
Insights from Paper - Scaling Memcache at Facebook

1. Introduction
Before we start, I want to say that I will use Facebook, not Meta, as the organization's name to be consistent with the paper.
Memcached is a famous in-memory caching solution.
Facebook leverages memcached as a building block to construct and scale a distributed key-value store.
The store handles billions of requests per second and holds trillions of items.
Facebook is one of the largest social networking sites. In general, a social network’s infrastructure needs the following things:
Allow near real-time communication
Aggregate content on the fly from multiple sources
Be able to access and update very popular shared content
Scale to process millions of user requests per second.
The paper describes how Facebook improved and used the open-source version of Memcached to build the massive distributed key-value store.
Let’s start with Memcached. It is an open-source implementation of an in-memory hash table. It provides low-latency access to a shared storage pool at a low cost.
Some qualities require more effort to achieve at specific scale sizes than others. For example, maintaining data consistency can be more accessible at small scales if replication is minimal, but it is very difficult on a massive scale.
The paper has the following four main contributions:
The evolution of Facebook’s Memcached-based architecture.
Enhancements to memcached that improve performance and increase memory efficiency.
Mechanisms that improved the ability to operate the system at the Facebook scale.
Characterize the production workloads imposed on the Facebook system.
2. Overview
Let’s start with the critical properties of the Facebook system that drive the design.
Users consume an order of magnitude more content than they create.
Read operations fetch data from various sources, such as MySQL databases, HDFS installations, and backend services.
You would have guessed correctly that caching can provide significant advantages. In addition, different caching strategies are needed to store data from disparate sources.
Memcached provides get, set, and delete operations. The team started with a single machine in-memory hash table.
The paper highlights the usage of words. The ‘memcached’ refers to the source code or a running binary, and the ‘memcache’ describes the distributed system.
Let’s start diving deep into caching.
Query cache:
Facebook uses memcache as a demand-filled look-aside cache.
When a web server needs data (read request), it provides a string key and looks for the value corresponding to the key from memcache.
If the key is not cached in the memcache, the web server retrieves the value for the key from the source ( let’s say, a database for simplicity).
The retrieved data is populated in the memcache.
When a web server needs to put data (write request), it issues SQL statements to the database and then sends a delete request to memcache that invalidates any stale data.
These steps are shown in the diagram below:

The left half of the diagram shows the read path for a web server on a cache miss. The right half of the diagram shows the write path for a key-value pair.
You may be thinking about why Facebook chose to delete cached data instead of updating it.
The answer is that delete is idempotent. If a request comes more than once, only the first request will delete the data, and the other requests will not have any effect.
It is suitable for maintaining the cache. We will see that in later sections.
Generic cache:
Facebook uses memcache as a more general key-value store. It is used to store pre-computed results from sophisticated machine-learning algorithms.
Memcached provides no server-to-server coordination.
Facebook added functionality to provide configuration, aggregation, and routing services to organize memcached instances into a distributed system.
The paper is structured to handle three different levels of deployment scales. Those are followings:
Facebook started with one cluster of servers. Read heavy workloads and wide fan-out were the primary concerns.
The next level of scale was multiple front-end clusters. At this level, the primary concern was handling data replication between these clusters.
The last level has clusters spread around the world to provide a consistent user experience. At this level, operational complexity and fault tolerance were the primary concerns.
The diagram below shows the final architecture. The system is organized in co-located clusters in a region. A master region provides a data stream to keep non-master regions up-to-date.

3. In a Cluster: Latency and Load
Let’s start with the challenges of scaling to thousands of servers within a cluster.
3.1 Reducing Latency
The latency of memcache’s response is a critical factor in the response time of a user’s request. The request may have been serve by cache hit or cache miss.
A single-user web request can often result in hundreds of individual memcache requests.
The team provisions hundreds of memcached servers in a cluster to reduce the database load.
Items are distributed across the memcached servers through consistent hashing.
It simply means web servers must communicate with many memcached servers to serve a user request.
This all-to-all communication pattern causes incast congestion or allows a single memcached server to become the bottleneck for many web servers.
The team mainly reduced latency by focusing on the memcache client on web servers.
Parallel requests and batching - The web application code is structured to minimize the number of network calls required to respond to page requests.
The team constructed a directed acyclic graph (DAG) representing the dependencies between data. A web server uses this DAG to maximize the number of items that can be fetched concurrently.
Client-server communication - The client logic is provided as two components. One component is a library that can be embedded into applications or as a standalone proxy named mcrouter. This proxy has a memcached server interface and routes the requests/replies to/from other servers.
Clients use UDP and TCP to communicate with memcached servers. It relies on UDP to get requests to reduce latency and overhead. Each thread in the web server is allowed to communicate with memcached servers directly, bypassing mcrouter directly.
The UDP implementation detects packets that are dropped or received out of order and treats them as errors on the client side. Clients treat GET errors as cache misses.
Incast congestion - Memcache clients implement flow control mechanisms to limit incast congestion. Clients use a sliding window mechanism to control the number of outstanding requests.
