
Insights from paper - FaRM : No compromises: distributed transactions with consistency, availability, and performance

1. Abstract
This paper presents a system named FaRM.
It is a main-memory distributed computing platform that provides distributed transactions with strict serializability, high performance, durability, and high availability.
A quote from the paper about its performance:
FaRM achieves a peak throughput of 140 million TATP transactions per second on 90 machines with a 4.9 TB database, and it recovers from a failure in less than 50 ms.
2. Introduction
A distributed system that provides transactions with high availability and strict serializability makes programming simple. It provides an abstraction for programmers to consider the whole system as if it were on a single machine.
Some systems, like Dynamo or Memcached, improve performance by either not supporting transactions or implementing weak consistency guarantees.
If you want to know more about these systems, read my posts on Dynamo and Memache.
Another type of system provides transactions only when all the data resides within a single machine. In that case, programmers have to worry about data partition.
FaRM overcomes both areas and provides distributed ACID transactions with strict serializability, high availability, high throughput, and low latency.
FaRM leverages two hardware trends:
A fast commodity network with RDMA.
An inexpensive approach for non-volatile DRAM
A quick point about DRAM's non-volatility: FaRM achieved it by attaching batteries to power supply units and writing the contents of DRAM to SSD when the power fails.
These two points avoid the two biggest bottlenecks of distributed systems - Storage and network.
For CPU bottleneck, FaRM uses the three principles below:
Reduce message counts
Use one-sided RDMA(Remote Direct Memory Access)
Exploit parallelism effectively
Before we proceed, Let me tell you what i one-sided RDMA if you are hearing this term first time. It is a network communication technology that allows one computer (the initiator) to directly read from or write to the memory of another computer (the target) without involving the target's CPU.
Let’s understand the key points in FaRM.
FaRM scales out by distributing objects across the machines in a data center.
It allows transactions to span any number of machines.
FaRM reduces message counts by using vertical Paxos with primary backup replication.
Unreplicated coordinators communicate directly with primaries and backups.
FaRM uses optimistic concurrency control with a four-phase commit protocol (lock, validation, commit backup, and commit primary).
FaRM transactions use one-sided RDMA. Coordinators use one-sided RDMA for logging.
One-sided RDMA creates one problem. How to handle the failure-recovery?
FaRM created a protocol to solve this problem. The protocol uses a precise membership to ensure that machines agree on the current configuration membership and send one-sided operations only to machines that are members.
FaRM uses reservations to ensure enough space for the logs for all the records needed to commit and truncate a transaction before starting the commit.
FaRM’s failure recovery protocol effectively uses parallelism. It distributes recovery of every bit of state evenly across the cluster and parallelizes recovery across cores in each machine.
There are two optimizations done for transaction processing as below:
Transactions begin accessing data affected by a failure after a lock recovery phase that takes only tens of milliseconds.
Transactions that are unaffected by a failure continue executing without blocking.
FaRM recovers from single machine failures in less than 50 ms.
3. Hardware trends
A typical data center machine has 128–512GB of DRAM per 2-socket machine. This means a petabyte of DRAM requires only 2000 machines, which is a large enough storage space for many high-volume applications.
3.1 Non-volatile DRAM
Lithium-ion batteries are cheaper than lead-acid batteries in a traditional, centralized approach to a distributed uninterruptible power supply (UPS).
This distributed UPS makes DRAM durable logically. In case of a power failure, the distributed UPS continues to power DRAM, and the memory contents are saved to a commodity SSD.
The FaRM team worked on the cost structure of energy consumed for the failure case. They found that treating all machine memory as non-volatile RAM (NVRAM) is feasible and cost-effective. So FaRM stores all data in memory and considers it durable.
3.2 RDMA networking
The FaRM team has previously worked on RDMA. They found that RDMA reads performed 2x better than a reliable RPC when all machines read small objects randomly chosen from the other machines in the cluster.
The team found the network interface card (NIC) message rate to be the bottleneck. RPC requires twice as many messages as one-sided reads using RDMA.
In an experiment, two Infiniband FDR (56 Gbps) NICs were used to address this bottleneck. Now, both RDMA and RPC are CPU-bound.

4. Programming model and architecture
The core part of FaRM is the global address space. The DRAM of all machines in the cluster is combined and presented as an abstraction to applications.
