
Insights from paper - Storm @Twitter

Abstract
Storm is a real-time fault-tolerant and distributed stream data processing system.
Nathan Marz initially created Storm at BackType, and Twitter acquired BackType in 2011.
At the time of paper writing, Storm was used to run various critical computations at scale and in real-time inside Twitter (Now X).
This paper covers the architecture of Storm and its methods for distributed scale-out and fault tolerance. It also covers query execution and operational work.
As of now, it is Apache Storm.
Introduction
At Twitter, several complex decisions are made based on data for each interaction with a user. Strom powers these real-time stream data management tasks.
The design goals for Storm are as below:
Scalable: Adding or removing nodes from the Storm cluster should be easy.
Resilient: The Storm cluster must continue processing current work with a minimal performance impact.
Extensible: Storm needs an extensible framework as It can add calls to arbitrary external functions.
Efficient: It must have good performance characteristics for real-time applications.
Easy to Administer: Easy-to-use administration tools are a critical requirement for operations.
Storm has borrowed ideas from previous work on stream processing systems like The Design of the Borealis Stream Processing Engine and The Design of the Borealis Stream Processing Engine.
The idea was to fulfill all the design goals in a single system. Other SPEs include S4, MillWheel, Samza, Spark Streaming, and Photon.
Storm team does not claim that they invented the concepts like extensibility, scalability, and resilience for streaming systems. Still, Storm represents one of the early open-source and popular stream processing systems today.
At Twitter, Storm is improved in several ways. It includes scaling to many nodes and reducing the dependency on Zookeeper. Twitter open-sourced Storm in 2012.
The move to YARN kindled an interest in integrating Storm with the Hadoop ecosystem.
Data Model and Execution Architecture
Storm started with a simple idea of representing a stream inside a single program as a single abstraction. It gave birth to a topology (a directed graph) model. The stream is a single graph where vertices represent computation and edges represent the data flow between them.
In summary, Storm data processing architecture consists of streams of tuples flowing through topologies.
The vertices in the graph can be of two types — Spouts and Bolts.
Spouts are the tuple sources for the topology.
Bolts process the incoming tuples and pass them to the next set of bolts downstream.
Spouts and bolts are inherently parallel. They are similar to how mappers and reducers are inherently parallel. Also, Storm abstracts out the complexities of sending/receiving messages, serialization, deployment, etc, as Map Reduce did for data-parallel jobs. That is why Storm is sometimes called “the Hadoop of real-time.”
The diagram below shows a simple topology for counting the words occurring in a stream of Tweets and produces these counts every 5 minutes.
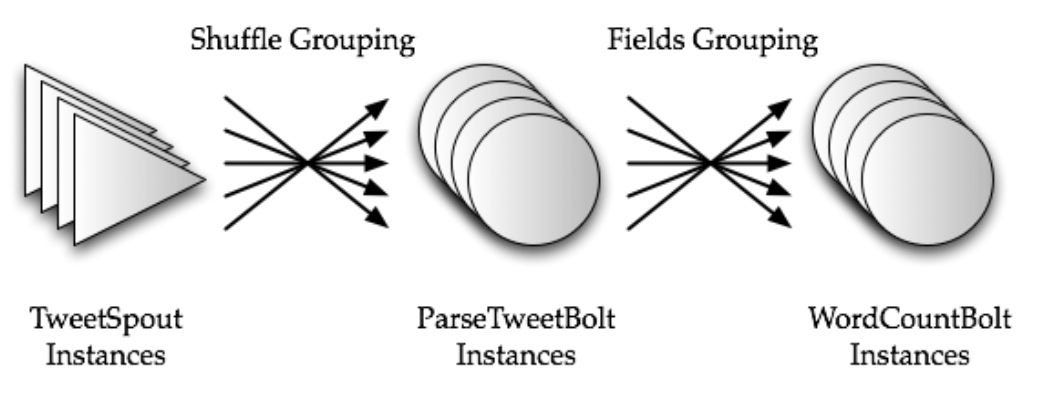
The topology has one spout TweetSpout, and two bolts ParseTweetBolt and WordCountBolt.
