
Insights from paper(part II) - Manu: A Cloud Native Vector Database Management System

In the previous post for Manu paper, we discussed the basics and architecture of the system. Make sure to go through that before continue reading this part.
Feature Highlights
Cloud Native and Adaptive
The primary design goal of Manu is to be a cloud-native vector database that fits nicely into cloud-based data pipelines.
Manu decouples system functionalities into storage, coordinators, and workers. For storage, Manu uses :
A transaction Key-Value store for metadata
Message queues for logs
Object store for Key-Value of data
All three are general storage services. They are available from major cloud vendors, so Manu’s deployment on the cloud is easy.
Manu decouples vector search, log archiving, and index-building tasks for component-wise scaling.
Manu defines a unified interface for the system components but provides different invocation methods and implementations for different platforms.
For example:
On the cloud, it uses cloud service APIs
2. On the local cluster, it uses a remote procedure call (RPC)
3. On a personal computer, it uses direct function calls
Good Usability
Manu returns the identifiers of the search results for each search request, which can be used to retrieve objects (e.g.. images, advertisements, movies) in other systems.
Manu provides APIs in popular languages, including Python, Java, Go, C++, and RESTful APIs.
For example below table shows Python-based PyManu APIs.

The search command is used for similarity-based vector search, while the query command is mainly used for attribute filtering.
An example of conducting a top-𝑘 vector search by specifying the parameters in params.
query_param = {
"vec": [[0.6, 0.3, ..., 0.8]],
"field": "vector",
"param": {"metric_type": "Euclidean"},
"limit": 2,
"expr": "product_count > 0",
}
res = collection.search(**query_param)In this example, the search request provides a high dimensional vector as query and searches the feature vector field of the collection. The similarity function is Euclidean distance, and the targets are the top-2 similar vectors.