Each machine runs application threads and stores objects in this address space.
FaRM API provides transparent access to local and remote objects.
An application thread can start a transaction anytime and become the transaction’s coordinator. The thread can execute arbitrary logic during transactions and read, write, allocate, and free objects. At the end of the execution, the thread invokes FaRM to commit the transaction.
FaRM transactions use optimistic concurrency control. The changes are buffered locally during execution and are only visible to other transactions on the successful commit.
FaRM provides strict serializability.
FaRM guarantees that individual object reads are atomic, read only committed data, that successive reads of the same object return the same data, and that reads of objects written by the transaction return the latest value written during the transaction's execution.
FaRM does not guarantee atomicity across reads of different objects but ensures that the transaction does not commit to ensure committed transactions are strictly serializable.
It allows consistency checks to be deferred until the commit time is reached.
The FaRM API provides lock-free reads.
The diagram below shows a FaRM instance with four machines.
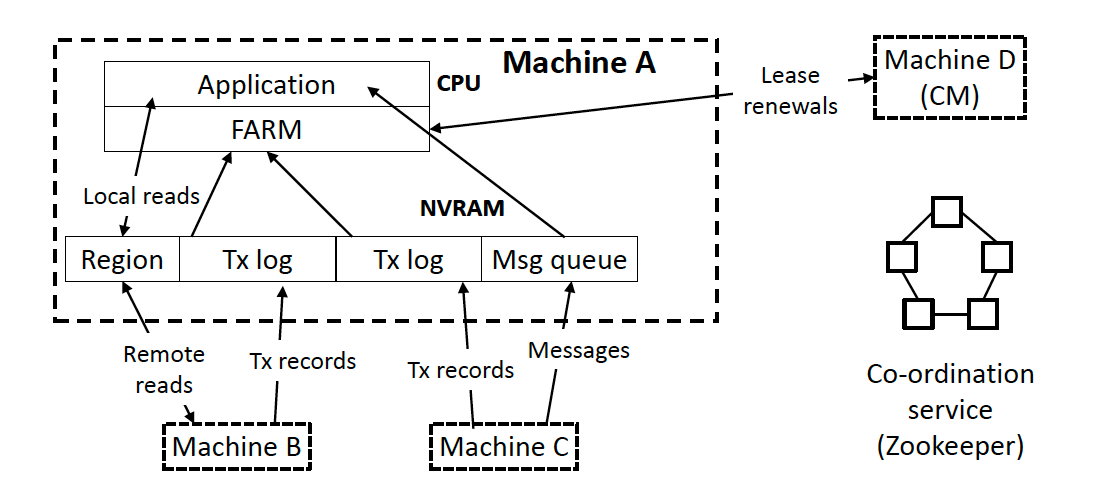
Each machine runs FaRM in a user process with a kernel thread pinned to each hardware thread. Each kernel thread runs an event loop that executes application code and polls the RDMA completion queues.
FaRM uses a Zookeeper coordination service to ensure machines agree on and store the current configuration.
A FaRM instance moves through a sequence of configurations over time as machines fail or new machines are added.
A configuration is a tuple <i, S, F, CM>.
i - It is a unique, monotonically increasing 64-bit configuration identifier.
S - It is the set of machines in the configuration.
F - It is a mapping from machines to failure domains( fail independently).
CM - It is an S machine called Configuration Manager.
The CM manages leases, detects failures, or coordinates recovery.
Zookeeper is invoked by the CM once per configuration change to update the configuration.
The global address space in FaRM consists of 2GB regions. Each region is replicated on one primary and n backups. Here, n is the desired fault tolerance.
Each machine stores several regions in DRAM. These can be read by other machines using RDMA.
Objects are always read from the primary copy.
Each object has a 64-bit version used for concurrency control and replication.
The mapping of a region identifier to its primary and backups is maintained by the CM and replicated with the region.
Other machines fetch the mappings on demand and cache them by threads together with the RDMA references needed to issue one-sided RDMA reads to the primary.
Machines contact the CM to allocate a new region. The CM assigns a region identifier from a monotonically increasing counter and selects replicas for the region.
If all replicas report success in allocating the region, the CM sends a commit message to them all.
There are up to 250 regions on a typical machine.
A single CM could handle region allocation for thousands of machines.
Each machine stores ring buffers that implement FIFO queues. These are used either as transaction logs or message queues.
