
Insights from papers - MapReduce: Simplified Data Processing on Large Clusters

Abstract
What is MapReduce?
It is a programming model and an associated implementation for processing and generating large data sets.
How does it work?
A user-provided map function processes a key/value pair to generate a set of intermediate key/value pairs.
A user-provided reduce function merges all intermediate values associated with the same intermediate key.
What are its benefits?
Before we go into benefits, let’s understand, as programmers, what we have to do to process a large set of data using a large cluster of machines.
We must partition the input data, schedule the program’s execution across a set of machines, handle machine failures, and manage the required inter-machine communication to complete our work.
I hope you got the idea that it is a lot to expect from a programmer to do all this.
MapReduce runtime (implementation) will handle all these things for you. You need only to provide the map and reduce functions as code. You don’t need to be a wizard of distributed systems.
Google’s implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable.
A typical MapReduce computation (a job) processes many terabytes of data on thousands of machines.
Introduction
The authors and many others at Google have implemented hundreds of special-purpose computations where input data is usually extensive, and the computations have to be distributed across hundreds or thousands of machines to finish in a reasonable amount of time. An example is the processing of crawled web documents.
So what is the problem?
The problem is that each computation team has to take care of parallelizing the computation, distributing the data and handling failures, etc, as we talked about in the previous section. And the actual computation work is minimal.
To remove all the complexity of heavy lifting, Google designed a new abstraction that allows to express the simple computations. It hides all the messy details of parallelization, fault tolerance, data distribution, and load balancing in a library.
The team realized that most of their computations follow the below pattern:
Apply a map operation to each logical “record” in our input to compute a set of intermediate key/value pairs
Applying a reduce operation to all the values that shared the same key to combine the derived data appropriately.
So the team decided to have a functional model which mimics these steps. They created the interface for the computations and the implementation of the interface, which handles all automatic parallelization, distribution, etc.
Programming Model
The model is straightforward.
It takes a set of key/value pairs as input.
It produces a set of key/value pairs as output.
The user has to express his computation as two functions — Map and Reduce.
The Map function will take an input pair and produce intermediate pair.
The library groups all the intermediate pair associated with a key.
Now these pairs are input for the Reduce function. It merges these values to form a smaller set of values.
An Example
Problem: Count the number of occurrences of each word in a large collection of documents.
The user would write code similar to the following pseudo-code:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));The map function emits each word and counts as 1 for each word present in the input.
The reduce function does the sum of all counts emitted for a particular word.
In the real world, the user/programmer provides the code in language specific object. The user’s code will be linked with the MapReduce library for execution.
Types
The map and reduce functions provided by the user have associated types:
map (k1, v1) → list(k2,v2)
reduce (k2, list(v2)) → list(v2)
The C++ implementation passes strings to and from the user-defined functions and leaves it to the user code to convert between strings and appropriate types.
More Examples
Distributed Grep: The map function emits a line if it matches a supplied pattern. The reduce function is an identity function that copies the supplied intermediate data to the output.
Count of URL Access Frequency: The map function processes logs of web page requests and outputs (URL, 1). The reduce function adds together all values for the same URL and emits a (URL, total count) pair.
Reverse Web-Link Graph: The map function outputs (target, source) pairs for each link to a target URL found in a page named source. The reduce function concatenates the list of all source URLs associated with a given target URL and emits the pair: (target, list(source)).
Term-Vector per Host: A term vector summarizes the most important words in a document or a set of documents as a list of (word, frequency) pairs. The map function emits a (hostname, term vector) pair for each input document. The reduce function adds these term vectors together, throwing away infrequent terms, and then emits a final (hostname, term vector) pair.
Inverted Index: The map function parses each document and emits a sequence of (word, document ID) pairs. The reduce function accepts all pairs for a given word, sorts the corresponding document IDs, and emits a (word, list(document ID)) pair. The set of all output pairs forms a simple inverted index.
Implementation
Implementing MapReduce in different ways to cater to different environments is possible.
One possible implementation in Google is listed below:
Machines are typically dual-processor x86 processors running Linux, with 2–4 GB of memory per machine.
Commodity networking hardware is used. It is typically 100 megabits/second or 1 gigabit/second at the machine level.
A cluster consists of hundreds or thousands of machines.
Storage is provided by inexpensive IDE disks attached directly to individual machines.
Users submit jobs to a scheduling system. Each job consists of a set of tasks and is mapped by the scheduler to a set of available machines within a cluster.
The Google file system developed in-house was used to manage the data stored on these disks.
Execution Overview
The Map invocations are distributed across multiple machines by automatically partitioning the input data into M splits.
Reduce invocations are distributed by partitioning the intermediate key space into R pieces using a partitioning function (for example, a hash).
