
Insights from paper: Google Dremel: A Decade of Interactive SQL Analysis at Web Scale

1. Introduction
Google Dremel is a distributed system for interactive data analysis. The first paper was published in 2010. You can read my post on that paper here.
Google launched BigQuery the same year, which was powered by Dremel.
Today, BigQuery is a fully managed, serverless data warehouse that enables scalable analytics over petabytes of data.
This paper focuses on Dremel’s key ideas and architectural principles. The main ideas are as follows:
SQL: All data platforms have embraced SQLstyle APIs.
Disaggregated compute and storage: The industry has converged on an architecture that decouples computing from storage so each can scale independently.
In situ analysis: Compute engines can use a data lake to curate it or execute complex SQL queries and store the results.
Serverless computing: The industry offers on-demand resources that provide extreme elasticity.
Columnar storage: Encoding of nested data for general applicability of column stores.
2. Embracing SQL
Google pioneered Big Data in the early 2000s. GFS and MapReduce became the standard ways to store and process huge datasets. NoSQL storage systems such as BigTable also became the default for managing transactional data at scale.
The conventional wisdom at Google was that “SQL doesn’t scale.” With a few exceptions, Google had almost completely abandoned SQL then.
Dremel was one of the first systems to reintroduce SQL for Big Data analysis. It made it possible for the first time to write a simple SQL query to analyze web-scale datasets, a paradigm shift for data analysis.
Hierarchical schemas in Dremel were a big departure from typical SQL schema design.
In parallel, F1 DB emerged, and again, SQL was at the center of transactional Big Data systems at Google.
F1 was built as a hybrid of a traditional SQL database and a massively distributed storage system like BigTable. Ads and other teams moved to F1, and Google teams started seeing the movement from NoSQL to SQL.
Today, Spanner is everywhere in Google, but you will be surprised that most of its transactional database functionality came from F1.
Another perspective is that F1 continued to focus on new SQL query use cases and optimizations. This gave birth to F1 Lighting, a Hybrid Transactional Analysis Processing (HTAP) database.
Finally, SQL became pervasive at Google; there are more SQL-based systems like PowerDrill, Procella, and Tenzing.
In between, Google tried to create a new standard for SQL called GoogleSQL, but it was not adopted because of its limitations.
A similar journey away from SQL and back has happened in the open-source world.
Hadoop Distributed file systems and MapReduce became popular with Hadoop, and a suite of other NoSQL systems followed.
Now, the industry is pivoting back to SQL. HiveSQL, SparkSQL, and Presto are highly popular.
3. Disaggregation
3.1 Disaggregated storage
Dremel was conceived at Google in 2006 as a 20 percent project by Andrey Gubarev.
Initially, Dremel was running on a few hundred shared-nothing servers. Each server kept a disjoint subset of the data on local disks. In 2009, Dremel was migrated to a cluster management system called Borg (Kubernetes is based on it).
With growth, Dremel datasets reached the range of petabyte-sized and trillion-row tables. Storing replicated data on local disks meant that storage and processing were intimately coupled.
It was time to revisit the shared-nothing architecture. The obvious blocking issue was data access latency. The team experimented with a GFS-based Dremel system and saw an order-of-magnitude performance degradation.
Migrating Dremel to GFS required extensive fine-tuning of the storage format, metadata representation, query affinity, and prefetching.
In addition to liberating the data and reducing complexity, disaggregated storage had several other significant advantages.
First, GFS was a fully managed internal service, which improved Dremel's SLOs and robustness.
Second, the initial step of loading sharded tables from GFS onto the Dremel server’s local disks was eliminated.
Third, onboarding other teams to the service became easier since Dremel team did not need to resize their clusters to load their data.
Once Google’s file system was migrated from the single-master model in GFS to the distributed multi-master model in its successor, Colossus, another notch of scalability and robustness was gained.
3.2 Disaggregated memory
Dremel added support for distributed joins through a shuffle primitive shortly after publishing the original paper.
