type. Each of these worker pools can be scaled independently. Mesa has an in-house worker pool scheduler for scaling.
Each idle worker periodically polls the controller to request work. Upon receiving valid work, the worker validates the request, processes the retrieved work, and notifies the controller when the task is completed.
The controller has to ensure that a slow or dead worker does not hold on to the task forever. Each task has an associated maximum ownership time and a periodic lease renewal interval. The controller is free to reassign the task if needed.
A garbage collector runs continuously to delete files left behind due to worker crashes.
The controller/worker components can be restarted without impacting external users.
Query Subsystem
The query subsystem consists of only query servers, as shown in the below diagram.
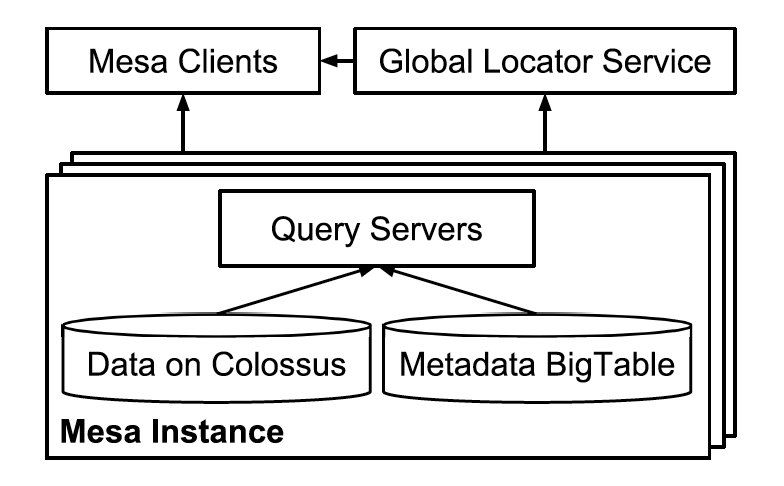
The work done by these servers is very straightforward. They look up table metadata to determine the set of files storing the required data for a query.
They perform on-the-fly aggregation of this data, convert it from the Mesa internal format to the client protocol format, and returns it.
This subsystem provides a limited query engine with essential support for server-side conditional filtering and “group by” aggregation.
The query servers in an instance are organized into multiple sets. Each set is capable of serving all tables known to the controller.
These sets help in performing query server updates without any downtime. They can automatically fail over to another when required.
Mesa allows in-memory pre-fetching and caching of data stored in Colossus. It helps serve strong latency guarantees.
Each query server registers the list of tables it actively caches on startup with a global locator service. The clients discover query servers using this service. This way, load balancing across these query servers helps serve excellent throughput.
Multi- Datacenter Deployment
Till now, we have been focusing on how one single instance of Mesa in a data center works. Let’s move toward the multi-datacenter deployment design.
Consistent Update Mechanism
Mesa has a committer component responsible for coordinating updates across all Mesa instances ( in multi-data center deployment).
We have seen that all tables in Mesa are multi-versioned. The committer takes care of updates one version at a time.
There is a versions database in Mesa. It is a globally replicated and consistent database. It uses the Paxos consensus algorithm.
The committer assigns each update batch a new version number. Then it publishes all metadata associated with the update to the versions database.
If you have been following carefully till now, you will recall that I have mentioned that the controller gets the work from out of context of a single instance component. That component is versions database. The controllers listen to the changes to the versions database.
The controller assigns the work for these changes to workers using queues, and reports back to the versions database.
The committer continuously evaluates if commit criteria are met across all tables in the update.
When the commit criteria are met, the committer declares the update’s version number to be the new committed version.
This new version number is stored in the versions database, and all new queries are always issued against this committed version.
This process has two exciting benefits:
Mesa does not require any locking between queries and updates.
All update data is incorporated asynchronously, and only metadata is passed synchronously to the versions database.
New Mesa Instances
Mesa has a special load worker, similar to other workers in the controller/worker framework. This worker is responsible for copying data from another Mesa instance to the current one.
This load worker is used to bootstrap a new Mesa instance in a new data center.
