
Insights from paper: Google F1 Query: Declarative Querying at Scale

1. Abstract
At its core, F1 Query is a query-processing platform.
Now, let’s talk about the additional fantastic capabilities it has.
It is stand-alone and federated. So what is federated?
Federated means it can run queries against data stored in different systems, such as file-based or OLTP databases (Google Bigtable and Google Spanner).
F1 Query eliminated the need to maintain the traditional distinction between different types of data processing workloads.
F1 supports:
OLTP-style point queries that affect only a few records
Low-latency OLAP querying of large amounts of data
Large ETL pipelines
F1 Query doesn't need data processing pipelines. Now, you can write declarative queries with custom business logic.
This paper presents the end-to-end design of F1 Query. This system has evolved out of Google F1 DB.
2. Introduction
F1 Query is a SQL query engine that covers all enterprise data processing and analysis requirements.
Initially, the engine executed SQL queries against data stored in only two sources: Google Spanner and Google Mesa.
F1 Query re-implements functionality that is already present in commercial DBMS solutions. It also shares design aspects with Google Dremel.
F1 Query’s main innovation is combining all those existing ideas and disaggregating query processing from data storage.
The critical requirements for the system are as follows:
Data Fragmentation: The underlying data for even a single application is often
fragmented across several storage systems. The system should support handling all these types of systems.
Datacenter Architecture: The system should handle data centers instead
of individual servers or tightly-coupled clusters. It should decouple database storage from query processing.
Scalability: The system should support short queries, which can be executed on a single node, and more significant queries that need low-overhead distributed execution.
Extensibility: The clients should be able to use the system for any data processing needs, including those not easily expressible in SQL or requiring access to data in new formats.
3. Overview Of F1 Query
The diagram below displays the basic architecture and communication among components within a single data center.

Users interact with F1 Query through its client library.
It sends requests to one of several dedicated servers called F1 servers.
There is an F1 Master server within the data center. It is responsible for monitoring query execution run-time and maintaining all F1 servers at that data center.
Small queries and transactions begin executing on the requested F1 server.
Larger queries are distributed for execution by dynamically provisioning execution threads on workers from a worker pool. It is called batch execution mode. Final results are collected on the F1 server and returned to the client.
F1 servers or workers are stateless, so adding new ones does not trigger data redistribution costs.
3.1 Query Execution
F1 server first parses and analyzes the SQL query, then extracts the list of all data sources and sinks that the query accesses.
Suppose the required data sources or sinks are unavailable in the requested data center. In that case, the F1 server returns the query to the client with information about the optimal set of data entries for running the query.
Query execution begins on the F1 server with a planning phase.
In this phase, the optimizer converts the analyzed query abstract syntax tree(AST) into a DAG of relational algebra operators. The DAG is optimized at both logical and physical levels.
The final execution plan is then handed off to the execution layer.
The queries are executed in interactive or batch mode. For all phases, see the diagram below.