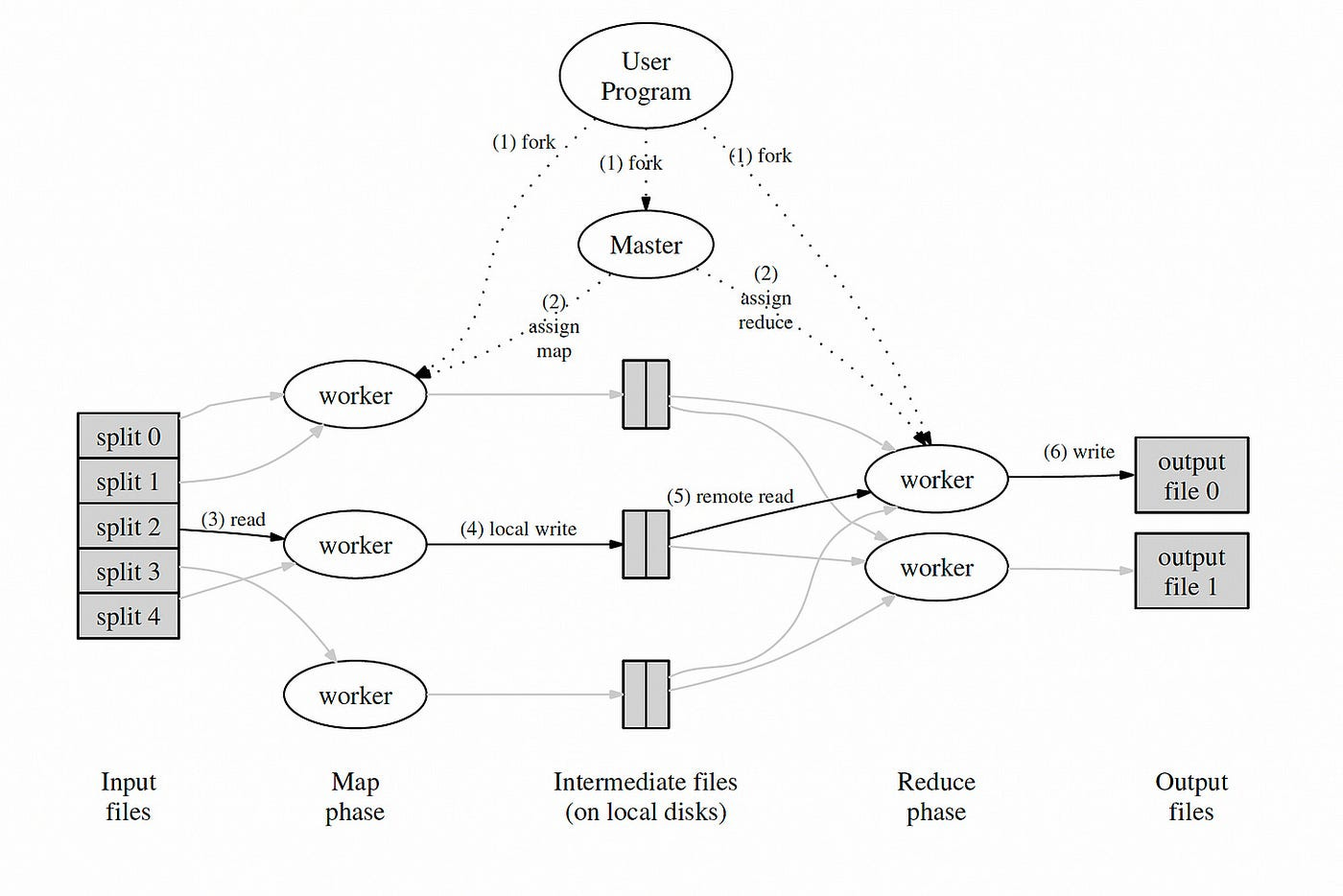
The above diagram shows all the steps of execution of an example program. Let’s summarize them:
The MapReduce library splits the input files into M pieces.
One of the copies of the program is unique — the master. The master assigns the other workers to work.
A worker reads the contents of the corresponding input split. It parses key/value pairs from the input data. It passes each pair to the user-defined Map function. The output intermediate key/value pairs are buffered in memory.
The buffered pairs are written to the local disk periodically. They are partitioned into R regions by the partitioning function.
The master notifies the reduce worker for the data locations. The reduce worker uses RPC to read the buffered data from the local disks of the map workers.
The reduce worker iterates over the sorted intermediate data for each unique intermediate key. It passes the key and the corresponding intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
When all map tasks and reduce tasks have been completed, the master wakes up the user program.
Master Data Structures
The master maintains several data structures.
For each map task and reduce task, it stores the state of the task and the identity of the worker machine.
For each completed map task, the master stores the locations and sizes of the R intermediate file regions produced by the map task.
The location and size updates are received once the map task is completed. This information is passed to in-progress reduce workers.
Fault Tolerance
Worker Failure
The master pings every worker periodically. If no response is received from a worker in a certain amount of time, the master marks the worker as failed. Let’s see what has to be done for the task running on the worker.
Completed map tasks are marked idle. They will be re-executed as the output data was on the worker’s local disk.
In-progress map and reduce tasks on the worker are re-scheduled.