User requests exhibit a Poisson arrival process at each web server. According to Little’s Law, L = λW, the number of requests queued in the server (L) is directly proportional to the average time a request takes to process (W), assuming that the input request rate is constant.
3.2 Reducing Load
Leases
The team introduced a new mechanism called leases to address two problems: stale sets and thundering herds.
A stale set occurs when a web server sets a value in memcache that is not latest. This happens when concurrent updates to memcache get reordered.
A thundering herd happens when a specific key undergoes heavy read-and-write activity.
A memcached instance gives a lease to a client to set data back into the cache when that client experiences a cache miss. The client provides the lease token when setting the value in the cache. With the lease token, memcached can verify and determine whether the data should be stored.
Each memcached server regulates the rate at which it returns tokens to mitigate thundering herds. The team configured servers to return a token only once every 10 seconds per key.
Memcache Pools
Considering the system is a general cache, different access patterns, memory footprints, and quality-of-service are required.
The team partitions a cluster’s memcached servers into separate pools to support this.
There is a default wildcard pool.
There is a small pool for keys that are accessed frequently but for which a cache miss is inexpensive.
Similarly, there is a large pool of infrequently accessed keys for which cache misses are prohibitively expensive.
Replication Within Pools
There is replication within some pools to improve the latency and efficiency of memcached servers.
The criteria for replication are:
The application routinely fetches many keys simultaneously
The entire data set fits in one or two memcached servers.
The request rate is much higher than what a single server can manage.
3.3 Handling Failures
If data is not fetched from memcache, it results in excessive load to backend services that could cause further cascading failures.
There are two specific case to take care.
A few hosts are inaccessible due to a network or server failure.
A widespread outage has affected a significant percentage of the servers within the cluster.
There is an automated remediation system for small outages. It is not instant and can take up to a few minutes.
To avoid cascading failure during this time, a small set of machines named Gutter takes over the responsibilities of a few failed servers.
Gutter accounts for approximately 1% of the memcached servers in a cluster.
When a memcached client receives no response to its get request, the client assumes the server has failed and issues the request again to a special Gutter pool.
If this second request misses, the client will insert the appropriate key-value pair into the Gutter machine after querying the database.
Entries in Gutter expire quickly.
If an entire cluster has to be taken offline, the team diverts user web requests to other clusters, effectively removing all the load from the memcache within that cluster.
4. In a Region: Replication
Adding more web and memcached servers to scale a cluster as demand increases seems logical, but problems are associated with this.
The Facebook team planned to split their web and memcached servers into multiple frontend clusters.
The Frontend cluster and a storage cluster containing databases are called a region.
This section will cover the impact of multiple front-end clusters that share the same storage cluster.
Regional Invalidations
The storage cluster in a region holds the authoritative copy of data. It is responsible for invalidating cached data to keep frontend clusters consistent.
A web server that modifies data also sends invalidations to its own cluster to provide read-after-write semantics for a single user request and reduce the amount of time stale data is present in its local cache.
SQL statements that modify the authoritative state have memcache keys that must be invalidated once the transaction commits.
A daemon named mcsqueal is deployed on every database. It does all invalidations. The daemon inspects the SQL statements, extracts any deletes, and broadcasts these deletes to the memcache deployment in every frontend cluster in that region.
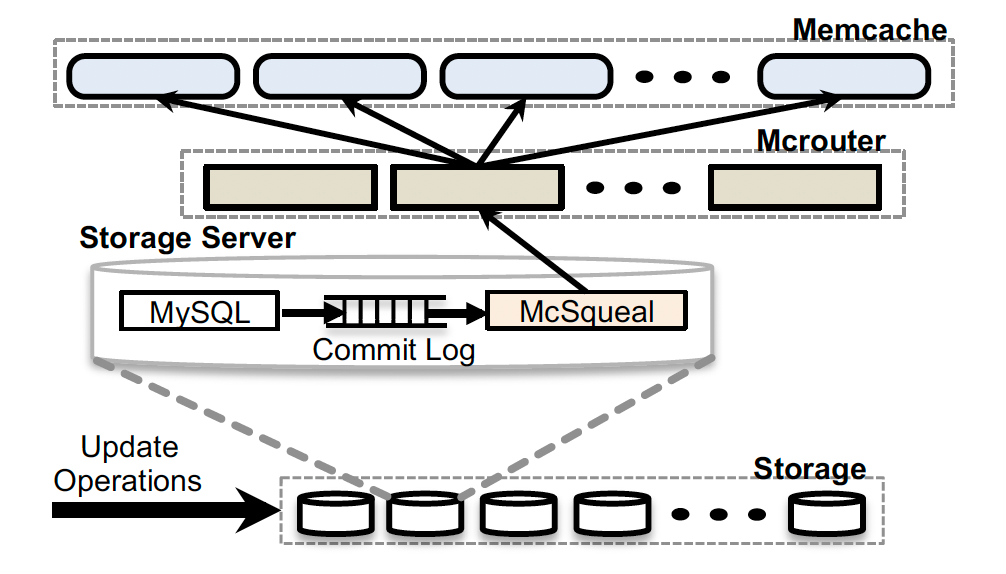
The diagram above shows the invalidation pipeline.