The TweetSpout can pull data from the source (maybe via API calls). The ParseTweetBolt breaks the Tweets into words and emits 2-ary tuples (word, count), one for each word. The WordCountBolt works on this input and aggregates the counts for each word.
Storm Overview
Storm runs on a distributed cluster. So there can be YARN or Mesos running on the cluster for management.
At Twitter, Storm runs on Mesos.
The clients submit topologies to a master node called Nimbus. Nimbus is responsible for distributing and coordinating the execution of the topology.
The actual work is done on worker nodes. Each worker node runs one or more worker processes. Each worker process is mapped to a single topology.
Each worker process runs its own JVM. There one or more executors are running. Executors are made of one or more tasks. The work for a bolt or a spout is executed inside the task.
Each worker node runs a Supervisor, which communicates with Nimbus.
Storm supports the following types of partitioning strategies:
1. Shuffle grouping: It randomly partitions the tuples.
2. Fields grouping: It hashes on a subset of the tuple attributes/fields.
3. All grouping: It replicates the entire stream to all the consumer tasks.
4. Global grouping: It sends the entire stream to a single bolt.
5. Local grouping: It sends tuples to the consumer bolts in the same executor.
The cluster state is maintained in Zookeeper.
Nimbus is responsible for scheduling the topologies on the worker nodes and monitoring the progress of the tuples flowing through the topology.
Storm Internals
Let’s discuss in detail the critical components of Storm shown in the below diagram.
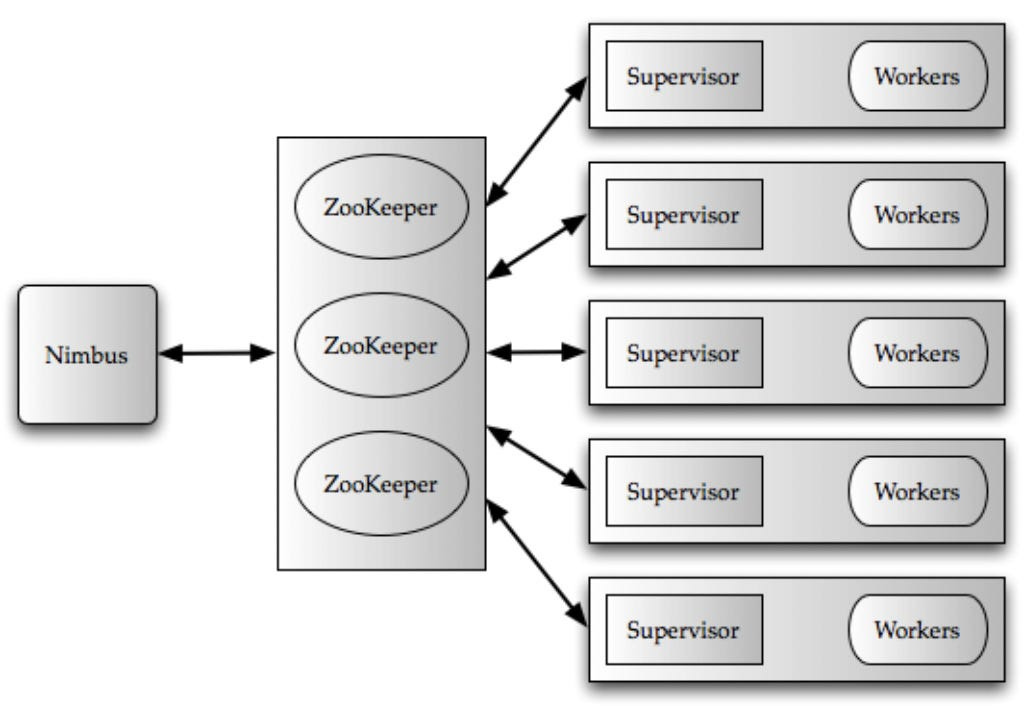
Nimbus and Zookeeper
Nimbus is the interface to interact with the Storm system.