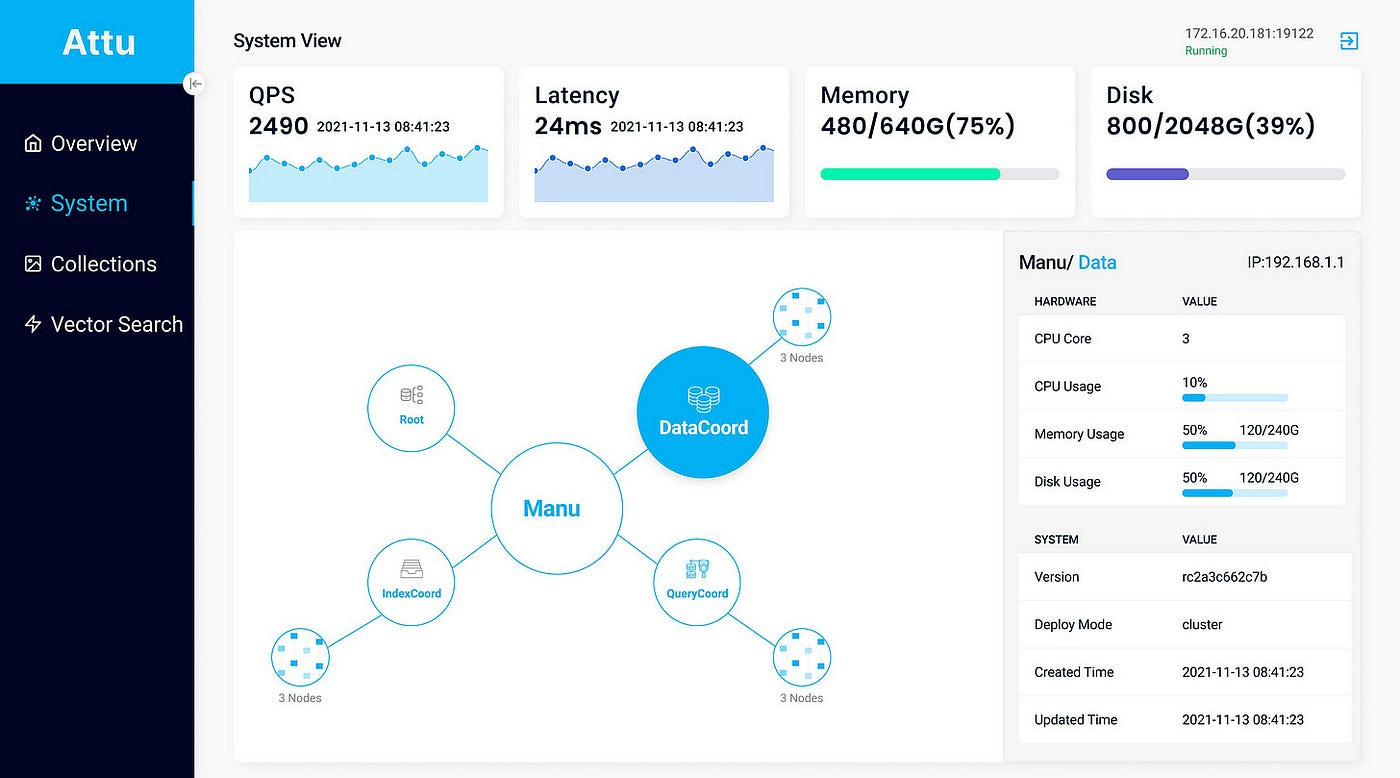
Manu also provides a GUI tool called Attu. Users can observe the overall system status in the system view, as shown in the screenshot below. It includes QPS, average query latency, and memory consumption.
Time Travel
Manu allows users to specify a target physical time 𝑇 for database restore and jointly uses checkpoint and log replay for rollback.
Manu, mark each segment with its progress 𝐿. It periodically checkpoints the segment map for a collection, which contains information (such a route, rather than data) of all its segments.
To restore the database at time 𝑇, Manu reads the closest checkpoint before 𝑇. It loads all segments in the segment map and replays the WAL log for each segment from its local progress 𝐿.
Hardware Optimizations
One of Manu's critical contributions is that it comes with extensively optimized implementations for CPU, GPU and SSD for efficiency.
Manu organizes the vectors into buckets. Bucket sizes are close to but smaller than 4kb. It is achieved by conducting hierarchical k-means for the vectors. Each bucket is stored on 4kb aligned blocks on SSD for efficient reading and represented by its k-means center in dram.
Vector search is conducted in two stages in SSD. In the first stage, Manu searches the cluster centers in dram for the ones most similar to the query. In the second step, corresponding buckets are loaded from SSD for the scan.
Use Cases and Evaluation
Milvus was the previous vector database created by the Manu team. It does not support tunable consistency. Milvius and Manu are compared for the use cases to showcase the improvements.
Overview
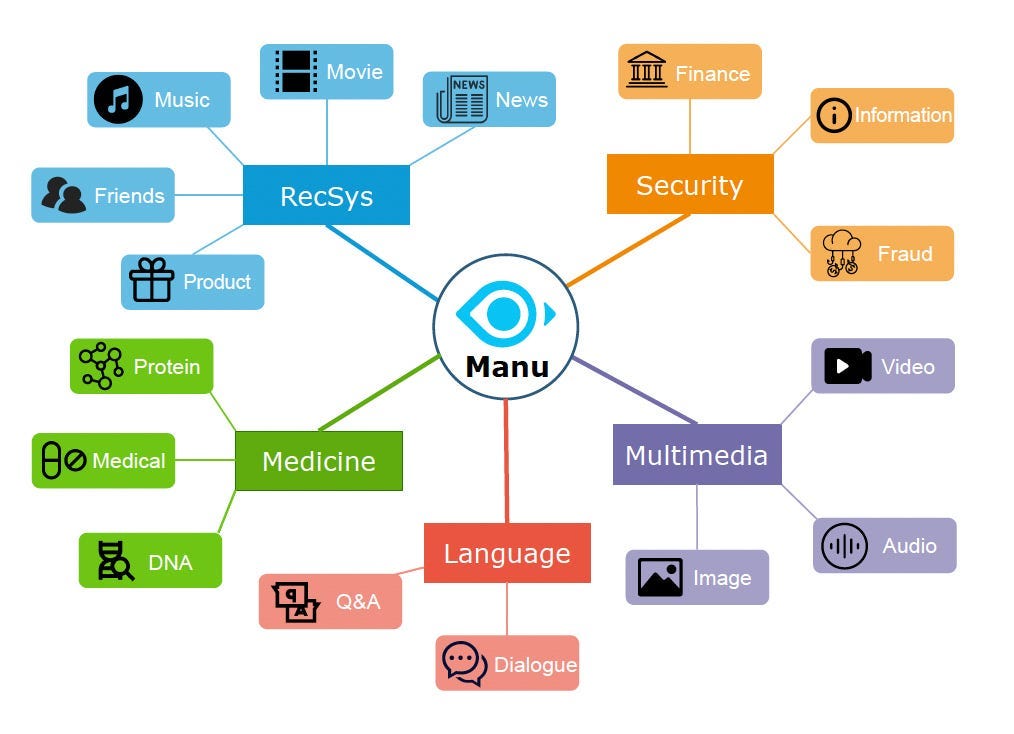
Manu divides its customers into 5 application domains:
Recommendation: Platforms for e-commerce, music, news, video, and social network record user-content interactions and use the data to map users and contents to embedding vectors. Finding contents of interest for a user is conducted by searching content vectors having significant similarity scores with user vector.
