
Insights from paper: Photon: A Fast Query Engine for Lakehouse Systems

1. Abstract
Let’s start with the basics. Data lakes are known for storing unstructured data. Data Lakehouse are known for implementing the functionality of structured Data Warehouses on top of Data Lakes.
The above approach has a significant problem for query execution engines. It needs to perform well on the raw uncurated datasets and structured data.
Databricks Photon is a vectorized query engine for Lakehouses that implements a general execution framework to enable efficient raw data processing.
2. Introduction
Today, enterprises store most of their data in scalable, elastic data lakes like Amazon S3, Azure Data Lake Storage, and Google Cloud Storage.
Primarily, the data is stored in Apache Parquet or Delta Lake format.
A curated subset of this data is moved into data warehouses to achieve high performance, governance, and concurrency. This is done to serve the most demanding SQL workloads.
The challenge is that this two-tier architecture is complex and expensive.
Many organizations are moving to Lakehouse, which directly implements data warehouse features such as governance, ACID transactions, and rich SQL support over a data lake.
This paper presents Photon, a vectorized query engine developed at Databricks.
It is designed for Lakehouse workloads that can execute queries written in SQL or Apache Spark’s DataFrame.
There were two challenges in designing Photon:
Challenge 1: Supporting raw, uncurated data
The Lakehouse environment challenges query engines with a greater variety of data.
On one end of the spectrum is the tabular data.
On the other end is the uncurated raw data. This data may be small files with many columns, sparse or large data values, and no helpful clustering or statistics.
An execution engine for the Lakehouse must have a flexible design to deliver good performance on arbitrary uncurated data.
Photon manages this with two design decisions:
vectorized-interpreted model for the engine
Implementation in a native language(C++)
Challenge 2: Supporting existing Spark APIs
Organizations already run a variety of applications over their data lakes.
The team designed Photon to integrate with the Spark engine, accelerating existing workloads with the same semantics as Spark workloads.
So, finally, Photon has to support Spark and SQL workloads.
Photon integrates closely with the Apache Spark-based Databricks Runtime (DBR). DBR is a fork of Apache Spark that provides the same APIs but contains improvements to reliability and performance.
Customers can continue to run their workloads unmodified and obtain the benefits of Photon transparently at the operator level.
Queries can partially run in Photon and fall back to Spark SQL for unsupported operations.
3. Background
3.1 Databricks’ Lakehouse Architecture
Databricks’ Lakehouse platform consists of four main components:
Data Lake Storage: Photon decouples data storage from compute. Customers can choose their low-cost storage provider, such as Amazon S3 or Google Cloud Storage. Photon accesses customer data using connectors. The data is stored in open file formats such as Apache Parquet.
Automatic Data Management: Most Photon customers have migrated their workloads to Delta Lake. In a one-line summary, it is an open-source ACID table storage layer over cloud object stores. You can read more about Delta Lake in my paper post.
Elastic Execution Layer: The diagram below shows Databricks’ execution
layer.

Databricks’ execution layer This layer implements the data plane. All data processing is run in this layer. It is responsible for running both internal queries like clustering and metadata access and external customer queries like ETL jobs, SQL workloads, and machine learning workloads. This layer uses cloud computing VMs on AWS, GCP, or Azure.
UI Layer: This layer is used by customers to interact with their data.
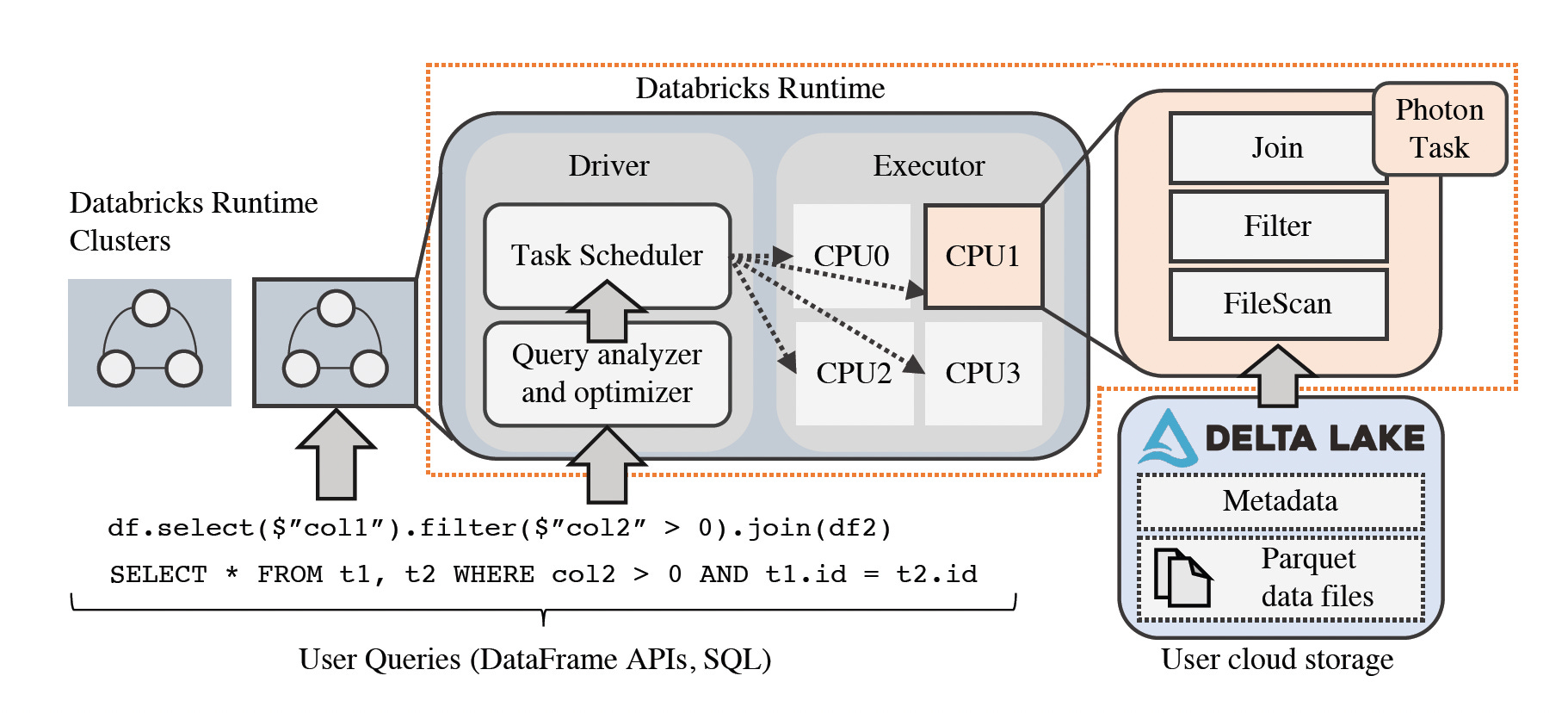
3.2 The Databricks Runtime
The diagram shows that the Databricks Runtime(DBR) executes all queries.
It provides all of Apache Spark’s APIs,
It also contains several performance and robustness improvements on the open-source codebase.
Photon is present at the lowest level of DBR. Photon handles single-threaded task execution within the context of DBR. The DBR is a multi-threaded shared-nothing execution model.
Applications submitted to DBR are called jobs. Each job is broken up into stages.
A stage represents a part of a job that reads one or more files or data exchanges and ends with either a data exchange or a result. The next stage starts after the previous stage ends during execution, so we can call the stages blocking structures.
Stages themselves are broken up into individual tasks. Tasks execute the same code on different partitions of data.
DBR uses a single driver node for scheduling, query planning, and other centralized tasks. The driver node manages one or more executor nodes. Executor nodes run the tasks. As we have seen, DBR is multi-threaded, so independent tasks submitted by the driver can run in parallel.
SQL queries also run in this same execution framework.
The driver can convert SQL text or a DataFrame object into a query plan.
A query plan is a tree of SQL operators like Filter, Project, and Shuffle that maps to a list of stages.
3.3 Example: End-to-end SQL Query Execution
SELECT
upper(c_name), sum(o_price)
FROM
customer, orders
WHERE
o_shipdate > '2021-01-01' AND
customer.c_age > 25 AND
customer.c_orderid = orders.o_orderid
GROUP BY
c_nameThe Databricks service will first route the query to a cluster’s driver node.
The driver is responsible for creating a query plan, including logical optimizations such as operator re-ordering and physical planning such as choosing join strategies.
Consider that the orders table is partitioned by date. In this case, the driver can prune partitions to avoid scanning unnecessary data. If the data is clustered, the driver may be able to skip additional files based on the predicate.
Once the driver chooses the files to scan and finalizes a physical query plan, the driver converts the query plan to executable code via the Apache Spark RDD API.
The Driver sends the serialized code to each executor node.
The executors run this code as tasks on partitions of the input data.
4. Execution Engine Design Decisions
4.1 Overview
The Photon execution engine is implemented in C++.
It is compiled into a shared library and invoked from DBR.
Photon runs as part of a single-threaded task in DBR within an executor’s JVM process.
Internally, Photon structures a SQL query as a tree of operators, where each operator uses a HasNext()/GetNext() API to pull batches of data from its child.
Photon differs from Java operators because it operates over columnar data and implements its operators using interpreted vectorization instead of code generation.
4.2 JVM vs. Native Execution
Based on some observations, the team decided to move away from JVM.
As workloads became CPU-bound, improving the performance of the existing engine became increasingly difficult.
Techniques such as data clustering allow queries to skip unneeded data via file pruning.
Lakehouse has introduced new workloads that require heavy data processing over un-normalized data. It stresses in-memory performance. The in-memory execution by the JVM-based execution engine was becoming more of a bottleneck.
Heaps greater than 64GB in size seriously impacted the garbage collection performance.
4.3 Interpreted Vectorization vs. Code-Gen
Most modern high-performance query engines follow one of two designs:
An interpreted vectorized design like in the MonetDB/X100
A code-generated design like in the Spark SQL, HyPer, or Apache Impala.
The interpreted vectorized engines use a dynamic dispatch mechanism (e.g., virtual function calls).
They choose the code to execute for a given input but process data in batches to enable SIMD vectorization and better utilize the CPU pipeline and memory hierarchy.
The team evaluated both types of native engines and selected vectorized designs based on below points:
Easier to develop and scale
Observability is easier
Easier to adapt to changing data
Specialization is still possible
4.4 Row vs. Column-Oriented Execution
The team selected columnar in-memory data representation in Photon. The paper suggests reading the C-Store paper for detailed analysis. I have written a paper post about it here.
A few more benefits are that Lakehouse interfaces with columnar file formats like Parquet and that dictionaries can be easily maintained to reduce memory usage.
4.5 Partial Rollout
The new engine was required to integrate with both the execution framework and the existing SQL engine.
So, the team designed a system that can partially execute a query in the new engine and then gracefully fall back to the old engine for features that are thus far unsupported.
5. Vectorized Execution in Photon
5.1 Batched Columnar Data Layout
Photon represents data in a columnar data format. Each column value is stored contiguously in memory. The basic unit of data in Photon is thus a single column holding a single batch worth of values, called a column vector.
The column vector holds a byte vector to indicate the NULL-ness of each value.
A column batch is a collection of column vectors, and represents rows as shown in diagram below.

A column batch contains a position list data structure.This stores the indices of the rows in batch that are active.
For the diagram, position list has 0 and 2 so the active data is {10, “hello”} and {null, “photon}.
Data in Photon flows through operators (e.g., Project, Filter), at the granularity of column batches. Each operator receives a column batch from its child and produces one or more output batches.
5.2 Vectorized Execution Kernels
Photon’s columnar execution is built around the concept of execution kernels.
Kernel is a function that execute highly optimized loops over one or more vectors of data. Examples of kernels are expressions, probes into a hash table, serialization for data exchange, and runtime statisticscalculation.
Almost all operations on the data plane are implemented as kernels.
Each kernel takes vectors and the column batch position list as input and produces a vector as output.
template <bool kHasNulls, bool kAllRowsActive>
void SquareRootKernel(const int16_t* RESTRICT pos_list,
int num_rows, const double* RESTRICT input,
const int8_t* RESTRICT nulls, double* RESTRICT result) {
for (int i = 0; i < num_rows; i++) {
// branch compiles away since condition is
// compile-time constant.
int row_idx = kAllRowsActive ? i : pos_list[i];
if (!kHasNulls || !nulls[row_idx]) {
result[row_idx] = sqrt(input[row_idx]);
}
}
}The code above shows an example kernel that computes the square root of a value.
5.3 Filters and Conditionals
Filters in Photon are implemented by modifying the position list of a column batch.
A filtering expression takes column vectors as input and returns a position list as output.
To implement conditional expressions, the position list is modified so only some rows are “turned on”.
5.4 Vectorized Hash Table
Photon’s hash table is optimized for vectorized access.
Lookups to the hash table has three steps.
A hash function is evaluated on a batch of keys using a hashing kernel.
A probe kernel uses the hash values to load pointers to hash table entries
The entries in the hash table are compared against the lookup keys column-by-column, and a position list is produced for non-matching rows. Non-matching rows continue probing the hash table by advancing their bucket index for filled buckets according to the probing strategy.
5.5 Vector Memory Management
Photon allocates memory for transient column batches using an internal buffer pool.
The pool caches allocations and allocates memory using a most-recently-used mechanism.
Variable length datas like strings are managed separately, using an append-only pool that is freed before processing each new batch. Memory used by this pool is tracked by a global memory tracker. It helps in accommodating very large strings.
5.6 Adaptive Execution
Photon can build metadata at runtime about a batch of data and use it to optimize its choice of execution kernel.
Every execution kernel in Photon can adapt to at least two variables: whether there are any NULLs in the batch, and whether there are any inactive rows in the batch.
Photon specializes several other kernels on a case-by-case basis. For example, many string expressions can be executed with an optimized code path if the strings are all ASCII encoded.
6. Integration With Databricks Runtime
Photon co-exists with the old Spark SQL-based execution engine for queries with operators that do not yet support the new execution engine.
6.1 Converting Spark Plans to Photon Plans
Photon converts a physical plan that represents execution using the legacy engine into one that represents execution with Photon.
This transformation is done via a new rule in Catalyst. Catalyst is Spark SQL’s extensible optimizer. A Catalyst rule is a list of pattern matching statements and corresponding substitutions that are applied to a query plan.
The diagram below shows an example:

6.2 Executing Photon Plans
DBR launches tasks to execute the stages of the plan.
Photon execution node first serializes the Photon part of the plan into a Protobuf message. This message is passed via the Java Native Interface (JNI) to the Photon C++ library. The library deserializes the Protobuf message and converts it into a Photon-internal plan.
Adapter node to read Scan data: The leaf node in a Photon plan is always an adapter node. The adapter node takes the columnar data produced by Spark’s scan node and pass the pointers to this data to Photon.
Transition node to pass Photon data to Spark: The last node in a Photon plan is a transition node. It pivot columnar data to row data so the rowwise legacy Spark SQL engine can operate over it.
6.3 Unified Memory Management
Photon and Apache Spark share the same cluster. So they must have a consistent view of memory and disk usage. To achieve this Photon hooks into Apache Spark’s memory manager.
Photon has a concept called reservation. A memory reservation asks for memory from Spark’s unified memory manager.
Photon and Spark both can ask for memory from the memory manager and any available spill can go to any one of these.
Photon use the same policy as open source Apache Spark to determine which operator to spill.
After reserving memory, Photon can allocate memory safely without spilling.
6.4 Managing On-heap vs. Off-heap Memory
Spark cluster is configured with a static off-heap size per node.
The memory manager is responsible for handing out memory from this allocation.
Memory consumer is responsible to only use the memory allocated.
The JVM performs garbage collection when it detects high on-heap memory usage. Photon’s most of the memory usage is off-heap so garbage collection seldom occurs.
7. Related Work
Photon’s vectorized execution model was introduced by MonetDB/X100.
The batch-level adaptivity scheme described in this paper is similar to micro-adaptivity in the Vectorwise system.
HyPer has implemented and evaluated the code generation model.
The Apache Arrow project provides an in-memory format similar to Photon’s column vectors.
8. Conclusion
Photon is a new vectorized query engine for Lakehouse environments that underlies the Databricks Runtime.
Photon’s native design has solved many of the scalability and performance issues with JVM based engines.
Its vectorized processing model enables rapid development, rich metrics reporting, and micro-adaptive execution for handling the unstructured data.
Photon’s incremental rollout has helped organizations in transitioning.
References
Databricks Delta Lake paper post
Lakehouse: A NewGeneration of Open Platforms that Unify DataWarehousing and Advanced Analytics
Spark SQL: Relational Data Processing in Spark
MonetDB/X100: Hyper-Pipelining Query Execution
Micro adaptivity in Vectorwise
HyPer: A Hybrid OLTP&OLAP Main Memory Database system based on virtual memory snapshots