Reducing packet rates:
If mcsqueal is allowed to contact memcached servers directly, there will be an unacceptably high packet transmission rate.
To fix this problem, the daemon batch deletes into fewer packets and sends them to a set of dedicated servers running mcrouter instances in each frontend cluster.
These mcrouters then unpack individual deletes from each batch and route those invalidations to the correct memcached server co-located within the frontend cluster.
Invalidation via web servers:
One approach could be broadcasting invalidations to all front-end clusters from a web server. It has two issues.
There will be more packet overhead as web servers are less effective at batching invalidations.
There is little recourse when a systemic invalidation problem arises, such as
misrouting of deletes due to a configuration error.
Regional Pools
Each cluster independently caches data for user requests.
If users’ requests are randomly routed to all available frontend clusters, then the cached data will be roughly the same across all the frontend clusters.
It helps to take a cluster offline for maintenance without suffering from reduced hit rates. On the other hand, over-replicating the data can be memory inefficient.
Multiple frontend clusters sharing the same set of memcached servers, a regional pool, can reduce the number of replicas.
Remember that before this, we have been talking about the frontend cluster as a combination of dedicated web servers and Memcached servers.
Cold Cluster Warmup
If an existing cluster fails or performs scheduled maintenance, the caches will have very poor hit rates.
To fix this, the team created a concept of “cold cluster” and “warm cluster.” Clients in the “cold cluster” can retrieve data from the “warm cluster.”
It avoids hits on the persistent storage.
Data replication across frontend clusters helps with this. This system can bring cold clusters back to total capacity in a few hours instead of a few days.
There are race conditions to avoid here. Let’s take an example.
A client in the cold cluster does a database update. Another client's request retrieves the stale value from the warm cluster before the warm cluster has received the invalidation from the first request. Now, this item will be indefinitely inconsistent in the cold cluster.
All deletes to the cold cluster are issued with a two-second hold-off by default to fix this.
When a miss is detected in the cold cluster, the client re-requests the key from the warm cluster and adds it to the cold cluster.
5. Across Regions: Consistency
The team designated one region to hold the master databases and the other regions to contain read-only replicas. The team relies on MySQL’s replication mechanism to keep replica databases up-to-date with their masters.
This gives low latency when accessing either the local memcached servers or the local database replicas.
The challenge is maintaining consistency between data in memcache and persistent storage.
Here, the team provides best-effort eventual consistency but places an emphasis on performance and availability.
Writes from a master region:
Using daemons for invalidations avoids a race condition in which an invalidation arrives before the data has been replicated from the master region.
Historically, the team implemented mcsqueal after scaling to multiple regions.
Writes from a non-master region:
Let’s assume a user updates his data from a non-master region when the replication lag is considerable. The user’s next request could be confused if his recent change is missing.
A cache refill from a replica’s database should only be allowed after the replication stream has caught up.
The team employs a remote marker mechanism to minimize the probability of reading stale data. The marker indicates that data in the local replica database are potentially stale, and the query should be redirected to the master region.
6. Single Server Improvements
In this section, we will discuss performance optimizations and memory efficiency gains in Memcached, which allow better scaling within clusters.
Performance Optimizations
The team made the following major optimizations:
Allow automatic expansion of the hash table.
Make the server multi-threaded using a global lock to protect multiple
data structures.
Give each thread its own UDP port to reduce contention
The first two optimizations are open-sourced.
Adaptive Slab Allocator
A slab allocator manages memory. The allocator organizes memory into slab classes, each containing pre-allocated, uniformly sized chunks.
Memcached stores items in the smallest possible slab class.
Each slab class maintains a free list of available chunks and requests more memory in 1MB slabs when its free list is empty.
When a server can no longer allocate free memory, new items are stored by evicting the least recently used (LRU) item within that slab class.
The Transient Item Cache
Memcached lazily evicts entries by checking expiration times when serving a get request for that item or when they reach the end of the LRU.
The team has a hybrid scheme that relies on lazy eviction for most keys and proactively evicts shortlived keys when they expire.
The short-lived items are placed into a circular buffer of linked lists (indexed by seconds until expiration). It is called the Transient Item Cache.
Every second, all of the items in the bucket at the head of the buffer are evicted, and the head advances by one.
Software Upgrades
The team modified memcached to store its cached values and main data structures in System V shared memory regions so that the data can remain live across a software upgrade and thereby minimize disruption.
7. Related Work
Many other large websites have recognized the utility of key-value stores.
Amazon uses Dynamo. My post, which is given in references, discusses it.
LinkedIn uses Voldemort.
Github has deployed the key-value caching solution Redis.
Apache Cassandra is also used as a distributed key store. You can read about it in my post.
8. Conclusion
The paper shows how to scale a memcached-based architecture to meet the growing demand of Facebook.
The team has learned the following lessons.
Separating cache and persistent storage systems allows them to scale independently.
Features that improve monitoring, debugging, and operational efficiency are as important as performance.
Managing stateful components is operationally more complex than stateless ones.
The system must support the gradual rollout and rollback of new features.
Simplicity is vital.
References
Original paper: https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf