
Insights from paper - The Google File System

Introduction
The Google File System is a scalable distributed file system for large distributed data-intensive applications. It provides fault tolerance and high aggregate performance.
Google designed and implemented the Google File System (GFS) to meet the rapidly growing demands of Google’s data processing needs. Google has explored some radically different points in the design space.
Component failures are the norm rather than the exception.
Files are huge by traditional standards. Multi-GB files are common.
Most files are mutated by appending new data rather than overwriting existing data.
Co-designing the applications and the file system API benefits the overall system.
Google also introduced atomic append operation so multiple clients can append concurrently to a file without extra synchronization.
Design Overview
Assumptions
The system is built from many inexpensive commodity components that often fail.
The system stores a modest number of large files.
The workloads primarily consist of two kinds of reads: large streaming reads and small random reads.
The workloads also have many large, sequential writes that append data to files.
The system must efficiently implement well-defined semantics for multiple clients that concurrently append to the same file.
High sustained bandwidth is more important than low latency.
Interface
GFS supports the usual operations to create, delete, open, close, read, and write files.
It has two more operations listed below:
Snapshot- Snapshot creates a copy of a file or a directory tree at a low cost.
Record append - It allows multiple clients to append data to the same file concurrently while guaranteeing the atomicity of each client’s append.
We will discuss these two operations in detail in later sections.
Architecture
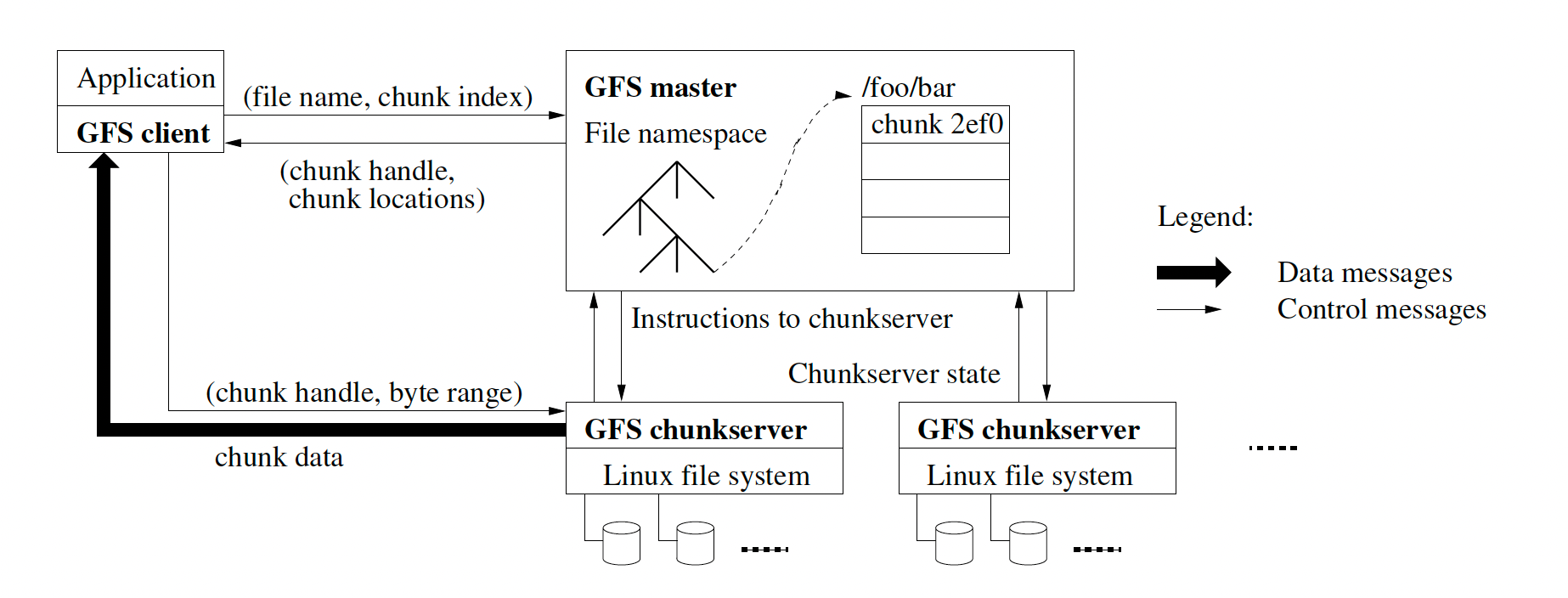
A GFS cluster consists of a single master and multiple chunk servers.
Files are divided into fixed-size chunks. Each chunk is identified by an immutable and globally unique 64-bit chunk handle assigned by the master at the time of chunk creation.
For reliability, each chunk is replicated on multiple chunk servers. By default, GFS stores three replicas, though users can designate different replication levels for different regions of the file namespace.
The master maintains all file system metadata.
Clients interact with the master for metadata operations, but all data-bearing communication goes directly to the chunk servers.
The client implements the file system API and communicates with the master and chunk servers to read or write.
Neither the client nor the chunk server caches file data.
Single Master
Single master simplifies the design and enables the master to make sophisticated chunk placement and replication decisions using global knowledge.
Clients never read and write file data through the master.
Read operation has the following steps:
The client translates the file name and byte offset into a chunk index within the file.
The client sends the file name and chunk index to master
The master replies with the corresponding chunk handle and locations of the replicas.
The client caches this information using the file name and chunk index as the key.
The client then sends a request to one of the replicas, most likely the closest one.
Chunk Size
Chunk size is one of the key design parameters. GFS has chosen 64 MB. It is much larger than a typical file system block size. There are a lot of advantages of this large chunk size.
It reduces clients’ need to interact with the master.
The client can reduce network overhead by keeping a persistent TCP connection.
It reduces the size of the metadata stored on the master.
Metadata
The master stores three significant types of metadata:
The file and chunk namespaces
The mapping from files to chunks
The locations of each chunk’s replicas
All metadata is kept in the master’s memory. The first two types are also kept persistent by logging mutations to an operation log stored on the master’s local disk and replicated on remote machines.
In-Memory Data Structures
There are advantages of storing all metadata in the master server’s memory.
It is easy and efficient for the master to scan through its entire state in the background periodically. It helps to implement chunk garbage collection, re-replication in the presence of chunk server failures, and chunk migration to balance the load and disk space usage across chunk servers.
The master maintains less than 64 bytes of metadata for each 64 MB chunk. The file namespace data typically requires less than 64 bytes per file.
In the worst case, adding extra memory to the master is a small price to pay for the simplicity, reliability, performance, and flexibility we gain by storing the metadata in memory.
Chunk Locations
The master does not keep a persistent record of which chunk servers have a replica of a given chunk.
Master polls chunk servers for that information at startup.
The master keeps itself up-to-date thereafter because it controls all chunk placement and monitors chunk server status with regular HeartBeat messages.
This design eliminated the problem of keeping the master and chunk servers in sync as chunk servers join and leave the cluster, change names, fail, restart, and so on.
Operation Log
The operation log contains a historical record of critical metadata changes. It is the only persistent record of metadata.
Files, chunks, and their versions are all uniquely and eternally identified by the logical times they were created. This way, the master defines the order of concurrent operations.
The master replicates this metadata on multiple remote machines and responds to a client operation only after flushing the corresponding log record to disk both locally and remotely.
The master recovers its file system state by replaying the operation log. To minimize startup time, the master checkpoints its state whenever the log grows beyond a certain size so that it can recover by loading the latest checkpoint from the local disk and replaying only the limited number of log records after that.
Consistency Model
GFS has a relaxed consistency model. Let’s understand the guarantees it provides and what they mean to applications.
Guarantees by GFS
File namespace mutations (e.g., file creation) are atomic and handled by the master exclusively.
Before we discuss the next part, let’s define the mutation.
A mutation is an operation that changes the contents or metadata of a chunk, such as a write or an append operation.
A file region mutation can succeed or fail and can be done by serial or concurrent access. On top of it, this change can be write or append.
Based on the above three dimensions, the file region can be consistent or inconsistent. It can also be in a defined or undefined state.
The below table summarizes the effects.

Implications for Applications
The applications using GFS can accommodate the relaxed consistency model with a few simple techniques. These techniques are not new and are used for other purposes also. These are the followings:
Rely on appends rather than overwrites
checkpoint the mutation
Writing self-validating and self-identifying records
System Interactions
The system is designed to minimize the master’s involvement in all operations.
Let’s understand how client, master, and chunk servers interact to implement data changes, atomic record append, and snapshot.
Leases and Mutation Order
Each mutation is performed at all the chunk replicas. GFS uses leases to maintain a consistent mutation order across replicas.
The master grants a chunk lease to one of the replicas, which is called the primary. The primary pick a serial order for all mutations to the chunk. All replicas follow this order.
A lease has an initial timeout of 60 seconds. Primary can request and typically receive extensions from the master indefinitely. If the master loses communication with a primary, it can safely grant a new lease to another replica after the old lease expires.
Now let’s understand the control flow of a write. See the diagram below for clarity.
The client asks the master which chunk server holds the current lease for the chunk and the locations of the other replicas. If no one has a lease, the master grants one to a replica it chooses.
The master replies with the identity of the primary and the locations of the other (secondary) replicas. The client caches this data for future mutations.
The client pushes the data to all the replicas. Each chunk server will store the data in an internal LRU buffer cache until the data is used or aged out.
Once all the replicas have acknowledged receiving the data, the client sends a write request to the primary. The primary assigns consecutive serial numbers to all the mutations it receives, possibly from multiple clients, which provides the necessary serialization. It applies the mutation to its local state in serial number order.
The primary forwards the write request to all secondary replicas. Each secondary replica applies mutations in the same serial number order assigned by the primary.
The secondaries all reply to the primary, indicating that they have completed the operation.
The primary replies to the client. Any errors encountered at any of the replicas are reported to the client.
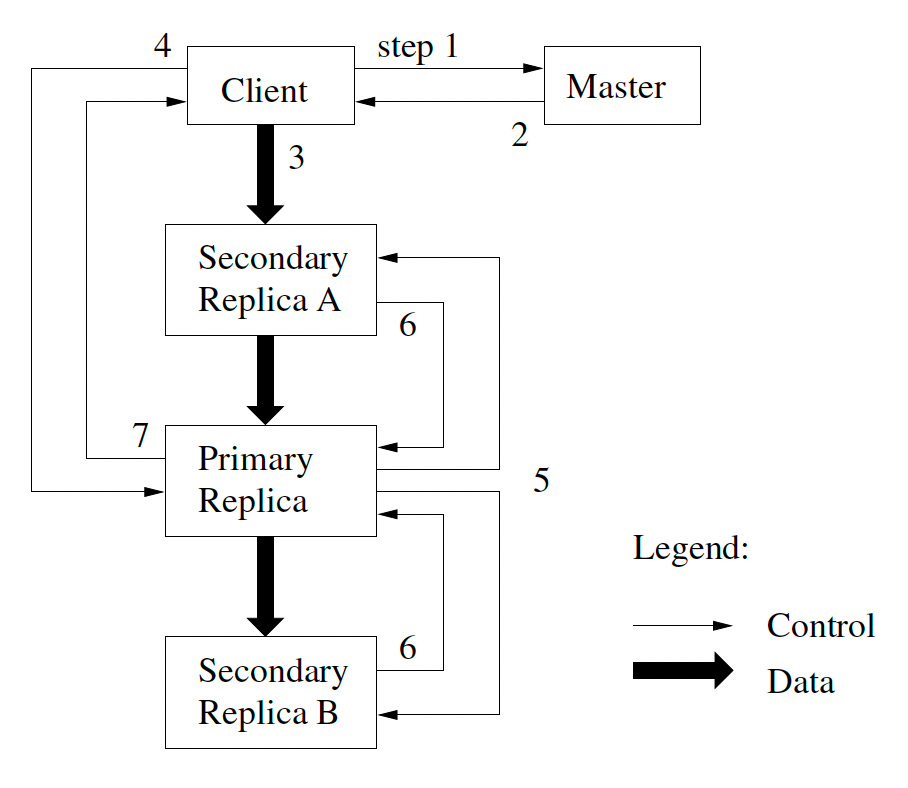
In case of errors, the write may have succeeded at the primary and an arbitrary subset of the secondary replicas. The client request is considered to have failed, and the modified region is left in an inconsistent state. Our client code handles such errors by retrying the failed mutation. It will make a few attempts at steps (3) through (7) before falling back to a retry from the beginning of the write.
Data Flow
in GFS, data flow is completely decoupled from the control flow. Control flows from the client to the primary and then to all secondaries.
Data is pushed linearly along a carefully picked chain of chunk servers in a pipelined fashion. Data is not distributed in some topology, so the machine’s full outbound bandwidth is used for data transfer.
To avoid network bottlenecks and high-latency links as much as possible, each machine forwards the data to the “closest” machine.
Finally, GFS minimizes latency by pipelining the data transfer over TCP connections. Once a chunk server receives some data, it starts forwarding immediately.
GFS network links are typically 100 Mbps. 1 MB can ideally be distributed in about 80 ms.
Atomic Record Appends
GFS provides an atomic append operation called record append. In a record append, the client specifies only the data.
GFS appends the data to the file at least once atomically (i.e., as one continuous sequence of bytes) at an offset of GFS’s choosing and returns that offset to the client.
This is similar to writing to a file opened in O_APPEND mode in Unix without the race conditions when multiple writers do so concurrently.
Record append is heavily used by distributed applications in which many clients on different machines append to the same file concurrently.
Record append is a kind of mutation and follows the control flow we discussed in “Leases and Mutation Order” section with only a little extra logic at the primary explained next.
In the write flow, once a request comes from the client to the primary, primary checks to see if appending the record to the current chunk would cause the chunk to exceed the maximum size (64 MB). If so, it pads the chunk to the maximum size, tells secondaries to do the same, and replies to the client, indicating that the operation should be retried on the next chunk.
If a record append fails at any replica, the client retries the operation. As a result, replicas of the same chunk may contain different data. GFS does not guarantee that all replicas are bytewise identical. It only guarantees that the data is written at least once as an atomic unit. Applications can deal with inconsistent region resulted, as discussed in the “Implications for Applications” section already.
Snapshot
The snapshot operation makes a copy of a file or a directory tree (the “source”) almost instantaneously while minimizing any interruptions of ongoing mutations. How is it done in GFS?
GFS, like The Andrew File System (AFS), uses standard copy-on-write techniques to implement snapshots.
When the master receives a snapshot request, it
It first revokes any outstanding leases on the chunks in the files it is about to snapshot.
After the leases have been revoked or have expired, the master logs the operation to disk.
It then applies this log record to its in-memory state by duplicating the metadata
for the source file or directory tree.
The newly created snapshot files point to the same chunks as the source files.
There are a few steps required when a write comes to the snapshot.
The client requests the master to find the current lease holder.
The master notices that the reference count for a chunk (let’s name C1) is greater than one.
It picks a new chunk handle, let’s name C2, and asks each chunk server that has a current replica of C1 to create a new chunk called C2.
From here onwards, the request processing for write is the same. The master grants one of the replicas a lease on the new chunk C2.
The master replies to the client.
The client can write the chunk normally.
Master Operation
The master executes all namespace operations. In addition,it manages chunk replicas throughout the system.
Namespace Management and Locking
Many master operations can take a long time: for example, a snapshot operation has to revoke chunk server leases on all chunks covered by the snapshot.
GFS does not want to delay other master operations while they are running. Therefore, it allows multiple operations to be active and use locks over regions of the namespace to ensure proper serialization.
GFS does not have a per-directory data structure that lists all the files in that directory. GFS logically represents its namespace as a lookup table mapping full pathnames to metadata.
Each node in the namespace tree (either an absolute file name or an absolute directory name) has an associated read-write lock. Each master operation acquires a set of locks before it runs.
One nice property of this locking scheme is that it allows concurrent mutations in the same directory.
Since the namespace can have many nodes, read-write lock objects are allocated lazily and deleted once they are not in use. Also, locks are acquired in a consistent total order to prevent deadlock: they are first ordered by level in the namespace tree and lexicographically within the same level.
Replica Placement
GFS typically has hundreds of chunk servers spread across many machine racks.
The chunk replica placement policy serves two purposes: maximize data reliability and availability, and maximize network and width utilization.
For both, it is not enough to spread replicas across machines. GFS must also spread chunk replicas across racks.
Creation, Re-replication, Rebalancing
Chunk replicas are created for three reasons: chunk creation, re-replication, and rebalancing.
When the master creates a chunk, it chooses where to place the initially empty replicas. It considers several factors.
GFS wants to place new replicas on chunk servers with below-average disk space utilization.
GFS wants to limit the number of “recent” creations on each chunk server.
GFS wants to spread replicas of a chunk across racks.
The master re-replicates a chunk as soon as the number of available replicas falls below a user-specified goal. Each chunk that needs to be re-replicated is prioritized based on several factors.
How far it is from its replication goal.
GGS prefers to first re-replicate chunks for live files as opposed to chunks that belong to recently deleted files.
GFS boosts the priority of any chunk that is blocking client progress.
The master picks the highest priority chunk and “clones” it by instructing some chunk server to copy the chunk data directly from an existing valid replica.
To keep cloning traffic from overwhelming client traffic, the master limits the number of active clone operations both for the cluster and for each chunk server.
The master rebalances replicas periodically: it examines the current replica distribution and moves replicas for better disk space and load balancing. The master master gradually fills up a new chunk server rather than instantly swamps it with new chunks and the heavy write traffic that comes with them.
Garbage Collection
After a file is deleted, GFS does not immediately reclaim the available physical storage. It does so only lazily during regular garbage collection at both the file and chunk levels.
When a file is deleted by the application, the master logs the deletion immediately just like other changes. The file is just renamed to a hidden name that includes the deletion timestamp. During the master’s regular scan of the file system namespace, it removes any such hidden files if they have existed for more than three days (configurable).
When the hidden file is removed from the namespace, its in-memory metadata is erased. This effectively severs its links to all its chunks.
Stale Replica Detection
Chunk replicas may become stale if a chunk server fails and misses mutations to the chunk file if it is down.
For each chunk, the master maintains a chunk version number to distinguish between up-to-date and stale replicas.
Whenever the master grants a new lease on a chunk, the chunk version number increases and informs the up-to-date replicas. If another replica is unavailable, its chunk version number will not be advanced.
The master will detect that this chunk server has a stale replica when the chunk server restarts and reports its set of chunks and their associated version numbers.
The master removes stale replicas in its regular garbage collection.
Fault Tolerance and Diagnosis
High Availability
Among hundreds of servers in a GFS cluster, some are bound to be unavailable at any given time. GFS keeps the overall system highly available with two simple yet effective strategies: fast recovery and chunk/master and replication.
Fast Recovery
The master and the chunk server are designed to restore their state and start in seconds. GFS does not distinguish between normal and abnormal termination. Servers are routinely shut down just by killing the process. Clients and other servers experience a minor hiccup as they time out on their outstanding requests, reconnect to the restarted server, and retry.
Chunk and Master Replication
Each chunk is replicated on multiple chunk servers on different racks. Users can specify different replication levels for different parts of the file namespace. The default is three.
The master state is replicated for reliability. Its operation log and checkpoints are replicated on multiple machines. A mutation to the state is considered committed only after its log record has been flushed to disk locally and on all master replicas.
If the master server machine or disk fails, monitoring infrastructure outside GFS starts a new master process elsewhere with the replicated operation log. Clients use only the canonical name of the master.
Moreover, “shadow” masters provide read-only access to the file system even when the primary master is down. They are shadows, not mirrors, in that they may lag the primary slightly, typically fractions of a second.
Data Integrity
Each chunk server uses checksumming to detect the corruption of stored data.
A chunk is broken up into 64 KB blocks. Each has a corresponding 32 bit checksum. Like other metadata, checksums are kept in memory and stored persistently with logging, separate from user data.
For reads, the chunk server verifies the checksum of data blocks that overlap the read range before returning any data to the requester(client or another chunk server). Therefore chunk servers will not propagate corruption to other machines.
Checksum computation is heavily optimized for writes that append to the end of a chunk because they are dominant in GFS workloads.
If a write overwrites an existing range of the chunk, we must read and verify the first and last blocks of the range being overwritten, then perform the write, and finally compute and record the new checksums.
If GFS do not verify the first and last blocks before overwriting them partially, the new checksums may hide corruption that exists in the regions not being overwritten.
Experiences
GFS, experienced a variety of issues, some operational and some technical.
Some of the biggest problems were disk and Linux related.
Many disks claimed to the Linux driver that they supported a range of IDE protocol versions but in fact responded reliably only to the more recent ones. This would corrupt data silently due to problems in the kernel. GFS used checksums to detect data corruption.
One problem was with Linux 2.2 kernels due to the cost of fsync(). Its cost is proportional to the size of the file rather than the size of the modified portion. The GFS team worked around this for a time by using synchronous writes and eventually migrated to Linux 2.4.
Another Linux problem was a single reader-writer lock which any thread in an address space must hold when it pages in from disk(reader lock) or modifies the address space in an mmap() call (writer lock). Single lock blocked the primary network thread from mapping new data into memory while the disk threads were paging in previously mapped data.
Related Work
AFS is a large distributed file system that provides a location-independent namespace like GFS.
GFS spreads a file’s data across storage servers in a way more akin to xFS and Swift.
GFS currently uses only replication for redundancy, and so consumes more raw storage than xFS or Swift.
GFS does not provide any caching below the file systems interface like AFS, xFS, Frangipani, and Intermezzo.
GFS most closely resembles the NASD architecture. The NASD architecture is based on network-attached disk drives, while GFS uses commodity machines as chunk servers, as done in the NASD prototype.
Conclusions
The Google File System demonstrates the qualities essential for supporting large-scale data processing workloads on commodity hardware. GFS has taken some radically different points in the design space like it treats component failures as the norm rather than the exception, optimize for huge files and extends and relaxes the standard file system interface.
GFS provides fault tolerance and also delivers high aggregate throughput to many concurrent readers and writers.
GFS has successfully met our storage needs and is widely used within Google as the storage platform for research and development as well as production data processing.
References
GFS paper: https://research.google.com/archive/gfs-sosp2003.pdf
AFS: https://www.cs.cmu.edu/~coda/docdir/s11.pdf
Serverless network file system: https://www.cs.rice.edu/~alc/comp520/papers/anderson-xfs.pdf
Swift: https://escholarship.org/content/qt8nr1b3fq/qt8nr1b3fq.pdf?t=rp5e1r
Frangipani: https://pdos.csail.mit.edu/6.824/papers/thekkath-frangipani.pdf
InterMezzo: http://www.inter-mezzo.org
NASD: https://www.pdl.cmu.edu/PDL-FTP/NASD/asplos98.pdf