It is like the JobTracker in Hadoop System.
One good thing about Nimbus is that it is an Apache Thrift service. The user has to define the topology as a Thrift object and sends it to Nimbus. So you can use any programming language to create those objects.
As part of submitting the topology, the user also uploads the user code as a JAR file to Nimbus.
The supervisors advertised the current running topologies to Nimbus. Nimbus takes care of the assignment of pending topologies to the Supervisors.
The coordination between Nimbus and supervisors is done by Zookeeper. All the state of Nimbus and supervisors is stored at Zookeeper so these components are fail-fast.
If Nimbus fails, the workers can continue. The only problem, in this case, is that the re-assignment will not occur if any worker fails. The team has a plan to fix that in future versions.
Supervisors restart the workers if they fail.
Supervisor
The supervisor runs on each worker node. Nimbus sends the work assignment.
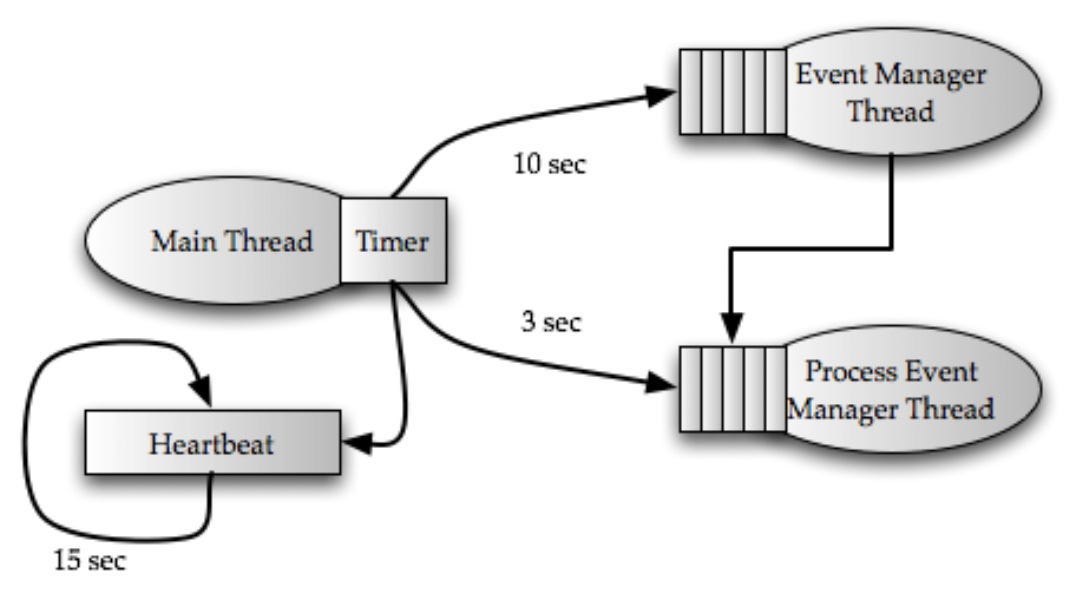
The above diagram shows the high-level architecture of the supervisor. The Supervisor spawns three threads.
There are following three types of events:
Heartbeat event: It is scheduled to run every 15 seconds. It reports to Nimbus that the supervisor is alive.
Synchronize supervisor event: It is executed every 10 seconds in the event manager thread. This thread is responsible for managing the changes in the existing assignments.
Synchronize process event: It runs every 3 seconds in the process event manager thread. This thread is responsible for managing worker processes that run a part of the topology on the same node as the supervisor.
Workers and Executors
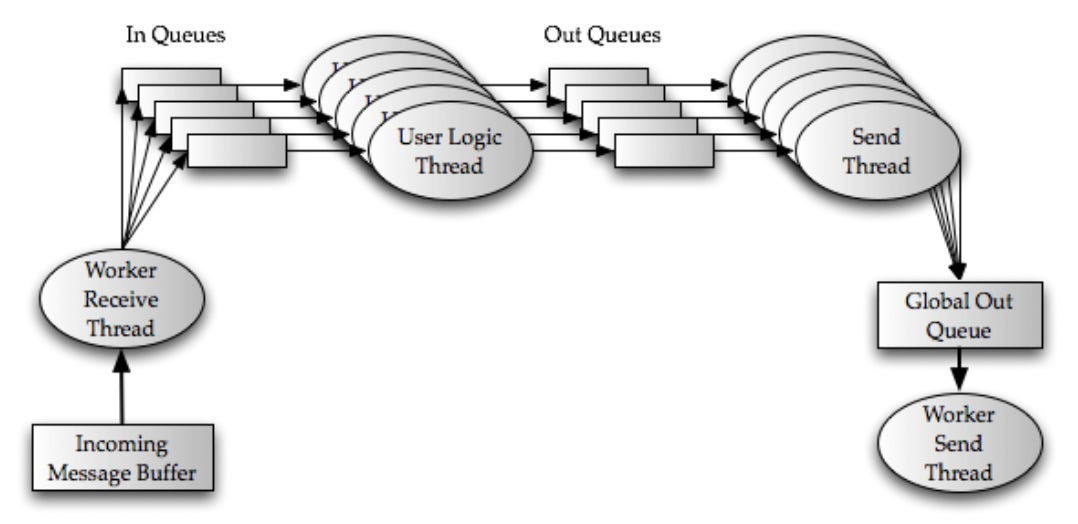
Each worker process runs several executors inside a JVM. These executors are threads within the worker process. Each executor can run several tasks. A task is an instance of a spout or a bolt.
Each worker process has two dedicated threads — a worker receive thread and a worker send thread.
Each executor process has two dedicated threads — a user logic thread and an executor send thread.
The user logic thread takes incoming tuples from the in queue, examines the destination task identifier, and then runs the actual task. These outgoing tuples are then placed in an out queue associated with this executor.
The executor send thread takes these tuples from the out queue and puts them in a global transfer queue.
The worker send thread reads from the global transfer queue, and based on its task destination identifier, it sends it to the next worker downstream.
All this process is shown in the below diagram:
Processing Semantics
The best thing about Storm is its ability to provide guarantees about the data that it processes.
It provides two types of semantic guarantees — “at least once,” and “at most once” semantics.
To provide “at least once” semantics, the topology is augmented with an “acker” bolt that tracks the directed acyclic graph of tuples for every tuple that is emitted by a spout.
See the below diagram for our Tweet count example:
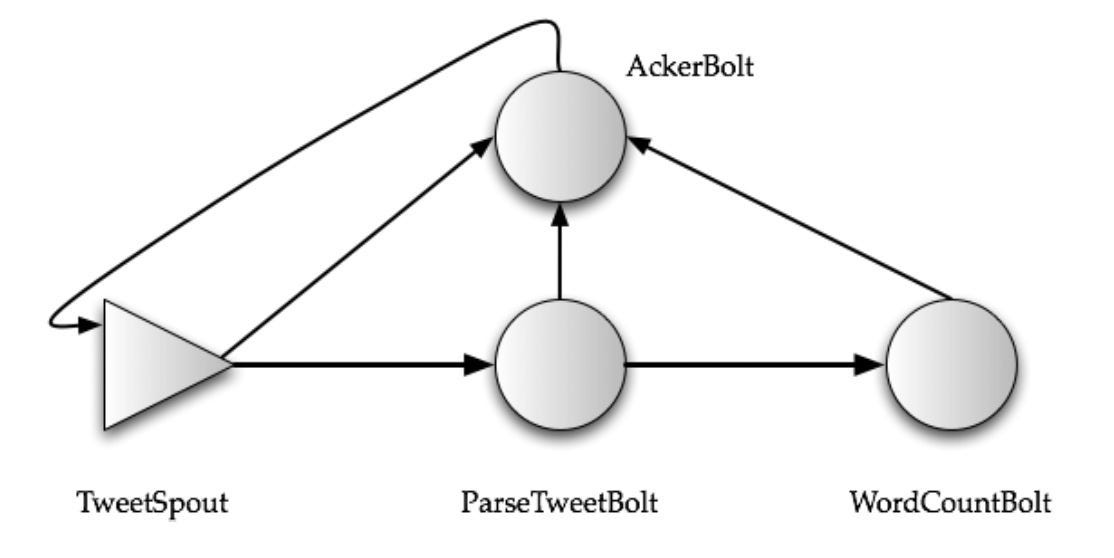
For at least once semantics, the data source must “hold” a tuple.