Multimedia: Multimedia content (e.g., images, video, and audio) searches from large corpus are common online. The general practice is embedding user query and corpus contents into vectors using tools such as CNN and RNN. Again, multimedia content is searched by finding vectors similar to the user query.
Language: For LLM like BERT, language sequences are embedded into vectors such that retrieving language contents boils down to finding content vectors similar to user query.
Security: The standard practice is to map spams and viruses into vectors using hashing. After that, suspicious spams and viruses can be checked by finding the most similar candidates in the corpus for further check.
Medicine: Chemical structures and gene sequences can be embedded into vectors using tools like GNN and LSTM, and their search tasks are cast into vector search.
Example Use Cases
For the experiments, Manu uses two datasets widely used for vector search research, SIFT (with 128-dim vectors) and DEEP (with 96-dim vectors). On the hardware side, two query nodes, one data node, and one index node is used. Each worker node is an EC2 m5.4xlarge. IVF-FLAT and HNSW index are used.
E-commerce recommendation
In this use case, Manu is used by an e-commerce giant based in China for the recommendation, and products are recommended to a user according to their similarity scores with the user embedding vector.
There are three main requirements for a vector database:
(1) High throughput to handle concurrent customers
(2) High-quality search results for good recommendation effect
(3) Good elasticity for low cost
The diagram below shows the comparison of the recall-throughput performance of Manu with four popular open-source vector search systems (represented as System A, System B, System C, and System D).

Video deduplication
This comparison is for a video-sharing website in Europe. Users can upload videos and share them with others. The organization found that there are many duplicate videos.
They model a video as a set of its critical frames and encode each frame into a vector. They use vector search to find videos in the corpus that are most similar to a new video and conduct further checking on the shortlisted videos to determine if the new video is duplicated.
The organization was looking for good scalability with respect to both data volume and computing resources.
The diagram below shows those results:


Virus scan
This comparison is for a world-leading software security service provider. They scan viruses in smartphones.
They have a virus base that continuously collects new viruses and develops specialized algorithms to map virus and user APK to vector embedding.
They have two requirements:
(1) Short delay for streaming update
(2) Fast index building
The diagram below shows the average delay of search requests for Manu.

The results show that search latency decreases quickly with grace time
The diagram below shows a report of the index building time.

The results show that index-building time scales linearly with data volume.
Related Work
There are three different areas from where Manu gets inspiration and learning.
Vector search algorithms
Vector search algorithms have a long research history. Existing algorithms can be roughly classified into four categories.
Space partitioning tree (SPT) — It divides the space into areas and uses tree structures to narrow down search results to some areas quickly.
Locality-sensitive hashing (LSH) — These algorithms design hash functions such that similar vectors are hashed to the same bucket with high probability.
Vector quantization (VQ) — These algorithms compress vectors and accelerate similarity computation by quantizing the vectors using a set of vector codebooks.
Proximity graph (PG) — These algorithms form a graph by connecting a vector with those most similar to it in the dataset and conducting vector search by graph walk.
