
Insights from paper: Presto: A Decade of SQL Analytics at Meta

1. Abstract
Before I start talking about Presto, let me tell you that it has been renamed Trino.
Presto is an open-source distributed SQL query engine.
Presto supports analytics workloads for multiple exabyte-scale of data.
It can be used for low-latency interactive use cases and long-running ETL jobs.
Presto was created at Facebook( Meta now) in 2013 and donated to the Linux Foundation in 2019.
In the last decade, Presto continued improving query latency and maintained scalability for the hyper-growth of data volume at Meta.
During this period, a few new challenges emerged in the analytics world, such as supporting machine learning, privacy, and graph analytics.
The paper discusses several successful evolutions of Presto, including hierarchical caching, native vectorized execution engines, materialized views, and Presto on Spark.
2. Introduction
Presto provides a SQL interface to query data stored on different storage systems.
Presto is being used in Uber, Twitter, Intel, etc.
Meta actively contributes to Presto and is used for interactive, ad-hoc, and extract-transform-load (ETL) workloads at scale.
At the time of paper writing, an effort was being made in Meta to move all SparkSQL workloads to Presto.
Originally, Presto was designed to process interactive SQL queries in memory.
Since it was efficient, teams started using it for lightweight ETL jobs (up to 10 minutes).
Let’s discuss the different challenges.
Latency and Efficiency:
The scan cost of a query increases when the data volume is higher. Adding more machines is not sufficient. More latency improvements are required to ensure users can still have a low-latency dashboarding experience with large, scalable data scans.
Scalability and Reliability:
Presto was not designed to provide fault tolerance, and hardware limits memory.
So, new approaches were required to support ETL workloads that are orders of magnitude heavier in CPU, memory, and runtime.
Beyond data analytics:
The modern warehouse has become a data lake.
There are diverse use cases to support this. For example, Meta’s machine learning-related data volume exceeded that of analytics.
3. Architecture and Challenges
At the time of this paper's writing in 2022, Meta had 21 data centers worldwide, each million square feet in size. Meta has a huge amount of data in all these data centers.
The diagram below shows the original architecture of a Presto cluster.
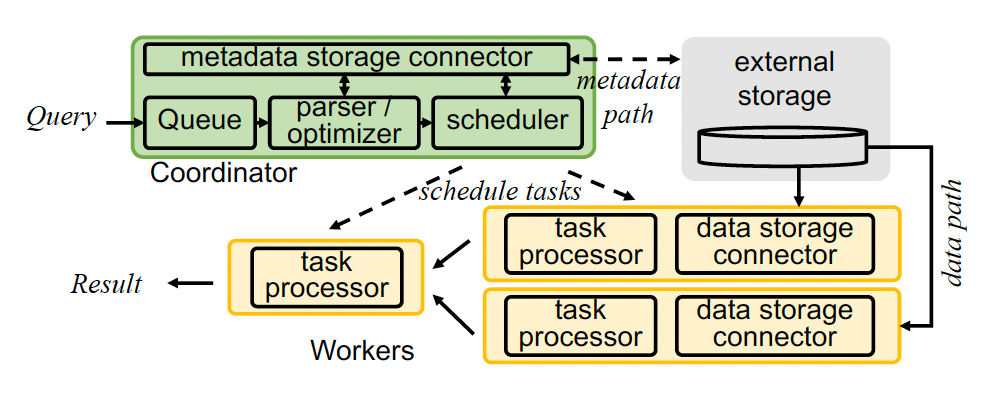
The cluster has a single coordinator and several (thousands)workers.
The coordinator is responsible for queueing and parsing a query string and then turning it into a plan. The plan is optimized, and plan fragments are created.
The fragments will be scheduled to workers in parallel.
Workers are responsible for query processing with all data in memory and data shuffling through streamed RPCs over the network.
Each worker will launch tasks to process the data based on the fragments received.
The processed data will be shuffled into different buffers in memory.
In this architecture, compute and storage are disaggregated. External IO will increase the latency. From a scalability point of view, the coordinator is the single point of failure (SPOF). Also, workers lack fault tolerance.
Let’s now move to the new architecture.