Each sender-receiver pair has its own log and message queue, physically located on the receiver.
The sender appends records to the log using one-sided RDMA writes to its tail.
The receiver periodically polls the head of the log to process records. When it truncates the log, it lazily updates the sender, allowing the sender to reuse space in the ring buffer.
5. Distributed transactions and replication
FaRM integrates the transaction and replication protocols to improve performance.
FaRM uses primary backup replication in non-volatile DRAM for both data and transaction logs.
It uses optimistic concurrency control with read validation.

The diagram above shows the timeline for a FaRM transaction.
During the execution phase, transactions use one-sided RDMA to read objects and buffer writes locally.
The coordinator also records the addresses and versions of all objects accessed.
At the end of the execution, FaRM attempts to commit the transaction by executing the following steps:
Lock - The coordinator writes a LOCK record to the log on each machine that is a primary for any written object. Primaries process these records by attempting to
lock the objects.
Validate - The coordinator performs read validation by reading, from their primaries. If any object has changed, validation fails and the transaction is
aborted.
Commit Backups - The coordinator writes a COMMIT-BACKUP record to the non-volatile logs at each backup and then waits for an ack from the NIC hardware.
Commit Primaries - After all COMMIT-BACKUP writes have been acked, the coordinator writes a COMMIT-PRIMARY record to the logs at each primary. It reports completion to the application on receiving at least one hardware
ack for such a record.
Truncate - Backups and primaries keep the records in their logs until they are truncated. The coordinator truncates logs at primaries and backups lazily after receiving acks from all primaries.
I am omitting the proof for the corretness of the algorithm and request the readers to go through the paper for it. For the beginner readers it is way beyond the scope.
6. Failure recovery
FaRM machines can fail by crashing. The good part is that they can recover without losing the contents of non-volatile DRAM.
FaRM provides durability for all committed transactions even if the entire cluster fails or loses power. All the committed states can be recovered from regions and logs stored in non-volatile DRAM.
It provides durability even if at most f replicas per object fails as there are f+1 stores.
There are five phases of failure recovery:
Failure detection, Reconfiguration, Transaction state recovery, Data recovery, and Allocator state recovery
6.1 Failure detection
FaRM uses leases for failure detection.
Every machine holds a lease at the CM.
CM holds a lease on every other machine.
Failure recovery is triggered when any lease expires.
Leases are granted using a 3-way handshake.
Each machine sends a lease request to the CM.
CM responds with a message. This message acts as a lease grant and also as a lease request from CM.
The machine replies with a lease grant to the CM.
FaRM leases are extremely short ( in the range of 5 ms). It uses dedicated queue pairs for leases to avoid delays. It also uses a dedicated lease manager thread with the highest priority on user space.
FaRM leaves two hardware threads on each machine for the lease manager. It preallocates all memory used by the lease manager during initialization.
6.2 Reconfiguration
FaRM has created a protocol to move from one configuration to the next.
Let’s examine the protocol in depth. The general idea is to implement precise membership. After a failure, all machines in a new configuration must agree on membership before allowing object mutations.
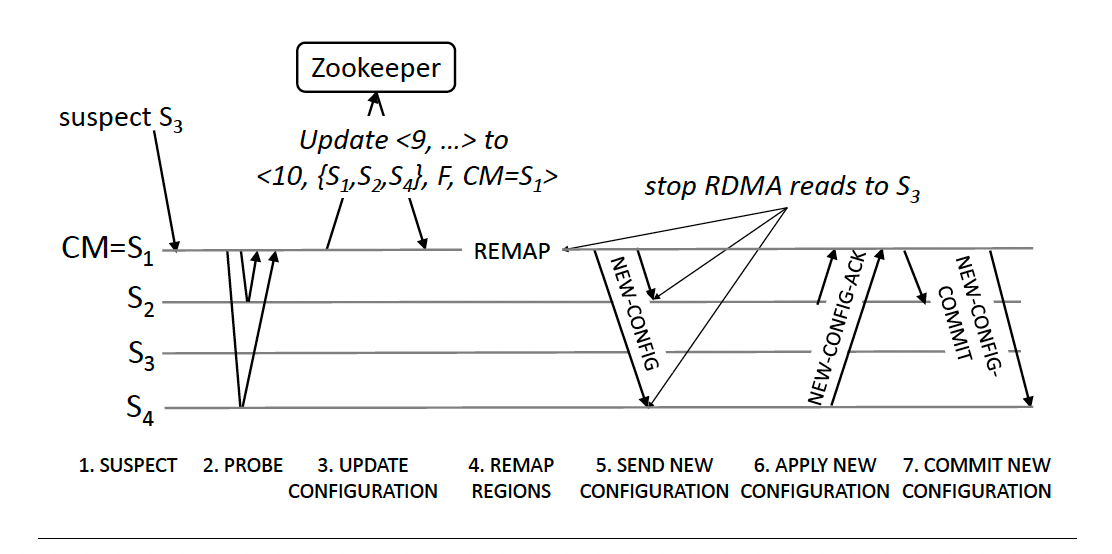
The diagram above shows an example of reconfiguration. There are following seven steps:
Suspect - CM suspects machine failure when the lease for a machine expires. A non-CM can also suspect CM failure when the lease expires. In this case, the machine first asks one of a small number of “backup CMs” to initiate reconfiguration. It attempts to reconfigure if the configuration is unchanged after a timeout period.
The machine initiating the reconfiguration will try to become the new CM as part of the reconfiguration.
Probe - The new CM issues an RDMA read to all the machines in the configuration except the suspected machine. Any machine for which the read fails is also suspected.
The new CM proceeds with the reconfiguration only if it obtains responses for a
majority of the probes.
Update Configuration - After receiving replies to the probes, the new CM attempts to update the configuration data stored in Zookeeper by incrementing the current configuration identifier. FaRM uses Zookeeper znode sequence numbers to implement an atomic compare-and-swap.
Remap Regions - The new CM then reassigns regions previously mapped to failed machines to restore the number of replicas to f + 1. It balances load and promotes a surviving backup as the new primary for failed primaries.
It also detects regions that lost all their replicas and signals an error.
Send new Configurations - After remapping regions, the CM sends a NEW-CONFIG message to all the machines in the configuration. If the CM has changed, NEW-CONFIG also resets the lease protocol.
Apply new Configurations—When a machine receives a NEW-CONFIG with a configuration identifier greater than its own, it updates its current configuration identifier. It also updates its cached copy of the region mappings and allocates space to hold any new region replicas assigned to it.
The machines reply to the CM with a NEW-CONFIG-ACK message.
Commit new Configurations - Once the CM receives NEW-CONFIG-ACK messages from all machines in the configuration, it waits to ensure that any leases granted in previous configurations to machines no longer in the configuration have expired.
CM then sends a NEW-CONFIG-COMMIT to all the configuration members.
All members now unblock previously blocked external client requests and initiate transaction recovery.
6.3 Transaction state recovery
The logs are distributed across the replicas of objects modified by a transaction.
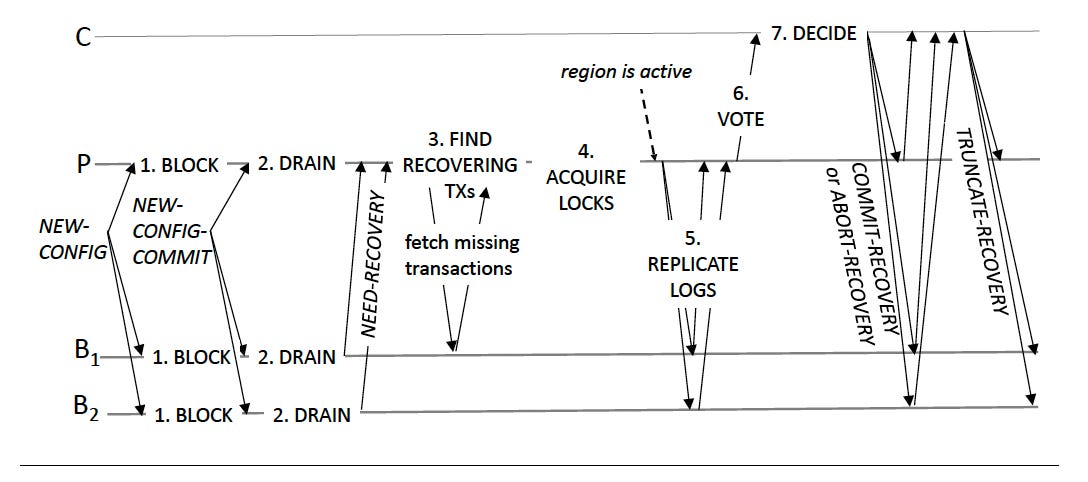
Transaction state recovery showing a coordinator C, primary P, and two backups B1 and B2
There are six steps in a transaction state recovery.
Block access to recovering regions - The first step is to block the region's access until all transactions are reflected at the new primary.
Drain logs - This will ensure that all relevant records are processed during recovery. All machines do it. They process all the records in their logs when they receive a NEW-CONFIG-COMMIT message.
Find recovering transactions - A recovering transaction has two characteristics. First, its commit phase spans configuration changes. Second, some replicas of a written object, some primary of a read object, or the coordinator have changed due to reconfiguration.
Lock recovery - The primary of each region waits until the local machine logs have been drained and NEED-RECOVERY messages have been received from each backup. It builds the complete set of recovering transactions that affect
the region. Once lock recovery is complete for a region, it is active.
Replicate log records - The threads in the primary replicate log records by sending backups the REPLICATE-TX-STATE message for any transactions that are missing.
Vote - The coordinator for a recovering transaction decides whether to commit or abort the transaction based on votes from each region updated by the transaction. The primaries of each region send the votes. FaRM uses consistent hashing to determine the coordinator for a transaction.
Decide - The coordinator commits a transaction if it receives a commit-primary vote from any region. It waits for all regions to vote and commit if at least one region voted commit-backup and all other regions modified by the transaction voted lock, commit-backup, or truncated. It aborts the transaction if none of the above steps are executed.
6.4 Recovering data
FaRM must recover data at new backups for a region to tolerate future replica failures.
Here, data recovery is not necessary to resume regular case operations. Recovery can be delayed until all regions become active.
When all regions for which it is primary become active, each machine sends a REGIONS-ACTIVE message to the CM. It reply that the CM sends ALL-REGIONS-ACTIVE to all machines in the configuration. At this point, FaRM begins data recovery for new backups in parallel with foreground operations.
A new backup for a region initially has a zeroed local region replica. It divides the region across worker threads that recover it in parallel.
The worker thread's next read starts at a random point within an interval (set to 4ms) after the start of the previous read. This helps control the scheduling and reduce the impact on foreground performance.Each recovered object is examined before copying.
6.5 Recovering allocator state
The FaRM allocator splits regions into blocks (1 MB) used as slabs for allocating small objects.
The allocator keeps two metadata: block headers (has object size) and slab-free lists.
Block headers are replicated to backups when a new block is allocated. The new primary sends block headers to all backups immediately after receiving NEW CONFIG-COMMIT.
The slab-free lists are kept only at the primary.
Each object has a bit in its header. It is set by an allocation and cleared by a free during transaction execution.
After a failure, the free lists are recovered on the new primary by scanning the objects in the region. The allocation recovery starts after ALL-REGIONS-ACTIVE is received.
7. Evaluation
The paper contains extensive data related to the TPC-C benchmark. However, since this section primarily presents experimental results without introducing new theoretical concepts, I will skip this part. Interested readers can refer to the original paper for detailed data and results.
8. Related work
As per the team, FaRM is the first system to simultaneously provide high availability, high throughput, low latency, and strict serializability.
A previous version of FaRM logs to SSDs for durability and availability, but it did not describe failure recovery.
RAMCloud is a key-value store that stores a single copy of data in memory and uses a distributed log for durability. It does not support multi-object transactions. On a failure, it recovers in parallel on multiple machines, and during this period, which can take seconds, the data on failed machines is unavailable.
Spanner provides strict serializability but is not optimized for performance over RDMA. It uses 2f + 1 replicas compared to FaRM’s f + 1 and sends more messages to commit than FaRM. You can read more about Spanner in my paper article here.
Sinfonia offers a shared address space with serializable transactions implemented using a 2-phase commit.
HERD is an in-memory RDMA-based key-value store that delivers high performance per server. It uses RDMA writes and send/receive verbs for messaging but does not use RDMA reads. It doesn’t support transactions. HERD is not fault-tolerant
Pilaf is a key-value store that uses RDMA reads. It doesn’t support transactions. Logging to a local disk gives Pilaf durability but not availability.
References
Scaling Memcache at Facebook Scale paper post