Mesa also uses this mechanism to recover from table corruption.
Enhancements
Query Server Performance Optimizations
Once a query arrives at the query server, it examines the metadata for the key range that each delta contains. If the filter in the query falls outside that range, the delta can be pruned entirely.
Mesa has scan-to-seek optimization for the queries which require a scan of the entire table.
Mesa returns data to the clients in a streaming fashion, one block at a time. With each block, Mesa attaches a resume key. A client can transparently switch to another query server, if needed, by resuming the query from the resume key.
ParallelizingWorker Operation
The sequential processing of terabytes of table data can take over a day. Mesa typically uses the MapReduce framework for parallelizing the execution of different types of workers.
Schema Changes in Mesa
Mesa users frequently need to modify schemas associated with Mesa tables.
It is expected that all schema changes are online. Mesa uses two main techniques to perform online schema changes: a simple but expensive method that covers all cases, and an optimized method that covers many critical common cases.
Normal method :
(i) Make a separate copy of the table with data stored in the new schema version at a fixed update version
(ii) Replay any updates to the table generated in the meantime until the new schema version is current
(iii) Switch the schema version used for new queries to the new schema version as an atomic controller BigTable metadata operation.
Older queries may continue to run against the old schema version for some amount of time before the old schema version is dropped to reclaim space.
Optimized method
This method is applicable only for specific schema changes like adding a column.
Mesa performs a linked schema change by treating the old and new schema versions as one for update/compaction. Mesa makes the schema change visible to new queries immediately, handles conversion to the new schema version at query time on the fly, and similarly writes all new deltas for the table in the new schema version.
Mitigating Data Corruption Problems
Faulty hardware or software will cause incorrect data to be generated and/or stored. Simple file-level checksums are not sufficient to defend against such events. All instances store the same data at the logical level, but the specific delta versions are different.
Mesa leverages this diversity to guard against corruption.
Online checks are done at every update and query operation. Mesa performs row ordering, key range, and aggregate value checks when writing deltas. Since Mesa deltas store rows in sorted order, the libraries for writing Mesa deltas explicitly enforce this property.
Mesa also periodically performs global offline checks, the most comprehensive of which is a global checksum for each table index across all instances.
Experiences and lessons learned
Distribution, Parallelism, and Cloud Computing — Mesa can manage large rates of data growth through its absolute reliance on the principles of distribution and parallelism.
Modularity, Abstraction, and Layered Architecture — It is recognized that layered design and architecture are crucial to confront system complexity, even if it comes at the expense of performance loss.
Capacity Planning — Mesa was transitioned to Google’s standard cloud-based infrastructure, dramatically simplifying capacity planning.
Application Level Assumptions — The design should be as general as possible with minimal assumptions about current and future applications. For example, the Mesa team assumed schema changes would be very rare, but this was not the case in real life.
Geo-Replication — Mesa has the added benefit of geo-replication regarding day-to-day operations. Now planned outages, which are fairly routine, have minimal impact on Mesa.
Data Corruption and Component Failures — Data corruption and component failures are a major concern for systems at the scale of Mesa. Overcoming such operational challenges remains an open problem.
Testing and Incremental Deployment — Mesa team can consistently deliver major improvements with minimal risk by combining some standard engineering practices with Mesa’s overall fault-tolerant architecture and resilience to data corruption.
Human Factors — The main challenge is communicating and keeping the knowledge up-to-date across the entire team. The team currently relies on code clarity, unit tests, documentation of standard procedures, operational drills, and extensive cross-training of engineers across all system parts.
Conclusions
This paper presents Googles’s Mesa for an end-to-end design and implementation of a geo-replicated, near real-time, scalable data warehousing system.
The engineering design of Mesa leverages foundational research ideas in the areas of databases and distributed systems.
Real-time analysis over vast volumes of continuously generated data has emerged as an essential challenge in database and distributed systems research and practice.
Mesa supports petabyte-scale data sizes and large update and query workloads.
References
The original Mesa paper: https://research.google.com/pubs/archive/42851.pdf
Part 1 of the post:
https://www.hemantkgupta.com/p/insights-from-paper-part-i-google