When a query is sent to Presto, It can be run in the following two ways:
In original architecture with multiple coordinators. It has native vectorized execution, data cache on Flash, and other improvements.
In a new architecture that is powered by Spark runtime.
Presto provides materialized views for both cases to improve query performance and data mutability. Both setups can spill the in-memory data to temporary storage to overcome memory limitations.
The Presto on Spark set leverages the temporary storage for the shuffle.
Beyond that, a few more things are added, as given below:
The Type store is used for supporting user-defined types
The Function store is used for supporting SQL function authoring and evaluation
The Statistics store is used for better optimization decisions.
Remote functions are built to run user-defined functions.
4. Latency Improvements
4.1 Caching
The disaggregation of storage with computing helped with scaling but created a new challenge.
Scanning large amounts of data or metadata over the wire increases the query latency.
Presto introduced caches at various levels to solve this problem.
Raw Data Cache:
Data cache on local flash devices on workers helps to reduce IO time from remote storage nodes. A Presto worker caches remote data in its original form on local flash upon read. The eviction policy on these caching units is LRU.
Fragment Result Cache:
In the leaf stage, a task pulls data from remote storage. This task can decide to cache the partially computed results on local flash.
A typical approach is to cache the plan fragment results on leaf stages with one level of scan, filter, projection, and/or aggregation.
To maximize the cache hit rate, Presto relies on statistics-based canonicalization.
Metadata Cache and Catalog Servers:
Various metadata-level caches are introduced on coordinators and workers.
Hot data like file indexes are cached in memory.
Mutable metadata like table schemas or file paths is cached with versioning in the coordinators.
The metadata cache can be hosted on catalog servers, which can be a standalone deployment in addition to the coordinator.
Cache locality:
To maximize the cache hit rate on workers, the coordinator needs to schedule the read requests of the same file to the same worker.
To avoid hotspot workers, the scheduler will return to its secondary picked worker for caching or skip the cache when necessary.
4.2 Native vectorized execution
Presto is written in Java, so it cannot leverage modern vectorized CPU execution like SIMD.
Meta created Velox, a general-purpose vectorized execution library in C++. Presto is tightly integrated with Velox. Presto created native C++ workers to communicate directly with the coordinator.
The shuffle and IO are in native Velox formats, so there is no need to transform data into Presto formats.
The coordinator schedules the query plan fragments to C++ workers. The workers receive the plan fragments and translate them into Velox plans. A native thread is spawned to server Velox plans inside the C++ workers to fully leverage the memory fungibility.
Functions, expressions, and IO are executed in a vectorized fashion in an execution thread of Velox.

The diagram above shows the average query latency and CPU time on all TPC-H queries for Java and C++-based Volex.
4.3 Adaptive filtering
Subfield Pruning
Complex types like maps, arrays, and structs are widely used.
A subfield of a complex type instance, denoted as 𝜏, refers to a nested element within 𝜏. For example, if 𝜏 is an array type instance, 𝜏 [2] refers to the second subfield of 𝜏. Subfields can be recursively nested.
For CPU efficiency, extracting the subfields effectively without reading the entire complex object is necessary. Presto supports subfield pruning by signaling to the reader the needed indices or keys of the complex objects.
Filter reordering
Filter pushdown is a common strategy to reduce the scan size. Filtering is done while scanning so that some columns or rows do not have to be materialized.
Some filters are more effective than others; they drop more rows in fewer CPU cycles.
Presto automatically reorders the filters during runtime so that the more selective filters are evaluated before, the less selective ones.
Filter-based lazy materialization
Presto keeps track of the rows that have satisfied the filter predicates while applying a set of filters.
For the rows that have failed the early filters in that batch, there is no need to evaluate or even materialize the rows of the columns that are needed for the other filters in the same batch.
Dynamic join filtering
In Presto, the filter pushdown can be further enhanced for work.
It is called dynamic join filtering.
For an inner join, the build side can provide a “digest” in the format of bloom filters, ranges, or distinct values to serve as a filter for the probe side.
4.4 Materialized views and near real-time data
Data for data warehouse tables is written incrementally in columnar formats ( hourly or daily). The written data becomes immutable after the time increment passes.
Initially, Presto was designed to read only immutable data. Still, recently, it added the capability to read in-flight data ingested into the warehouse to provide near real-time (NRT) support.
This NRT support is available with a tens of seconds delay from when data is created. Presto powers the majority of the dashboards at Meta.
A materialized view is a view represented by a query whose result is stored.
When a materialized view is created by Presto, an automatic job will be created to materialize the data for the view. As long as some units of the base tables become immutable, the automatic job will run the view query to materialize the view data.
One important point is that the continuous incoming NRT data will not be materialized for the view until it becomes immutable.
The materialized view is used in subquery optimization. Presto attempts to match if a materialized view is a subquery of the received one. If there is a match, the received query will be rewritten to leverage the materialized view.

The diagram above shows improvements with materialized views on one of the largest single table.
5. Scalability Improvements
Presto made various improvements and re-architecture to support heavy ETL jobs with hours of runtime and uses Petabyte-size scans.
5.1 Multiple coordinators
The coordinator has been a single point of failure for Presto. A crash of the coordinator means all queries will fail.
Meta infrastructure design is trending toward containers with less memory.
All the query queuing, query scheduling, and cluster management cannot be achieved with smaller memory.
Presto solves this problem by separating the life cycles of queries and clusters.
The coordinators only control the life cycles of queries.
Presto introduced resource managers in charge of a cluster's queueing and resource utilization monitoring.

The diagram above shows the topology of multiple coordinators and resource manager architecture.
A query is first sent to an arbitrary coordinator. It is then optionally sent to the resource managers for queueing.
The resource managers are highly available. The queued queries and cluster control panel information are replicated across all instances.
Consensus protocol like Raft is used to guarantee a crash of a resource manager does not result in any loss of queued queries.
Coordinators periodically fetch the queueing information from the resource managers to decide what queries to execute.
5.2 Recoverable grouped execution
The Presto architecture with streaming RPC shuffle and in-memory data processing is optimized for latency.
This architecture is not good for running ETL queries with PB-size scans.
To support arbitrarily large queries, the team developed recoverable grouped execution.
Data is usually partitioned, and rows with identical partition keys belong to the same partition. The diagram below shows an example of hash partitions, with the table partitioned on column col1.

In Presto, a query can be executed in a “grouped” fashion if the first aggregation, join, or window function key after the table scan is a superset of the data partition key.
The grouped execution can be extended beyond the first shuffle or when the data is not partitioned by the aggregation, join, or window function key. It is done by injecting a shuffle phase to partition the source data based on the downstream keys.

The diagram above shows an example of the recoverable grouped execution for query “SELECT COUNT() FROM table1 GROUP BY col1”.
The table1 contains trillions of distinct values for col1 that cannot fit into the memory of a whole cluster.
5.3 Presto on Spark
There are several mature general-purpose data compute engines that have builtin failure recovery mechanisms with finer granularity.
Spark is one of them.
Spark provides a resilient distributed dataset (RDD), which is a collection of elements partitioned across the cluster's nodes that can be operated on in parallel.
Presto on Spark is a new architecture.
It completely gets rid of the existing Presto cluster topology with multi-tenancy.
It leverages Presto as a library and runs on top of the Spark RDD interface to provide scalability and reliability for no additional cost.

The diagram above shows Presto on Spark architecture, which replaces the Presto’s built-in scheduler, shuffle, resource management, and task execution with Spark.
5.4 Spilling
Presto has the previous two scalable options to overcome the cluster-wide memory limitation. Still, data skew can happen.
Presto implemented spilling to materialize the in-memory hash tables for aggregation, join, window function, and topN operators to disk.
Interactive and ad-hoc workloads spill data to local flash for latency.
ETL workload spills data to remote storage for scalability.
Once the memory limit is hit when building the hash tables for a query, each hash table will be sorted based on the hash key and serialized to disk.
After that, the query will continue processing as if the hash table is empty.
6. Efficiency Improvements
6.1 Cost-Based Optimizer
Presto has a cost-based optimizer that assigns costs to CPU, IO, and memory, balancing these factors to generate an optimized plan.
External information is needed to estimate the cost to make the right decision. Statistics are stored for each table partition to describe the data distribution.
All services that write data are responsible for calculating and publishing the partition statistics to the metadata store.
The common statistics include histogram, total value count, distinct value count, null count, minima, maxima, etc.
The diagram below shows the CPU reduction of a production cluster’s ETL queries with joins after applying the cost-based optimization.

6.2 History-Based Optimizer
Table statistics can provide enough information for plan cost estimation in most cases.
The filter or join selectivity is unknown ahead of time so that the estimation could be increasingly imprecise with more filters embedded in a query.
Presto has support for a history-based optimizer. It is heavily leveraged for ETL jobs.
The idea of the history-based optimizer is to leverage the precise execution statistics from the previously finished repeated queries to guide the planning of future repeated queries.
The previous diagram shows the CPU reduction of the ETL queries of a production cluster.
6.3 Adaptive execution
Presto’s optimizer strives to select the best plan using data statistics statically. incomplete statistics can lead to a plan that is not optimal.
Presto had an adaptive execution that dynamically adjusted the query plan if it was not optimal during runtime.
7. Enabling Richer Analytics
7.1 Handling mutability
Data warehouses historically only support immutable data.
In recent years, there has been an increasing trend to support mutable data with versioning.
Presto built Delta to solve this problem. It allows table mutation with the flexibility of adding or moving columns or rows.
Delta associates one or more “delta files” to a single main file.
The delta files serve as a change log to the main file, indicating whether new columns or rows have been added or removed.
The association and order of the delta files are kept in the metadata store with versioning.
7.2 User-defined types
Presto allows user-defined types.
The user-defined type definitions are stored in the remote metadata store.
User-defined types allow business domain experts to model their data to reflect the user data in the tables and associate the privacy policy with it.
For example, a table owner can define an Email type that should be anonymized immediately when landed and deleted after 7 days.
The warehouse can apply these policies in the background to comply with privacy requirements.
7.3 User-defined functions
User-defined functions (UDFs) allow the embedding of customized logic into SQL.
Presto supports in-process UDFs. These functions are authored and published in the form of libraries.
To support UDF in multi-tenancy mode or in different programming languages, Presto has built UDF servers. The functions are invoked in remote servers with RPCs from Presto clusters.
7.4 Graph extensions
Supporting graph workloads on Presto is challenging for two main reasons:
Expressing graph queries using vanilla SQL means performing graph traversals via joins is not the right approach.
Graph traversal queries are iterative and stateful.
The team extended Presto SQL with graph querying language constructs. Existing graph query languages inspired those.
It helped in providing a declarative interface familiar to SQL users.
The Presto team also built a graph query planner.
8. Related Work
Google BigQuery powered by Google Dremel offers an interactive and ad-hoc analytical engine.
Snowflake and Redshift also provide similar capabilities. Procella is another Google internal tool with similar capabilities.
SparkSQL is a popular open-source engine supporting long-running ETL jobs.
Vectorized engines are an industry trend that boosts query performance. Notable ones are DuckDB, Photon, and ClickHouse.
Various open-source solutions, including Delta Lake, Iceberg, and Hudi support mutability, versioning, and time traveling.
9. Future Work
Following is the list of some of the remaining challenges for the Presto team:
Non-SQL API
Distributed Caching
Unified Container Scheduling
Unified UDFs
10. Conclusions
Presto has continued to evolve to handle fast-growing data volumes. Latency for interactive workloads and scalability for ETL workloads are improving.
The team has successfully consolidated data warehouse design by centralizing the traditional ETL workload (previously handled by SparkSQL), ad-hoc analysis (previously managed by Presto), interactive serving (previously handled by Raptor or Cubrick), and graph processing (previously handled by Giraph) on Presto.
References
Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
Presto Unlimited: MPP SQL Engine at Scale
Amazon Neptune: Graph Data Management in the Cloud
Photon: A Fast Query Engine for Lakehouse Systems
Shared Foundations: Modernizing Meta’s Data Lakehouse
One Trillion Edges: Graph Processing at Facebook-Scale
The Snowflake Elastic Data Warehouse
Cubrick: Indexing Millions of Records per Second for Interactive Analytics