
Insights from Paper: Google MillWheel : Fault-Tolerant Stream Processing at Internet Scale

1. Abstract
MillWheel is Google’s original, general-purpose stream processing architecture.
It provides low-latency, strongly consistent processing of unbounded, out-of-order data.
MillWheel is used for various problems at Google because it offers a unique combination of scalability, fault tolerance, and a versatile programming model.
Users specify a directed computation graph and application code for individual nodes. MillWheel manages the persistent state and the continuous flow of records.
MillWheel’s programming model provides a notion of logical time, making it simple to write time-based aggregations.
2. Introduction
Streaming systems at Google require fault tolerance, persistent state, and scalability.
Let’s start with the MapReduce programming model for distributed systems. This model hides the framework’s implementation details in the background, allowing users to focus on their system's semantics without needing to be distributed systems experts.
MillWheel is a programming model explicitly tailored for streaming, low-latency systems.
Users write application logic as individual nodes in a directed compute graph, for which they can define an arbitrary, dynamic topology. Records are delivered continuously along the graph's edges.
MillWheel provides fault tolerance. This means any node or edge in the topology can fail without affecting the result's correctness.
MillWheel APIs for record processing handle each record in an idempotent fashion. So, from the user’s perspective, record delivery occurs exactly once.
MillWheel checkpoints its progress at fine granularity. It eliminates any need to buffer pending data between checkpoints.
The challenge with other streaming systems is that they do not provide this combination of fault tolerance, versatility, and scalability.
Spark Streaming and Sonora do excellent jobs of efficient checkpointing, but they limit the number of operators available to user code.
Yahoo S4 does not provide a fully fault-tolerant persistent state.
Trident requires strict transaction ordering to operate.
This paper contributes a programming model for streaming systems and an implementation of the MillWheel framework.
The programming model is designed to allow for the creation of complex streaming systems without the need for distributed systems expertise.
The efficient implementation of the MillWheel framework proves its viability as both a scalable and fault-tolerant system.
3. Motivation and Requirements
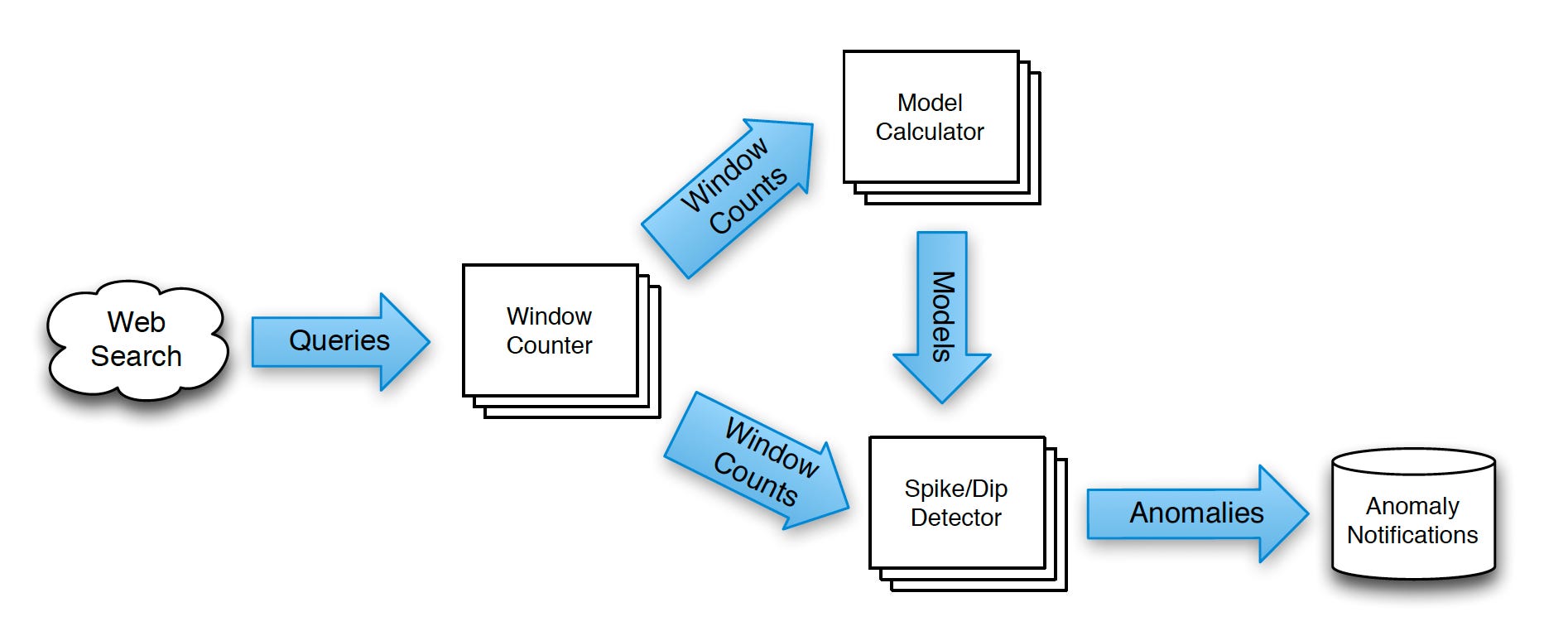
Google has a pipeline that ingests a continuous input of search queries and performs anomaly detection, outputting spiking or dipping queries as quickly as possible.
