
Insights from paper: Google F1 Lightning: HTAP as a Service

1. Abstract
What is the HTAP system?
HTAP is a Hybrid Transactional/Analytical Processing system.
It combines an OLTP(Online Transaction Processing) system and an OLAP(Online Analytical Processing) system.
It allows users to simultaneously run transactional and analytical workloads over the same data set.
The concept of HTAP comes from the context of “Greenfield” systems. It means designing a new system from scratch without any constraints or limitations legacy systems impose.
Google must support new and legacy applications that demand transparent, fast queries and transactions. So, the team built a system called F1 Lightning.
2. Introduction
There has been a great deal of research and development relevant to HTAP systems.
This paper uses a loosely coupled HTAP architecture that can support HTAP workloads under various constraints.
Google uses multiple transactional data stores that serve large legacy and new workloads.
The team needed a single HTAP solution that could be enabled across the different options for transactional storage to avoid costly migrations and to permit flexibility in the design of transactional storage systems.
The team designed and developed F1 Lighting called “HTAP-as-a-service” because it can transparently provide HTAP functionality.
Users need to mark some tables in their schema in the transactional store as “Lightning tables.”
The HTAP service handles the actual logistics of running and supporting Lightning in production.
There are a lot of things to do. Create a read-optimized copy of the data, keep it consistent and fresh with respect to the transactional data, manage controlled replication, and optimize and execute queries that may span transactional and Lightning tables.
All of the above is handled by Lightning and its integration with a federated query engine (Google F1 Query).
3. Related Work
HTAP solutions are divided into two categories:
Single System for OLTP and OLAP
Separate OLTP and OLAP Systems
“Single System for OLTP and OLAP” can use hybrid row-wise and columnar or single data organizations for both ingestion and analytics.
“Separate OLTP and OLAP Systems” can be divided into two subcategories: shared storage or decoupled storage for OLTP and OLAP.
F1 Lightning uses decoupled storage and assumes no modifications to the OLTP storage can be made.
Many applications set up their HTAP architecture using loosely decoupled storage by maintaining a separate, offline ETL process. Ingesting data into columnar file formats tends to suffer from a high lag between the OLTP data and the OLAP copy.
F1 Lightning improves data freshness by integrating with a Change Data Capture (CDC) mechanism and using a hybrid memory-resident and disk-resident storage hierarchy.
SAP HANA Asynchronous Parallel Table Replication (ATR) is a replication architecture. It handles all OTLP workloads in a single server machine with a row-format store.
It uses a parallel log replay scheme to maintain OLAP replicas in column formats.
This tight coupling between OLTP and OLAP processing helps achieve lower data delay.
TiFlash is a columnar extension for TiDB.
It adds a columnar storage and vectorized processing layer to the row-store TiDb and is tightly integrated with the TiDB query layer. TiFlash only maintains casual consistency with TiDB.
Oracle Database In-Memory (DBIM) is an example of “Single System for OLTP and OLAP.” It accelerates HTAP workloads by maintaining an in-memory column store for active data.
LinkedIn Databus is a source-agnostic distributed change data capture system.
It feeds changes from source-of-truth systems to downstream applications to build specialized storage and indexes for different purposes.
Wildfire and SnappyData are two more recent HTAP systems designed to use the Spark computational engine.
Wildfire combines SparkSQL with the Wildfire storage system that uses columnar data organization built on Parquet.
SnappyData also uses the Spark. It used Apache Gemfire as its storage layer.
4. System Overview
The system has three main parts:
An OLTP database that acts as the source of truth and exposes a change data capture or other change replay interface.
F1 Query is a distributed SQL query engine.
Lightning which maintains and serves read-optimized replicas.
There are two primary OLTP databases at Google, F1 DB and Spanner.
F1 Query is a federated query engine that executes queries written in a dialect of SQL. Users can write queries that seamlessly join across these systems, and F1 Query executes more than 100 billion queries per day on behalf of users and applications.
There is a natural tension between optimizing for analytic queries and optimizing for transaction processing.
In general, F1 DB and Spanner optimize for OLTP workloads like writes and point-lookup queries by using efficient row-oriented storage and indexes, and users design their schemas to maximize write throughput.
F1 Query can run analytical queries over these datasets, but analytical query performance directly on this data is often suboptimal.
Some teams set up pipelines for copying F1 DB tables into ColumnIO files or other formats for further analysis. It is not the right approach.
Lightning replicates data from an OLTP database into a format optimized for analytical queries.
Database owners can enable Lightning on a table-by-table basis or the entire database.
For each enabled table, Changepump, a Lightning component, uses the change data capture mechanism exposed by the database.
Changepump then forwards those changes to partitions managed by individual Lightning servers.
Each Lightning server maintains Log-Structured Merge (LSM) trees backed by a distributed file system.
When Lightning ingests these changes, it transforms the change data from the row-oriented, write-optimized format into a column-oriented format optimized for analysis.
Lightning supports asynchronous maintenance of additional structures like secondary indexes and rollups. It improves query performance without impacting transaction throughput.
F1 DB and Spanner support MVCC using timestamps. Lightning retains its original commit timestamp.
Lightning guarantees that readings at a specific timestamp will produce results identical to those read against the OLTP database at the same timestamp.
If a query requests to read F1 DB and Spanner at a particular timestamp, if that data is available in Lightning, the query will instead read from Lightning.
A single query can read some tables from Lightning and other tables directly from the OLTP database.
Lightning helps by providing the following:
Improved resource efficiency and latency for analytic queries
Simple configuration and deduplication
Transparent user experience
Data consistency and data freshness
Data security
Separation of concerns
Extensibility
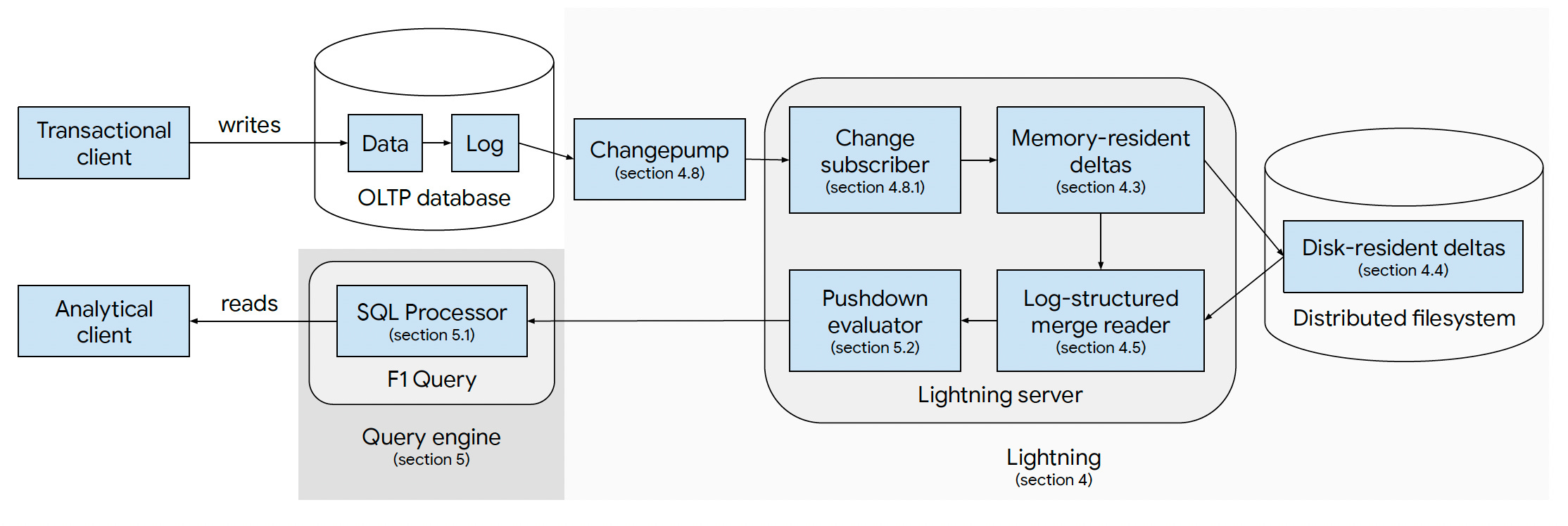
5. Lighting Architecture
Lightning has the following components:
Data storage: It is responsible for continuously applying changes to the Lightning replica. It creates read-optimized files stored in a distributed file system. It provides an API that allows query engines to read stored data with semantics identical to the OLTP database and handles background maintenance operations like data compaction.
Change replication: It is responsible for tailing a transaction log provided by the OLTP database and partitioning changes for distribution to relevant data storage servers. It is also responsible for tracking which changes have been applied, replaying historical changes as needed, and triggering backfills when new tables are added.
Metadata database: The data storage and change replication components state is stored in a metadata database.
Lightning masters: Lightning masters coordinate actions across the other servers and maintain Lightning-wide state.
5.1 Read semantics
Lightning supports multi-version concurrency control with snapshot isolation.
All queries against Lightning-resident tables specify a read timestamp.
Lightning returns data consistent with the OLTP database as of that timestamp because it has the database's original commit timestamp.
There may be a delay before a change made in the OLTP database is visible to queries over Lightning.
The timestamps that can be queried through Lightning are called safe timestamps.
The maximum safe timestamp indicates that Lightning has ingested all changes up to that timestamp.
The minimum safe timestamp indicates the timestamp of the oldest version that can be queried.
The range of safe timestamps is the queryable window.
5.2 Tables and deltas
Lightning stores data organized into Lightning tables.
Database tables, indexes, and views are treated as physical tables in Lightning.
Each Lightning table is divided into a set of partitions using range partitioning.
Each partition is stored in a multi-component Log-Structured Merge (LSM) tree.
Each component of the LSM tree is called a delta. Deltas contain partial row versions for their corresponding Lightning table. Each partial row version is identified by the primary key of the corresponding row and the OLTP commit timestamp.
There are three types of versions.
Inserts: It contains values for all columns. The first version of each row is an insert.
Updates: It contains values for at least one non-key column, and it omits values for columns that were not modified.
Deletes: It does not contain any values for non-key columns. Deletes are used as tombstones to indicate that rows should be removed from reads after a specific timestamp.
5.3 Memory-resident deltas
The partial row versions created during ingestion are first written to a memory-resident, row-wise B-tree.
It allows for high update rates at the cost of some read efficiency.
A memory-resident delta has at most two active writers, with many readers.
Lightning uses a thread for each partition to apply new changes from the OLTP transaction log.
A garbage collection process removes versions that are no longer in Lightning’s queryable window.
Once data is written to a memory-resident delta, it is immediately available for querying, subject to the consistency protocol provided by Changepump.
In the case of system failure, changes stored in memory may be lost. Lightning recovers from this state by replaying from the OLTP database's log.
5.4 Disk-resident deltas
The disk-resident deltas contain the bulk of Lightning’s data and are stored in read-optimized columnar files.
Lightning supports several internal columnar file formats, and it has a common interface that allows It to use many different file formats to store deltas.
Each delta file stores two parts: a data part and an index part.
The data part stores row versions in a PAX (Partition Attributes) layout where rows are first divided into row bundles and then stored column-wise within a row bundle.
The index part contains a sparse B-tree index on the primary key where the leaf entry tracks the key range of each row bundle.
This layout obtains a good balance between range scan performance and point lookup performance.
5.5 Delta merging
Lightning stores partial row versions that may be scattered across several deltas.
Each read must merge deltas and combine row versions in order to form complete rows.
Delta merging consists of two logical operations: merging and collapsing.
Lightning first enumerates the deltas that need to participate in the merge.
Merging deduplicates changes in the source deltas and copies distinct versions to the new delta. It also performs schema coercion if required.
Collapsing combines multiple versions of the same key into a single version.
Lightning performs a k-way merge in two stages that are applied repeatedly: merge plan generation and merge plan application.
In merge plan generation, Lightning reads a block of keys from each k input and identifies which versions to collapse and in which order in a structure. This process is called a merge plan.
After generating the merge plan, Lightning applies it column-by column, copying and aggregating row values into the appropriate buffers. Lightning then flushes the output buffer and uses the escrow buffer as an additional input in the next round.
The above process repeats with additional rounds until all inputs are exhausted.
5.6 Schema management
Lightning monitors the source database schema changes and automatically applies changes with minimal data movement and processing.
To achieve this, Lightning uses a two-level schema abstraction.
The first level is the logical schema, which maps from the OLTP schema into a Lightning table schema.
Lightning generates one or more physical schemas for a particular logical schema. The physical schema contains only primitive types, such as integers, floats, and strings. Lightning’s file format interface operates only at the level of the physical schema.
Logical schemas and physical schemas are connected via a logical mapping.
Data is converted from logical rows to physical rows during ingestion and back again at read time as part of the LSM stack. See the example below:

Whenever a schema change occurs, Lightning creates a new logical schema. Deltas created after the schema change was natively written using the new physical schema.
For old deltas, Lightning analyzes the differences between the original and new logical schemas to construct schema-adapted logical mappings.
At read time, the LSM stack applies the schema-adapted mappings to convert to the expected schema seamlessly.
5.7 Delta compaction
Lightning is constantly ingesting changes and creating new deltas.
Lightning runs periodic delta compaction operations to rewrite smaller deltas into a single larger delta.
Lightning runs four types of delta compaction: active compaction, minor compaction, major compaction, and base compaction.
Active compaction performs delta compaction on memory-resident deltas.
Minor compaction and major compaction run compaction on multiversion disk-resident deltas.
Base compaction generates a new data snapshot at a timestamp before the minimum queryable timestamp.
5.8 Change replication
Changepump provides a unified interface across different transactional sources.
Changepump provides several benefits for Lightning.
It hides the details of individual OLTP databases from the rest of the system.
It adapts from a transaction-oriented change log into a
partition-oriented change log.
It is responsible for maintaining transactional consistency.
Subscriptions :
Individual Lightning servers manage many partitions for many different tables. For each partition, Lightning maintains a subscription to Changepump.
The subscription specifies the partition’s table and key range. Subscriptions have a start timestamp. Changepump will only return changes that commit after that timestamp.
Change data:
Changepump subscriptions return two kinds of data: change updates and checkpoint timestamp updates.
Change updates contain change rows in the subscribed table key ranges. Each change row includes the row’s primary key, the values modified in the transaction, and the operation (insert, update, delete). Changes from the same primary key are delivered in ascending timestamp order.
Schema changes
Lightning uses two mechanisms to detect schema changes: lazy detection and eager detection.
For lazy detection, the system simply checks each change to see if it refers to a schema that Lightning has not previously seen. The system then pauses change processing for that partition until it has loaded and analyzed the new schema.
In the eager detection model, a background thread polls the OLTP database to see if any new schema changes have occurred.
Sharding
Changepump is implemented as a shared service where many servers handle a single change log.
A single subscription may internally connect to multiple Changepump servers.
The Changepump client library merges multiple such connections into a single change stream.
Changepump also exploits physical data locality in the change log to reduce the cost of reading changes for multiple tables.
Caching
Changepump servers also contain a memory-resident cache of recent change records. This cache improves change delivery throughput and reduces expensive I/O operations on the OLTP database’s change log.
Secondary indexes and views
Lightning also maintains secondary indexes and materialized views containing single-table aggregates to replicate base tables, which are considered derived tables.
Instead of subscribing to changes from Changepump servers, partitions for derived tables subscribe to changes from a generated“change log.”
The Lightning servers write this change log to maintain partitions of the base table. Whenever the base table changes, the Lightning servers will compute and emit the relevant changes for each derived table.
Online repartitioning
Lightning may need to repartition existing tables to ensure an even load across all partitions.
Lightning supports dynamically changing the range partitioning on Lightning tables to facilitate this.
The range repartitioning scheme is mostly a metadata-only operation.
Lightning splits a partition:
When the total size of a partition becomes much larger than the target partition
When the write load approaches the ingestion bandwidth of a single partition.
5.9 Fault tolerance
5.9.1 Coping with Query Failures
There are two kinds of common query-time failures.
A server assigned to read a partition cannot be reached due to scheduled
or unplanned server maintenance.
The assigned server hits errors reading data from the storage due to transient network or I/O hiccups.
Lightning assigns each partition to more than one Lightning server in a data center.
Only one of the replicas will transpose memory-resident deltas to disk-resident columnar deltas to avoid duplicate work.
These server replicas can serve queries as they all hold the complete state.
5.9.2 Coping with ingestion failures
If a single Changepump server fails, it is handled by connecting to a different Changepump server in the same data center.
Changepump uses a load-balancing channel to connect to the OLTP system’s CDC component.
When it detects an unhealthy region, the channel redirects Changepump to read from another healthy region of the OLTP system.
5.9.3 Table-level failover
Lightning supports a table-level blacklisting mechanism.
When a table is blacklisted, F1 Query will automatically service queries over that table using the data stored in the OLTP database instead of Lightning.
Lightning runs an offline verifier that continuously checks the consistency of the Lightning replica with the data stored in the OLTP database.
If data corruption is detected, Lightning can blacklist the affected table to prevent queries from returning incorrect results.
6. F1 Query Integration
This topic is covered in detail in the Google F1 Query paper post.
8. Conclusions
The team believed in a perspective with the following points:
The system should have the ability to improve HTAP performance over multiple OLTP systems transparently.
It should do this without modifying the OLTP systems or migrating users to new ones, It should working seamlessly with an existing federated query engine.
It should support geo-replicated operations with stringent correctness and performance requirements.
F1 Lighting was built with all the above.
References
Spark SQL: Relational data processing in Spark
Parallel Replication across Formats in SAP HANA for Scaling Out Mixed OLTP/OLAP Workloads
SnappyData: A Unified Cluster for Streaming, Transactions, and Interactive Analytics