
Insights from Paper: Apache Flink: Stream and Batch Processing in a Single Engine

1. Introduction
Typically, there are two kinds of data processing: stream processing (event processing) and batch processing. These are programmed using two different programming models and APIs and executed by different systems.
Apache Flink follows a paradigm that embraces the above processing using only one single unifying model.This approach will work for real-time analysis, continuous streams, and batch processing on both the programming model and execution engine sides.
Flink’s stream processing programs do not distinguish between processing the latest events in real-time and processing terabytes of historical data. In the same operation, Flink programs can compute both early and approximate results and delayed and accurate results.
Flink supports different notions of time (event time, ingestion time, processing time) to give programmers great flexibility in defining how events should be correlated.
Batch programs are special cases of streaming programs in which the stream is finite, and the order and time of records do not matter.
Flink also has a specialized API for processing static data sets, uses specialized data structures and algorithms for the batch versions of operators like join or grouping, and uses dedicated scheduling strategies.
The contributions of the paper:
The paper argues for a unified stream and batch data processing architecture.
The paper shows how streaming, batch, iterative, and interactive analytics can be represented as fault-tolerant streaming dataflow.
The paper discusses how we can build a full-fledged stream analytics system with a flexible windowing mechanism and a full-fledged batch processor on top of these dataflows.
2. System Architecture
The Flink’s architecture has four main layers: deployment, core, APIs, and libraries.

Flink’s Runtime and APIs
The core of Flink is the distributed dataflow engine, which executes dataflow programs. A Flink runtime program is a DAG of stateful operators connected with data streams.
There are two core APIs in Flink: the DataSet API for processing finite data sets (batch processing) and the DataStream API for processing potentially unbounded data streams (stream processing).
Flink’s core runtime engine can be seen as a streaming dataflow engine, and both the DataSet and DataStream APIs create runtime programs that the engine can execute.
Flink bundles domain-specific libraries and APIs that generate DataSet and DataStream API programs. FlinkML is used for machine learning, Gelly for graph processing, and Table for SQL-like operations.
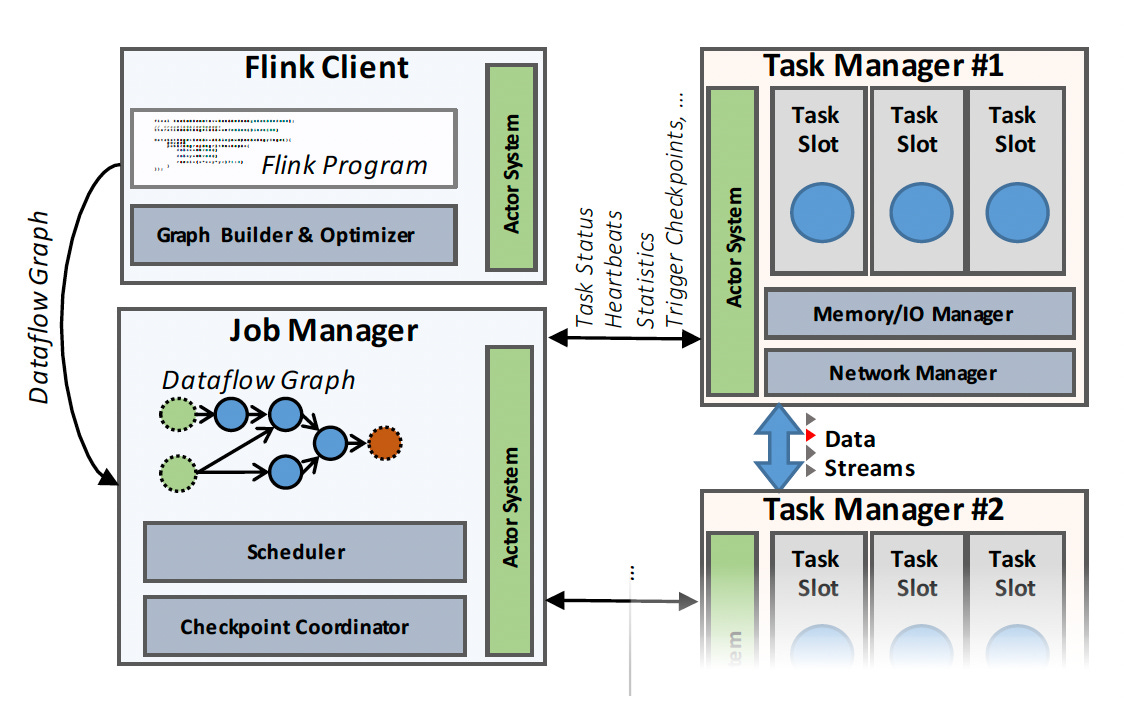
Flink cluster comprises three processes: the client, the Job Manager, and at least one Task Manager.
The client takes the program code, transforms it into a dataflow graph, and submits that to the JobManager.
The JobManager coordinates the distributed execution of the dataflow. It tracks each operator's and stream's state and progress, schedules new operators, and coordinates checkpoints and recovery.
In a high-availability setup, the JobManager persists a minimal set of metadata at each checkpoint to a fault-tolerant storage, such that a standby JobManager can reconstruct the checkpoint and recover the dataflow execution from there.
The actual data processing takes place in the Task Managers. A Task Manager executes one or more operators that produce streams and report their status to the Job Manager.
The TaskManagers maintain the buffer pools to buffer or materialize the streams and the network connections to exchange the data streams between operators.
3. The common Fabric: Streaming Dataflow
Users can write Flink programs using different APIs. All Flink programs eventually compile down to a common representation: the dataflow graph. Flink’s runtime engine executes the dataflow graph.
3.1 Dataflow Graphs
The dataflow graph shown in the diagram below is a directed acyclic graph (DAG) that consists of (i) stateful operators and (ii) data streams that represent data produced by an operator and are available for consumption by operators.
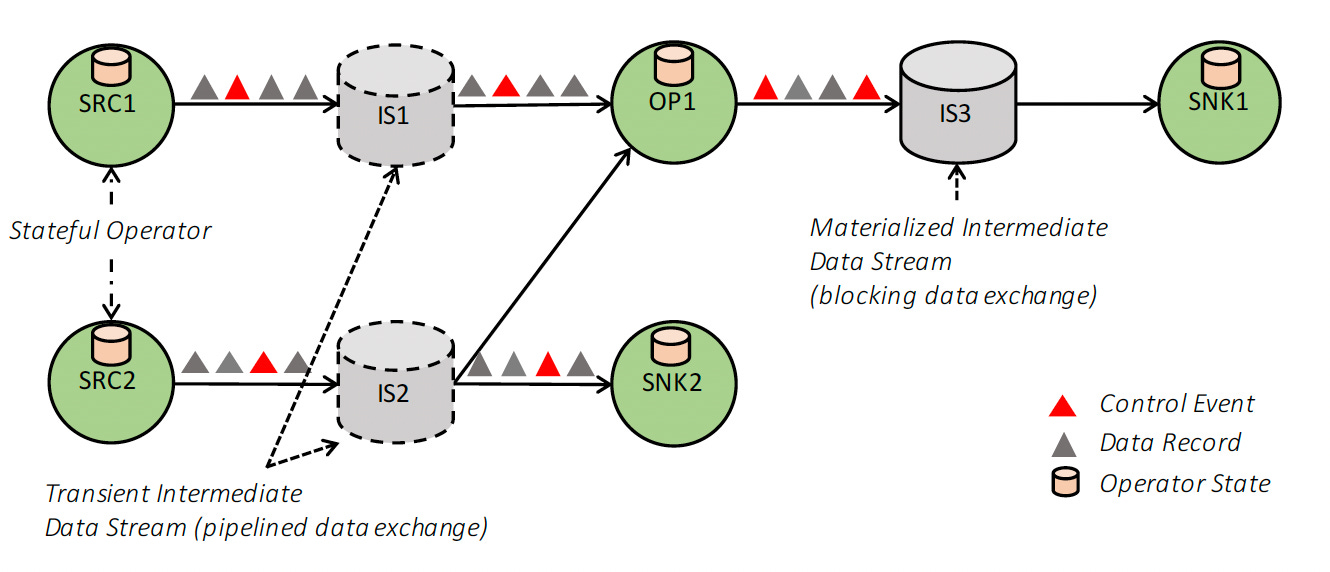
Dataflow graphs are executed in a data-parallel fashion. Operators are parallelized into one or more parallel instances called subtasks, and streams are split into one or more stream partitions (one partition per producing subtask).
Streams distribute data between producing and consuming operators in various patterns, such as point-to-point, broadcast, re-partition, fan-out, and merge.
3.2 Data Exchange
Flink’s intermediate data streams are the core abstraction for operator data exchange. An intermediate data stream represents a logical handle to the data produced by an operator and consumed by one or more operators.
Pipelined Exchange - Flink uses pipelined streams to avoid materialization in continuous streaming programs and many parts of batch dataflows.
Blocked Exchange - Blocking streams are applied to bounded data streams. A blocking stream buffers all of the producing operator’s data before making it available for consumption, separating the producing and consuming operators into different execution stages.
Balancing latency and throughput - The diagram below shows the effect of buffer timeouts on the throughput and latency of delivering records in a simple streaming grep job on 30 machines (120 cores).

Flink can achieve an observable 99th-percentile latency of 20 ms. The corresponding throughput is 1.5 million events per second.
At a buffer timeout of 50 ms, the cluster reaches a throughput of more than 80 million events per second with a 99th-percentile latency of 50 ms.
Control Events
Apart from exchanging data, streams in Flink communicate different types of control events. These are special events injected into the data stream by operators and are delivered in order along with all other data records and events within a stream partition.
The receiving operators react to these events by performing certain actions upon arrival. Flink uses many special types of control events, including checkpoint barriers, watermarks, and iteration barriers.
Fault-Tolerance
Flink offers reliable execution with strict exactly-once-processing consistency guarantees and deals with failures via checkpointing and partial re-execution.
The checkpointing mechanism of Apache Flink builds on the notion of distributed consistent snapshots to achieve exact-once-processing guarantees.
To limit recovery time, Flink regularly snapshots the state of operators, including the current position of the input streams.
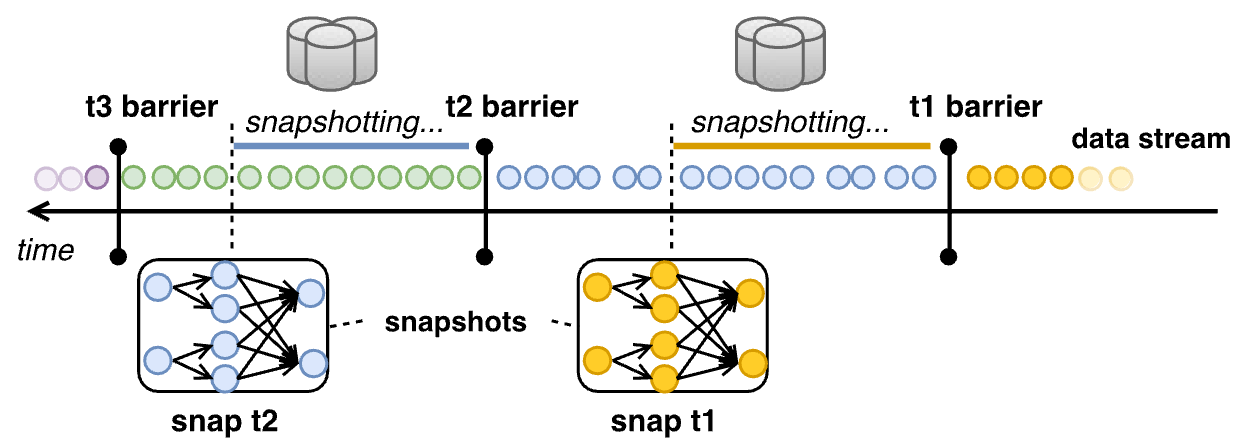
The core challenge lies in taking a consistent snapshot of all parallel operators without halting the execution of the topology. In essence, the snapshot of all operators should refer to the same logical time in the computation.
The mechanism used in Flink is called Asynchronous Barrier Snapshotting. Barriers are control records injected into the input streams that correspond to a logical time and logically separate the stream from the part whose effects will be included in the current snapshot and the part that will be snapshotted later.
An operator receives barriers from upstream and first performs an alignment phase, ensuring that all inputs' barriers have been received. Then, the operator writes its state to durable storage.
The operator forwards the barrier downstream once the state has been backed up. Eventually, all operators will register a snapshot of their state, and a global snapshot will be completed.
Recovery from failures reverts all operator states to their respective states taken from the last successful snapshot. It restarts the input streams starting from the latest barrier for which there is a snapshot.
Partial recovery of a failed subtask is possible by replaying unprocessed records buffered at the immediate upstream subtasks.
Iterative Dataflow
Incremental processing and iterations are crucial for graph processing and machine learning applications.
Support for iterations in data-parallel processing platforms typically relies on submitting a new job for each iteration or adding additional nodes to a running DAG or feedback edges.
In Flink, iterations are implemented as iteration steps with special operators that can contain an execution graph, as shown in the diagram below.

To maintain the DAG-based runtime and scheduler, Flink allows for iteration “head” and “tail” tasks that are implicitly connected with feedback edges.
The role of these tasks is to establish an active feedback channel to the iteration step and provide coordination for processing data records in transit within this feedback channel.
4. Stream Analytics on top of dataflow
Flink’s DataStream API implements a full-stream analytics framework.
These APIs include mechanisms to manage time, such as out-of-order event processing, defining windows, and maintaining and updating user-defined states.
The APIs are based on the notion of a DataStream, a (possibly unbounded) immutable collection of elements of a given type.
Flink’s runtime already supports pipelined data transfers, continuous stateful operators, and a fault-tolerance mechanism for consistent state updates. Overlaying a stream processor on top of it essentially involves implementing a windowing system and a state interface.
Notion of Time
Flink distinguishes between two notions of time:
i) event-time
ii) processing-time
The system regularly inserts special events called low watermarks that mark a global progress measure. The watermarks aid the execution engine in processing events in the correct event order and serializing operations.
Watermarks originate at the sources of a topology, where we can determine the time inherent in future elements. The watermarks propagate from the sources throughout the other data flow operators.
Operators decide how they react to watermarks. Simple operations, such as maps or filters, just forward the watermarks they receive, while more complex operators do calculations based on watermarks.
Stateful Stream Processing
While most of Flink’s DataStream API operators look functional and side-effect-free, they support efficient stateful computations. Depending on the use case, there are many different types of states.
For example, the state can be as simple as a counter or a sum or more complex, such as a classification tree or a large sparse matrix.
Stream windows are stateful operators that assign records to continuously updated buckets kept in memory as part of the operator state.
In Flink, the state is made explicit and is incorporated into the API by providing the following:
i) operator interfaces or annotations
ii) an operator-state abstraction
Users can also configure how the state is stored and checkpointed using the StateBackend abstractions provided by the system.
Flink’s checkpointing mechanism guarantees that any registered state is durable with exactly once update semantics.
Stream windows
Windows are continuously evolving logical views. Any incremental computations over unbounded streams are evaluated over windows.
Apache Flink incorporates windowing within a stateful operator that is configured via a flexible declaration composed of three core functions:
The assigner is responsible for assigning each record to logical windows.
An option trigger defines when the operation associated with the window definition is performed.
An optional evictor determines which records to retain within each window.
Flink’s window assignment process can cover all known window types, such as periodic time-and-count windows, punctuation, landmark, session, and delta windows.
Let’s take an example. In the code below, a sliding window is implemented.
stream
.window(SlidingTimeWindows.of(Time.of(6, SECONDS), Time.of(2, SECONDS))
.trigger(EventTimeTrigger.create())The window has a range of 6 seconds and slides every 2 seconds (the assigner). The window results are computed once the watermark passes the end of the window (the trigger).
5. Batch Analytics on top of dataflow
A bounded data set is a special case of an unbounded data stream.
A streaming program inserting all input data in a window can form a batch program.
Flink approaches batch processing as follows:
The same runtime executes batch computations as streaming computations.
Periodic snapshotting is turned off when its overhead is high.
Blocking operators are simply operator implementations that happen to block until they have consumed their entire input. The runtime is not aware of whether an operator is stopping or not.
A dedicated DataSet API provides familiar abstractions for batch computations, namely a bounded fault-tolerant DataSet data structure and transformations on DataSets (e.g., joins, aggregations, iterations).
A query optimization layer transforms a DataSet program into an efficient executable.
Memory Management
Flink serializes data into memory segments instead of allocating objects in the JVMs heap to represent buffered in-flight data records.
Operations such as sorting and joining operate as much as possible on the binary data directly, keeping the serialization and deserialization overhead at a minimum and partially spilling data to disk when needed.
To handle arbitrary objects, Flink uses type inference and custom serialization mechanisms.
6. Related Work
Apache Hadoop is one of the most popular open-source systems for batch processing. It is based on the MapReduce.
Dryad introduced embedded user-defined functions in general DAG-based dataflows. SCOPE enhanced this idea further.
Apache Tez can be seen as an open-source implementation of the ideas proposed in Dryad.
Apache Drill and Impala restrict their API to SQL variants only.
Apache Spark is a data-processing framework that implements a DAG-based execution engine.
In-stream Processing, many alternatives like SEEP, Naiad, Microsoft StreamInsight, and IBM Streams exist.
Recent approaches, like Apache Storm and Samza, enable horizontal scalability and compositional dataflow operators with weaker state consistency guarantees.
Out-of-order processing (OOP) has recently become famous and is used in Google MillWheel.
7. Conclusion
Apache Flink implements a universal dataflow engine to perform stream and batch analytics.
Flink’s dataflow engine treats operator state and logical intermediate results as first-class citizens. It is used by both the batch and data stream APIs with different parameters.
The streaming API, built on top of Flink’s streaming dataflow engine, provides the means to keep recoverable state and partition, transform, and aggregate data stream windows.
Batch computations are a special case of streaming computations. Flink treats them especially by optimizing their execution using a query optimizer and by implementing blocking operators that gracefully spill to the disk without memory.
References
Dryad: distributed data-parallel programs from sequential building blocks
Incorporating Partitioning and Parallel Plans into the SCOPE Optimizer
Apache Tez: A unifying framework for modeling and building data processing applications
Apache Drill: Interactive Ad-Hoc Analysis at Scale
Apache Impala: A Modern, Open-Source SQL Engine for Hadoop
Samza: stateful scalable stream processing at LinkedIn
Trill: a high-performance incremental query processor for diverse analytics
Out-of-order processing: a new architecture for high-performance stream systems