The system builds a historical model of each query so expected traffic changes will not cause false positives.
This pipeline powers Google’s Hot Trends service.
To implement this pipeline system, the approach is to bucket records into one-second intervals and compare the actual traffic for each time bucket to the expected traffic that the model predicts.
If these quantities consistently differ over a non-trivial number of buckets, we can confidently say that a query is spiking or dipping.
In parallel, we update the model with the newly received data and store it for future use.
Persistent Storage: The implementation requires both short- and long-term storage. A spike may only last a few seconds and thus depend on the state from a small time window, whereas model data can correspond to months of continuous updates.
LowWatermarks: There is a need to detect dips in traffic where the volume for a query is low. For example, the government shuts down the internet in a country. MillWheel addresses this by providing a low watermark for incoming data for each processing stage. It indicates that all data up to a given timestamp has been received.
Duplicate Prevention: Duplicate record deliveries could cause spurious spikes. MillWheel requires exact-once processing.
Considering all these, the following are the requirements for MillWheel:
Data should be available to consumers as soon as it is published.
Persistent state abstractions should be available to user code,
and should be integrated into the system’s overall consistency
model.
The system should handle out-of-order data gracefully.
The system should compute a monotonically increasing low watermark of data timestamps.
Latency should stay constant as the system scales to more machines.
The system should provide exactly once delivery of records.
4. System Overview
So, from the discussion until now, we have had the idea that MillWheel has a graph of user-defined transformations on input data that produces output data.
These transformations are called computations.
Each of these computations can be parallelized across an arbitrary number of machines, such that the user does not have to concern themselves with load-balancing at a fine-grained level.
At an abstract level, we can say the input and output for MillWheel are represented by (key, value, timestamp) triples.
Key: A metadata field with some semantic meaning
Value: An arbitrary byte string corresponding to the record
Timestamp: An arbitrary value by the MillWheel user ( typically, it is a wall clock value)
Example: If a user needs aggregating per-second counts of search terms, then they will assign a timestamp value corresponding to the time at which the search was performed, as shown in the below diagram:

Outputs from one computation become inputs for another, creating a data flow graph.
Users can dynamically add and remove computations from a topology without restarting the system.
A computation can combine, modify, create, and drop records arbitrarily.
There is a delivery guarantee within the MillWheel framework. All internal updates resulting from record processing are atomically checkpointed per key, and records are delivered exactly once. This guarantee does not extend to external systems.
5. Core Concepts
Inside MillWheel, data traverses via a user-defined directed graph of computations. Each computation can emit and manipulate data independently.
Example: Definition of a single node in a MillWheel topology
computation SpikeDetector {
input_streams {
stream model_updates {
key_extractor = ’SearchQuery’
}
stream window_counts {
key_extractor = ’SearchQuery’
}
}
output_streams {
stream anomalies {
record_format = ’AnomalyMessage’
}
}
}Before moving ahead, let’s understand the core concepts inside MillWheel
5.1 Computations
We have discussed that the user provides the application logic, which can contain arbitrary code. When input is received, the user-defined actions in this code are triggered.
There is one crucial point: the code is written to operate in the context of a single key and is agnostic to the distribution of keys among different machines.
The processing is serialized per key, which means that only one record is processed at once for a given key.

5.2 Keys
For every record, the consumer specifies a key extraction function, which assigns a key to the record. Keys are used for aggregation and comparison between different records.
Let’s understand the key using examples.
The query text can be a good key for query records. Using this key, we can aggregate counts and compute models per query.
For a spam detector, a cookie fingerprint can be a key to block abusive behavior.
Also, different consumers can extract different keys from the same input stream based on their needs, as shown below:

5.3 Streams
MillWheel’s delivery mechanism between different computations is Stream.
A computation subscribes to zero or more input streams and publishes one or more output streams. Any computation can subscribe to any stream and produce records for any stream.
MillWheel guarantees delivery along these channels.
Each consumer specifies key-extraction functions on a per-stream basis. Streams are uniquely identified by their names.
5.4 Persistent State
At the lowest level, the persistent state is a byte string that is managed on a per-key basis. The user provides serialization and deserialization methods.
The Persistent state is backed by a replicated, highly available data store like BigTable or Spanner.
5.5 Low Watermarks
Before we discuss the official recursive definition of low watermarks, let’s first understand why it is needed.
We understand that the records will arrive at a computation in the future. So, we need to put a bound on the timestamp of those future records.
Given a computation, A, let the oldest work of A be a timestamp corresponding to the oldest unfinished (in-flight, stored, or pending-delivery) record in A.
Low watermark of A = min(oldest work of A, low watermark of C: C outputs to A)
This means that the low watermark and oldest work values are equivalent if there are no input streams. In case there are input streams, we need to get the minimum of those streams’ low watermarks and the current computation’s oldest work.
Injectors seed low watermark values, which send data into MillWheel from external systems. Measurement of pending work in external systems is often an estimate, so in practice, computations should expect a low rate of late records – records behind the low watermark – from such systems.
Zeitgeist deals with this by dropping such data while tracking how much data was dropped.
By waiting for a computation's low watermark to advance past a specific value, the user can determine that they have a complete picture of their data up to that point.

In the above diagram, the low watermark is the vertical bar. Pending work is displayed above the horizontal line, and finished work is below the horizontal line. The low watermark advances as records move through the system.
5.6 Timers
Timers are per-key programmatic hooks that trigger at a specific wall time or low watermark value. They are created and run in a computation context and can run arbitrary code.
Once set, timers are guaranteed to fire in increasing timestamp order.
They are stored persistently and can survive process restarts and machine failures. When a timer fires, it runs the specified user function and has the same exact-once guarantee as input records.
6. API
Let’s learn the API exposed by MillWheel.
Users implement a custom subclass of the Computation class. This class provides methods for accessing MillWheel abstractions, such as state, timers, productions, etc.
Users only need to provide the code. The framework takes care of running the code and per-key serialization.
6.1 Computation API
There are two main entry points into user code:
ProcessRecord hook and ProcessTimer hook
These are triggered in reaction to record receipt and timer expiration.

The MillWheel system invokes user-defined processing hooks in response to incoming RPCs. User code accesses state, timers, and productions through the framework API. The framework performs any actual RPCs and state modifications.
6.2 Injector and Low Watermark API
Each computation calculates a low watermark value at the system layer for all of its pending work (in-progress and queued deliveries).
Injectors bring external data into MillWheel. Since injectors seed low watermark values for the rest of the pipeline, they can publish an injector low watermark that propagates to any subscribers among their output streams, reflecting their potential deliveries along those streams.
7. Fault-Tolerance
7.1 Delivery Guarantees
The biggest conceptual simplicity of MillWheel’s model is that it takes non-idempotent user code and runs it as if it were idempotent.
7.1.1 Exactly-Once Delivery
MillWheel framework performs the following steps on receiving an input record for a computation:
The record is checked against deduplication data from previous deliveries; duplicates are discarded.
User code is run for the input record, possibly resulting in pending changes to timers, state, and productions.
Pending changes are committed to the backing store.
Senders are ACKed.
Pending downstream productions are sent.
Deliveries in MillWheel are retried until they are ACKed to meet at least one requirement, a prerequisite for exactly once.
The system assigns unique IDs to all records at production time. MillWheel identifies duplicate records by including this unique ID for the record in the same atomic write as the state modification.
If the same record is later retried, MillWheel can compare it to the journaled ID, discard it, and ACK the duplicate.
MillWheel maintains a Bloom filter of known record fingerprints to provide a fast path for records that have probably never been seen before.
In case of a filter miss, MillWheel must read the backing store to determine whether a record is a duplicate.
7.1.2 Strong Productions
MillWheel handles inputs that are not necessarily ordered or deterministic.
MillWheel checkpoint produced records before delivery in the same atomic write as state modification. This pattern of checkpointing before record production is called strong productions.
MillWheel uses a storage system, Google Bigtable, which efficiently implements blind writes (as opposed to read-modify-write operations), making checkpoints mimic the behavior of a log.
When a process restarts, the checkpoints are scanned into memory and replayed. Checkpoint data is deleted once these productions are successful.
7.1.3 Weak Productions and Idempotency
There are some computations that are already idempotent, regardless of the presence of exactly-once and Strong Productions guarantees we just discussed.
Strong productions and/or exactly once can be disabled by the user at their discretion.
For weak productions, rather than checkpointing record productions before delivery, MillWheel broadcasts downstream deliveries optimistically before the persisting state.
This can significantly increase end-to-end latency for straggler productions as pipeline depth increases. MillWheel takes care of this by checkpointing a small percentage of straggler pending productions.

7.2 State Manipulation
MillWheel needs to satisfy the following user-visible gurantees.
The system does not lose data.
Updates to state must obey exactly-once semantics.
All persisted data throughout the system must be consistent at any given point in time.
Low watermarks must reflect all pending states in the system.
Timers must fire in-order for a given key.
To avoid inconsistencies in the persisted state, MillWheel wraps all per-key updates in a single atomic operation.
A significant threat to data consistency is the possibility of zombie writers and network remnants issuing stale writes to the backing store.
MillWheel attaches a sequencer token to each write, and the mediator of the backing store checks for validity before allowing the write to commit.
The sequencer functions as a lease enforcement mechanism. It guarantees that only a single worker can write to a given key at a particular point in time.
To quickly recover from unplanned process failures, each computation worker in MillWheel can checkpoint its state at an arbitrarily fine granularity.
8. System Implementation
8.1 Architecture
MillWheel deployments run as distributed systems on a dynamic set of host servers.
Each computation in a pipeline runs on one or more machines, and streams are delivered via RPC. The MillWheel system marshals incoming work at each machine and manages process-level metadata, delegating computation to the appropriate user as necessary.
There is a replicated master for load distribution and load balancing.Load is divided for each computation into a set of lexicographic key intervals, which are then assigned to a set of machines.
These intervals can be moved around, split, or merged based on the need.
MillWheel uses a database like Bigtable or Spanner as a persistent store.
Timers, pending productions, and persistent state for a given key are all stored in the same row in the data store. Whenever a key interval is assigned to a new owner, MillWheel recovers data by scanning metadata from the persistent store.
8.2 Low Watermarks
It is essential that low watermarks are implemented as a sub-system that is globally available and correct.
MillWheel has implemented this as a central authority. It tracks all low watermark values in the system and journals them to a persistent state, preventing the reporting of erroneous values in cases of process failure.
Each process aggregates timestamp information for all its owned work and reports to the central authority. Since processes are assigned work based on key intervals, low watermark updates are bucketed into key intervals before and sent to the central authority.
The central authority tracks the completeness of process information from all machines for each computation by building an interval map of low watermark values for the computation.
Central Authority broadcasts low watermark values for all computations in the system. To maintain consistency at the central authority, MillWheel attachs sequencers to all low watermark updates.
9. Related Work
The motivation for building a general abstraction for streaming systems was heavily influenced by MapReduce and Hadoop.
At the time of MillWheel building, Yahoo! S4, Twitter Storm, and Microsoft Sonora were insufficiently general for Google’s desired class of problems.
S4 and Sonora do not address exactly once processing and fault-tolerant persistent state. Google’s Percolator targets incremental updates to large datasets but expects latencies in the order of minutes.
MillWheel fulfills the requirements for a streaming system as enumerated by Stonebraker.
MillWheel’s concept of low watermarks is similar to the low watermarks defined in Out-of-order processing.
Much of the inspiration for streaming systems can be traced back to the pioneering work done on streaming database systems, such as TelegraphCQ and Aurora.
References
Aurora: a new model and architecture for data stream management
Telegraphcq: continuous dataflow processing
Yahoo S4: Distributed stream computing platform
Stonebraker: The 8 requirements of real-time stream processing