Vector databases
Vector data management solutions have gone through two stages of development.
The first stage was libraries like Facebook Faiss, Microsoft SPTAG, HNSWlib, Annoy, etc. The second stage is full-fledged vector databases such as Vearch, Vespa, Weaviate, Vald, Qdrant, Pinecone, and Milvius.
Vearch uses Faiss as the underlying search engine and adopts a three-layer aggregation procedure to conduct a distributed search.
Vespa distributes data over nodes for scalability. A modified version of the HNSW algorithm is used in Vespa.
Weaviate adopts a GraphQL interface and allows storing objects (e.g., texts, images), properties, and vectors. Users can directly import vectors or customize embedding models to map objects to vectors. Weaviate can retrieve objects based on vector search results.
Vald supports horizontal scalability by partitioning a vector dataset into segments and building indexes without stopping search services.
Qdrant is a single-machine vector search engine with extensive support for attribute filtering.
Cloud-native databases
There are many OLAP databases designed to run on the cloud. Some of them are Redshift, BigQuery, Snowflake, and AnalyticDB.
Aurora and PolarDB Serverless are two cloud-native OLTP databases. Aurora uses a shared-disk architecture and proposes the “log is database” principle. Aurora observes that the bottleneck of cloud-based platforms has shifted from computation and storage IO to network IO. PolarDB Serverless adopts a disaggregation architecture, which uses a high-speed RDMA network to decouple hardware resources as resource pools.
Conclusions and Future Directions
This paper introduces the designs of Manu as a cloud-native vector database. Its goal includes good evolvability, tunable consistency, high elasticity, efficiency, etc. Manu trades the simple data model of vectors and the weak consistency requirement of applications for performance, costs, and flexibility.
Manu uses the log backbone to connect the system. Manu also introduces essential features such as high-level API, GUI tool, hardware optimizations, and complex search.
Manu is still a new system and needs work in below areas:
Multi-way search, Modularized algorithms, Hierarchical storage aware index, Advanced hardware, Embedding generation toolbox
References
The first part: https://www.hemantkgupta.com/p/insights-from-paperpart-i-manu-a
The original paper: https://www.vldb.org/pvldb/vol15/p3548-yan.pdf
Pinecone: https://www.pinecone.io/.
Qdrant: https://qdrant.tech/.
Vald: https://github.com/vdaas/vald.
Vespa: https://vespa.ai/.
Weaviate: https://github.com/semi-technologies/weaviate.
Microsoft SPTAG: A library for fast approximate nearest neighbor search. https://github.com/microsoft/SPTAG.
Analyticdb: Realtime olap database system at alibaba cloud: Chaoqun Zhan, Maomeng Su, ChuangxianWei, Xiaoqiang Peng, Liang Lin, Sheng Wang, Zhe Chen, Feifei Li, Yue Pan, Fang Zheng, et al. 2019. Proceedings of the VLDB Endowment 12, 12 (2019), 2059–2070.
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases: Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. In Proceedings of the 2017 ACM International Conference on Management of Data, SIGMOD Conference 2017, Chicago, IL, USA, May 14–19, 2017. ACM, 1041–1052.
Billion-scale commodity embedding for e-commerce recommendation in alibaba.: JizheWang, Pipei Huang, Huan Zhao, Zhibo Zhang, Binqiang Zhao, and Dik Lun Lee. 2018. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 839–848.
Amazon Redshift and the Case for Simpler Data Warehouses: Anurag Gupta, Deepak Agarwal, Derek Tan, Jakub Kulesza, Rahul Pathak, Stefano Stefani, and Vidhya Srinivasan. 2015. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Victoria, Australia, May 31 — June 4, 2015. ACM, 1917–1923.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2–7, 2019, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 4171–4186. https://doi.org/10.18653/v1/n19-1423
PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers: Wei Cao, Yingqiang Zhang, Xinjun Yang, Feifei Li, ShengWang, Qingda Hu, Xuntao Cheng, Zongzhi Chen, Zhenjun Liu, Jing Fang, et al. 2021. In Proceedings of the 2021 International Conference on Management of Data. 2477–2489.