If the spout received a positive ack for a tuple, it can tell the data source to remove it.
If an ack or fail message does not arrive within a specified time, then the data source will expire the “hold” on the tuple and replay it in the subsequent iteration.
Storm in use @ Twitter
Let’s discuss briefly how Storm is used at Twitter.
Operational overview
Storm runs on hundreds of servers across multiple data centers at Twitter. Several hundreds of topologies run on these clusters.
Terabytes of data flow through the Storm clusters every day. It generates several billions of output tuples.
A number of groups like revenue, user services, search, and content discovery use Storm topologies.
The p99 latency for processing a tuple is close to 1 ms. Cluster availability was 99.9% for the last six months measured.
Storm Visualization Operations
Each topology is augmented with a metrics bolt. All the metrics collected at each spout or bolt are sent to this bolt.
These logs are fed to a rich visualization developed in-house.
The metrics can be broadly classified into system metrics and topology metrics.
Spout metrics include the number of tuples emitted per minute, tuple acks, fail messages per minute, and latency for processing an entire tuple in the topology.
The bolt metrics include the number of tuples executed, the acks per minute, the average tuple processing latency, and the average latency to ack a specific tuple.
I am leaving the operational stories and empirical evaluation section as they only discuss facts and figures.
Conclusions and Future Work
At Twitter, Storm is one of the critical infrastructures. It powers many real-time data-driven decisions.
The usage is expanding rapidly and raises a number of potentially exciting directions for future work. It includes the following:
Automatically optimizing the topology statically
Re-optimizing the topology dynamically at runtime
Adding exactly-once semantics
Better integration of Storm with Hadoop
References
The original paper: https://cs.brown.edu/courses/csci2270/archives/2015/papers/ss-storm.pdf
STREAM: The Stanford Stream Data Manager: Arvind Arasu, Brian Babcock, Shivnath Babu, Mayur Datar, Keith Ito, Rajeev Motwani, Itaru Nishizawa, Utkarsh Srivastava, Dilys Thomas, Rohit Varma, Jennifer Widom.IEEE Data Eng. Bull. 26(1): 19–26 (2003)
Retrospective on Aurora: Hari Balakrishnan, Magdalena Balazinska, Donald Carney, Ugur Çetintemel, Mitch Cherniack, Christian Convey, Eduardo F. Galvez, Jon Salz, Michael Stonebraker, Nesime Tatbul, Richard Tibbetts, Stanley B. Zdonik: VLDB J. 13(4): 370–383 (2004)
Querying and Mining Data Streams: Minos N. Garofalakis, Johannes Gehrke: You Only Get One Look. VLDB 2002
The Design of the Borealis Stream Processing Engine: Daniel J. Abadi, Yanif Ahmad, Magdalena Balazinska, Ugur Çetintemel, Mitch Cherniack, Jeong-Hyon Hwang, Wolfgang Lindner, Anurag Maskey, Alex Rasin, Esther Ryvkina, Nesime Tatbul, Ying Xing, Stanley B. Zdonik: CIDR 2005: 277- 289
Apache Samza.
http://samza.incubator.apache.org
Spark Streaming: http://spark.incubator.apache.org/docs/latest/streamingprogramming-* guide.html
Kestrel: A simple, distributed message queue system: http://robey.github.com/kestrel
Apache Zookeeper:
http://zookeeper.apache.org/
Storm, Stream Data Processing: http://hortonworks.com/labs/storm/
Apache Storm: http://hortonworks.com/hadoop/storm/
Nathan Marz: Trident API Overview: https://github.com/nathanmarz/storm/wiki/Trident-APIOverview