For interactive execution, the query optimizer applies heuristics to choose between single-node centralized execution and distributed execution.
In centralized execution, the server analyzes, plans, and executes the query immediately at the first F1 server that receives it.
In distributed mode, the first F1 server to receive the query acts only as the query coordinator. That server schedules work on separate workers, who execute the query together.
The F1 server stores plans for queries running under batch mode in a separate execution repository.
3.2 Data Sources
F1 servers and workers can access data from any other Google data center.
The disaggregation of processing and storage layers enables data retrieval from various sources.
The source ranges from distributed storage systems like Spanner and Bigtable to ordinary files like comma-separated value text files (CSV), record-oriented binary formats, and compressed columnar file formats such as ColumnIO and Capacitor.
F1 Query abstracts away the details of each storage type to support queries over heterogeneous data sources. It makes all data appear as if it is stored in relational tables and enables data to be joined in different sources.
F1 Query also allows for querying sources that are unavailable through the global catalog service. For such cases, the client must provide a DEFINE TABLE statement.
Example statement
DEFINE TABLE People(
format = ‘csv’,
path = ‘/path/to/peoplefile’,
columns = ‘name:STRING,
DateOfBirth:DATE’
);
SELECT Name, DateOfBirth FROM People
WHERE Name = ‘John Doe’;3.3 Data Sinks
The output of queries can be returned to the client.
A query can also request that its output be stored in an external data sink.
Sinks may be files or remote storage services.
Sinks may also be tables managed by the catalog service or manually specified targets. A CREATE TABLE statement creates managed tables.
3.4 Query Language
F1 Query complies with the SQL 2011 standard and supports standard SQL features, including left/right/full outer joins, aggregation, table and expression subqueries, WITH clauses, and analytic window functions.
It also supports querying nested structured data.
F1 Query supports variable-length ARRAY types and STRUCTs, largely similar to SQL standard row types.
F1 Query also provides support for Protocol Buffers.
4. Interactive Execution
F1 Query executes queries in a synchronous online mode called interactive execution by default. F1 Query supports two types of interactive execution modes: central and distributed.
During the planning phase, the optimizer analyzes the query and determines whether to execute it in central or distributed mode.
In central mode, the current F1 server executes the query plan immediately using a single execution thread.
In distributed mode, the current F1 server acts as the query coordinator. It schedules work on other processes known as F1 workers, who then execute the query in parallel.
4.1 Single Threaded Execution Kernel
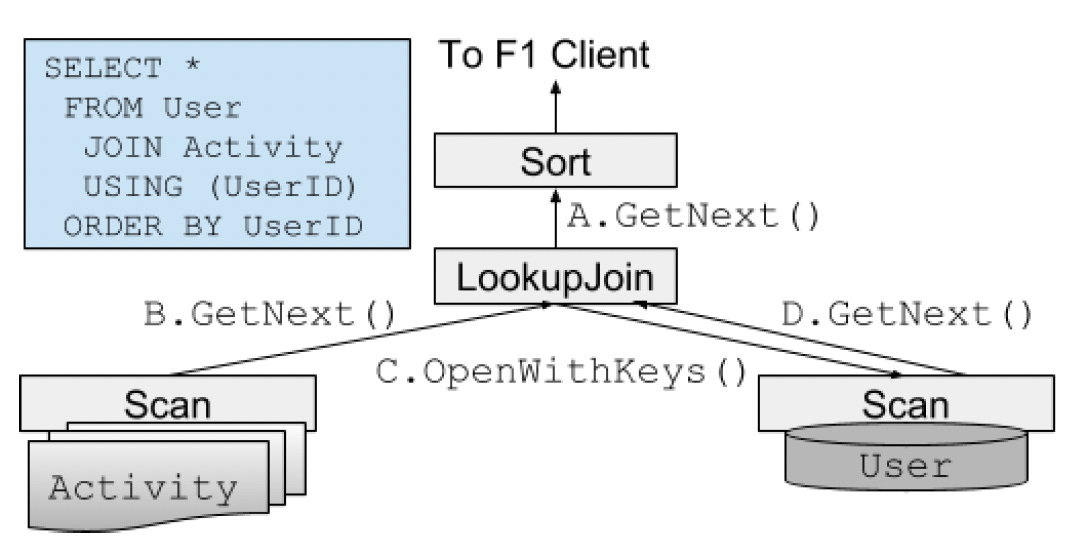
The diagram above depicts an SQL query and the resulting query plan for central mode execution. F1 Query uses a single-threaded execution kernel.
The rectangular boxes shown are operators within the execution plan. The model processes tuples in batches of 8 KiB using a recursive pull.
The execution operators recursively call GetNext() on the underlying operators until the leaf operators retrieve batches of tuples. The leaves are typically Scan operators that read from data sources.
Each data source has its scan operator implementation. F1 Query supports several join operators, including lookup join (index nested-loop join), hash join, merge join, and array join.
F1 Query has operators for projection, aggregation (sort-based and disk spilling), sorting, unioning, and analytic window functions.
4.2 Distributed Execution
The optimizer generates a distributed execution plan when it detects that such a plan is best for scanning the input tables with high parallelism using partitioned reads.
In this case, the query execution plan is split into query fragments, as shown in the diagram below:

Each fragment is scheduled on a group of F1 worker nodes. The fragments execute concurrently. The worker nodes are multi-threaded; some may execute multiple independent parts of the same query.
The optimizer employs a bottom-up strategy to compute the plan fragment boundaries based on the input distribution requirements of each operator in the query plan.
The next step is to select the number of parallel workers for each fragment. Fragments operate with independent degrees of parallelism.
4.3 Partitioning Strategy
F1 Query executes multiple fragments in parallel in distributed mode.
The execution and data flow can be viewed as a DAG, as shown in the previous diagram.
The data moves across each fragment boundary by repartitioning using an exchange operator. For each tuple, the sender applies a partitioning function to determine the destination partition for that tuple. Each partition number corresponds to a specific worker in the destination fragment.
The query optimizer plans each scan operator as a leaf in the query execution plan along with a desired parallelism of N workers.
To execute a scan in a parallelized way, the work must be distributed so that each scan worker produces a non-overlapping subset of the tuples, and all the workers together produce the complete output.
Some operators are executed in the same plan fragment as one of their inputs, and some need multiple fragments.
In the diagram below, executing a hash join requires multiple fragments.
The aggregation operator generally requires a repartitioning.
For aggregation with grouping keys, the query plan repartitions the input tuples by a hash of the grouping keys. It sends these tuples to a destination fragment with the aggregation operator.
All tuples are sent to a single destination for aggregation without grouping keys.
5. Batch Execution
The large-scale transformations typically process ETL (Extract-Transform-Load) workflows.
F1 Query added a new mode of execution called batch mode. Batch mode allows long-running queries to execute reliably even when an F1 server or worker fails.
F1 Query batch mode shares the exact query specification, query optimization, and execution plan generation components with the two interactive modes.
The key difference between the modes happens during execution scheduling.
In the interactive modes, the query executes synchronously.
In batch mode, the F1 server asynchronously schedules the query for execution. A central registry records the query's progress.
5.1 Batch Execution Framework
Batch mode uses the MapReduce (MR) framework as its execution platform. At a very high level, each plan fragment in a query plan can be mapped to a MapReduce stage.
The leaf nodes are abstracted as a map operation, while internal nodes are abstracted as a reduced operation.
Each stage in the processing pipeline stores its output in the Colossus/GFS file system.
In batch mode, intermediate data is sent into staging files, read back, and fed into the next plan fragment.
In distributed interactive mode, every node in the query execution plan is live simultaneously, allowing for parallelism through pipelining.
5.2 Batch Service Framework
The F1 Query batch mode service framework orchestrates the execution of all batch mode queries.
It is responsible for registering incoming queries for execution, distributing queries across different data centers, and scheduling and monitoring the associated MapReduce processing.

The diagram above shows the service framework architecture.
When an F1 Client issues a query for running in batch mode, one of the F1 servers receives it.
It then generates an execution plan and registers the query in the Query Registry.
The Query Distributor component of the service then assigns the query to a data center.
The query is then picked up by the framework components that run in the target data center.
Each data center has a Query Scheduler that periodically retrieves newly assigned queries from the Query Registry and creates a dependency graph of the query execution tasks.
When a task is ready to execute, and resources are available, the scheduler sends it to a Query Executor.
The Query Executor then uses the MapReduce worker pool to execute the task.
6. Query Optimizer Framework
F1 Query uses the same logic to plan all queries regardless of the execution mode, which helps reduce the framework's complexity.

The diagram above shows the structure of the F1 Query optimizer at a high level.
The first step is to call Google’s SQL resolver to parse and analyze the original input SQL and produce a resolved abstract syntax tree (AST).
The optimizer’s work starts from here.
It translates each such AST into a relational algebra plan.
Several rules are executed on the relational algebra until a fixed-point condition is reached to produce a heuristically determined optimal relational algebra plan.
The optimizer converts the final algebra plan into a physical plan in the next step.
The optimizer completes its work by converting the physical plan into final data structures suitable for query execution and passes them to the query coordinator for execution.
Optimizer Infrastructure
All optimizer stages are based on a common infrastructure layer.
All plan tree structures coming out of it are immutable.
The optimizer has separate tree hierarchies for expressions, logical plans, and physical plans.
The optimizer's generated code enables a domain-specific language (DSL) for query planning. It contains methods to compute a hash for each tree node to compare tree equality.
7. Extensibility
F1 Query is extensible in various ways. It supports custom data sources, user-defined scaler functions (UDAs), and table-valued functions (TVFs).
UDFs can use any data as input and output. Clients may express user-defined logic in SQL syntax.
For compiled and managed languages like C++ and Java, F1 Query integrates with specialized helper processes known as UDF servers.
Each client maintains complete control over their own UDF server release cycle and resource provisioning. The UDF servers expose a common RPC interface that enables the F1 server to find out the details of the functions they export and to execute these functions.
SQL and Lua's scripted functions do not use UDF servers, and no single central repository exists for their definitions. Instead, clients must always supply their definitions as part of the RPC sent to the F1 Query.
7.1 Scalar Functions
F1 query supports scalar UDFs written in SQL, Lua, and as compiled code through UDF servers. SQL UDFs allow users to encapsulate complex expressions as reusable libraries
Example: The Lua UDF below converts a date value encoded as a string into an unsigned integer representing the corresponding Unix time.
local function string2unixtime(value)
local y,m,d = match("(%d+)%-(%d+)%-(%d+)")
return os.time({year=y, month=m, day=d})
end7.2 Aggregate Functions
F1 Query also supports user-defined aggregate functions, which combine multiple input rows from a group into a single result. As with scalar functions, users can define UDAs in SQL, and the query optimizer expands the definition at each call site.
The system also supports hosting UDAs in UDF servers for compiled and managed languages.
The UDF servers are stateless, letting each F1 server distribute requests to many UDF server processes in parallel.
7.3 TableValued Functions
F1 Query exposes table-valued functions (TVF), a framework for clients to build user-defined database execution operators.
They let users consume data and run advanced predictions in a single step.
A TVF can accept entire tables and constant scalar values as input and use those inputs to return a new table as output.
As with UDFs and UDAs, a TVF can be defined using SQL. Such TVFs are similar to parameterized views.
8. Advanced Functionality
8.1 Robust Performance
F1 Query identifies performance robustness as a crucial issue in database query processing.
Robustness requires that performance gracefully degrades in the presence of input sizes, unexpected selectivities, and other factors.
Without graceful degradation, users may see a performance cliff, i.e., a discontinuity in an algorithm or plan's cost function.

For example, the transition from an in-memory quicksort to an external merge sort can increase end-to-end sorting runtime by a factor of two or more once the entire input begins spilling into temporary files. The above diagram is an example of this discontinuity in the performance of the F1 Query sort operation with a cliff.
F1 Query employs robust algorithms to prevent performance cliffs. The principal idea is that instead of using a binary switch at optimization time or at execution time, the execution operator incrementally transitions between modes of operation
8.2 Nested data in Google Protocol Buffers
Protocol Buffers are a structured data format with record types called messages and support for array-valued or repeated fields.
Protocol Buffers have a human-readable text format and a compact, efficient binary representation. They are a first-class data type in the F1 Query data model and SQL dialect.
The exact structure and types of all protos referenced in a query are known at query planning time, and the optimizer prunes away all unused fields from data source scans.
For record-oriented data sources that use the row-wise binary format, F1 Query uses an efficient streaming decoder that makes a single pass over the encoded data and extracts only the necessary fields.
9. Related Work
There has been much work on distributed query processing in research.
SDD-1 (A System for Distributed Databases) was initiated at the Computer Corporation of America. System R was initiated at IBM Research.
Similarly, there have been many works in parallel query processing in relational databases.
Unlike distributed query processing, parallel databases have been highly successful.
Large DBMS vendors have commercialized much of the research carried out in the context of parallel databases.
Commercial DBMS vendors are starting to offer cloud-enabled DBMS solutions that support partitioning over multiple machines in the data center and processing queries against these partitions.
Other parallel databases like Snowflake separate storage from computation.
All these systems are still tightly coupled.
Apache Impala claims to be inspired by Google F1 and decouples storage from computation like F1 Query. It was also created as an analytics query engine from the ground up and supports no OLTP-style queries.
Like F1 Query batch execution mode, systems like Pig Latin, Hive, and Spark implement query processing systems using a batch processing paradigm.
Relational database management systems have long-supported user-defined functions that consume and return values within SQL query execution.
F1 Query disaggregated its UDF servers from the database entirely. It allowed them to be deployed and scaled independently and shared by F1 servers and workers.
9.1 Related Google Technologies
F1 Query has some features in common with externally available Google systems Spanner and BigQuery.
Spanner is a single-focus SQL system operating on a transactional core.
BigQuery is Google’s cloud data warehouse. Dremel serves queries.
PowerDrill is a query engine used at Google for interactive data analysis and exploration.
FlumeJava and Cloud Dataflow are modern replacements for MapReduce that allow pipeline operations to be specified at a higher level of abstraction, similar to Pig Latin.
10. Conclusion and Future Work
The paper demonstrated a query processing system that covers a significant number of data processing and analysis use cases on data stored in any data source.
There is no duplicated development effort for features that would be common in separate systems, such as query parsing, analysis, and optimization.
It ensures that the improvements made once are automatically beneficial to all cases.
F1 Query continues to develop actively to address new use cases and enhance performance.
F1 Query does not yet match the performance of vectorized columnar execution engines as its row-oriented execution kernel.
F1 Query relies on existing caches in the data sources or remote caching layers such as TableCache. To support in-memory or nearly-in-memory analytics, such as those offered by PowerDrill, F1 Query would need to support local caching on individual workers and locality-aware work scheduling.
F1 Query has excellent support for scaling out, and the team is working on techniques to improve how F1 scales in.
References
Impala: A Modern, Open-Source SQL Engine for Hadoop
Google PowerDrill: Processing a Trillion Cells per Mouse Click