Any rescheduling of map tasks is notified to all reduce workers so that they can read the data from the new worker.
Master Failure
The master can periodic checkpoints of the master data structures we discussed previously. If the master task dies, a new copy can be started from the last checkpointed state.
Considering there is one master, the current implementation of MapReduce aborts the job, and the user has to retry.
Semantics in the Presence of Failures
If the user-supplied map and reduce operators are deterministic functions of their input values, the implementation produces the same output even in case of worker failures.
Using atomic commits of map and reduce task outputs, it is achieved.
A map task produces R temporary files. When a map task completes, the worker sends a message to the master and includes the names of the R temporary files in the message.
When a reduce task completes, the reduce worker atomically renames its temporary output file to the final output file.
Locality
To save data transfer bandwidth, input data is stored on the local disks of the machines that make up our cluster. Google uses GFS for that.
Task Granularity
We have seen that the map phase is divided into M pieces, and the reduce phase is divided into R pieces.
Ideally, M and R should be much larger than the number of worker machines.
Backup Tasks
Sometimes a machine takes an unusually long time to complete one of the last few map or reduce tasks in the computation. It is called a straggler.
The team has a general mechanism to alleviate the problem of stragglers. When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks.
The task is marked as completed whenever the primary or the backup execution completes.
Refinements
It is sufficient to use map and reduce for most of the tasks. The team has created a few useful extensions to help.
Partitioning Function: The user can specify the number of reduce tasks/output files (R). A default partitioning function is provided that uses hashing (e.g., “hash(key) mod R”).
Ordering Guarantees: Within a given partition, the intermediate key/value pairs are processed in increasing key order. This makes it easy to generate a sorted output file per partition.
Combiner Function: There may be significant repetition in the intermediate keys produced by each map task. Also, the Reduce function is commutative and associative. In such cases, the user can specify an optional Combiner function that partially merges data before sending it over the network.
Input and Output Types: The library supports reading input data in several formats. For example, txt mode input treats each line as a key/value pair: the key is the offset in the file, and the value is the contents of the line.
Side-effects: It can produce auxiliary files as additional outputs from their map and/or reduce operators. Typically the application writes to a temporary file and atomically renames it once it has been entirely generated.
Skipping Bad Records: There is an optional mode of execution where the MapReduce library detects which records cause deterministic crashes and skips these records to make forward progress.
Local Execution: To help facilitate debugging, profiling, and small-scale testing, the team has developed an alternative implementation of the MapReduce library that sequentially executes all of the work for a MapReduce operation on the local machine.
Status Information: The master runs an internal HTTP server and exports a set of status pages for human consumption. The pages contain links to the standard error and standard output files generated by each task.
Counters: The MapReduce library provides a counter facility to count occurrences of various events.
Related Work
Previous attempts have provided restricted programming models that try to parallelize the computation automatically.
MapReduce can be considered a simplification and distillation of some of these models.
Most parallel processing systems have only been implemented on smaller scales and leave the details of handling machine failures to the programmer.
Bulk Synchronous Programming and some MPI primitives provide higher-level abstractions, making it easier for programmers to write parallel programs.
The locality optimization draws its inspiration from techniques such as active disks.
The backup task mechanism is similar to the eager scheduling mechanism employed in the Charlotte System.
The MapReduce implementation relies on an in-house cluster management system responsible for distributing and running user tasks on a large collection of shared machines. The system is similar to Condor.
River provides a programming model where processes communicate with each other by sending data over distributed queues.
Conclusions
Google has successfully used the MapReduce programming model internally for a lot of computation on large data sets. There are the following reasons for that:
The model is easy to use, even for programmers without experience with parallel and distributed systems.
A large variety of problems are easily expressible as MapReduce computations.
The team has developed an implementation of MapReduce that scales to large clusters of machines comprising thousands of machines.
References
The original paper: https://research.google.com/archive/mapreduce-osdi04.pdf
Cluster I/O with River: Making the fast case common: Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David Patterson, and Kathy Yelick. In Proceedings of the Sixth Workshop on Input/Output in Parallel and Distributed Systems (IOPADS ’99), pages 10–22, Atlanta, Georgia, May 1999.
Charlotte: Metacomputing on the web: Arash Baratloo, Mehmet Karaul, Zvi Kedem, and Peter Wyckoff. In Proceedings of the 9th International Conference on Parallel and Distributed Computing Systems, 1996.
The Google file system: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. In 19th Symposium on Operating Systems Principles, pages 29–43, Lake George, New York, 2003.
Using MPI: Portable Parallel Programming with the Message-Passing Interface: William Gropp, Ewing Lusk, and Anthony Skjellum. MIT Press, Cambridge, MA, 1999.
Active disks for large-scale data processing: Erik Riedel, Christos Faloutsos, Garth A. Gibson, and David Nagle. IEEE Computer, pages 68–74, June 2001.
Distributed computing in practice: The Condor experience. Concurrency and Computation: Douglas Thain, Todd Tannenbaum, and Miron Livny. Practice and Experience, 2004.