Dremel’s shuffle utilized local RAM and disk to store sorted intermediate results. The scalability bottleneck was the tight coupling between the compute nodes and the intermediate shuffle storage.
The team built a new disaggregated shuffle infrastructure using the Colossus. Finally, the team settled on the shuffle infrastructure, which supported completely in-memory query execution.
The benefits of the new shuffle:
Reduced the shuffle latency by an order of magnitude.
Enabled an order of magnitude larger shuffles.
Reduced the resource cost of the service by more than 20%.
4. In Situ Analysis
So, what is In situ analysis?
It refers to accessing data in its original place.
Today's data management community is transitioning from classical data warehouses to a datalake-oriented architecture for analytics.
4.1 Dremel’s evolution to in situ analysis
In Dremel’s initial design, explicit data loading was required.
As part of migrating Dremel to GFS, the team made available the storage format within Google via a shared internal library. This format had two distinguishing properties: it was columnar and self-describing. Each file storing a data partition of a table also embedded precise metadata, which included the schema and derived information, such as the value ranges of columns.
Users no longer had to load data into their data warehouse. Any file they had in the distributed file system could be part of their queryable data repository.
Many systems have been created based on this idea. Some of those are Tenzing, PowerDrill, F1, and Procella.
The team evolved the in situ approach in two complementary directions.
First, they began adding file formats beyond the original columnar format. These included record-based formats such as Avro, CSV, and JSON.
The second direction was expanding in situ analysis through federation.
4.2 Drawbacks of in situ analysis
In situ analysis has a few drawbacks. Some of those are discussed next.
Users do not always want to or have the capability to manage their data safely and securely.
There is no opportunity to optimize storage layout or compute statistics.
These issues led to the creation of BigQuery Managed Storage for cloud users.
Hybrid models that blended in situ and managed storage features were explored in NoDB and Delta Lake.
5. Serverless Computing
5.1 Serverless roots
From the start, it was clear that supporting interactive, low-latency queries and in situ analytics while scaling to thousands of internal users at a low cost would be possible if the service was multi-tenant and provided on-demand resource provisioning.
To enable serverless analytics, the team worked on three ideas:
Disaggregation: The disaggregation of computing, storage, and memory allows on-demand scaling and sharing of computing independently from storage.
Fault Tolerance and Restartability: Each subtask within a query had to be deterministic and repeatable, and the query task dispatcher had to support dispatching multiple copies of the same task.
Virtual Scheduling Units: Instead of relying on specific machine types and shapes, Dremel scheduling logic was designed to work with abstract units of compute and memory called slots.
Many other providers, such as Snowflake, used the above three ideas from the original Dremel paper.
Many data warehouse services, such as Presto, AWS Athena, and Snowflake, have adopted on-demand analytics or automatic scaling as key enablers for serverless analytics.
5.2 Evolution of serverless architecture
Dremel continued to evolve its serverless capabilities. Some of the original paper ideas were developed into new ideas like below:
Centralized Scheduling: Dremel switched to centralized scheduling, which superseded the “dispatcher” from the original paper.
The new scheduler uses the entire cluster state to make scheduling decisions, which enables better utilization and isolation. The new architecture is illustrated in the diagram below.

Shuffle Persistence Layer:
Shuffle and distributed join functionality was not present in the original paper.
The architecture evolved and allowed decoupling scheduling and execution of different query stages.
Using the shuffle result as a checkpoint in the query execution state, the scheduler can preempt workers and reduce resource allocation dynamically if necessary.
Flexible Execution DAGs
The fixed tree (DAG) introduced in the original paper was unsuitable for more complex query plans.
By migrating to the centralized scheduling and the shuffle persistence layer, the architecture changed as below:
The query coordinator is the first node receiving the query. It builds the query plan and then orchestrates the query execution with workers given to it by the scheduler.
Workers are allocated as a pool without a predefined structure. Once the coordinator decides on the shape of the execution DAG, the workers are sent a ready-to-execute local query execution plan (tree).
An example execution is shown in the below diagram.
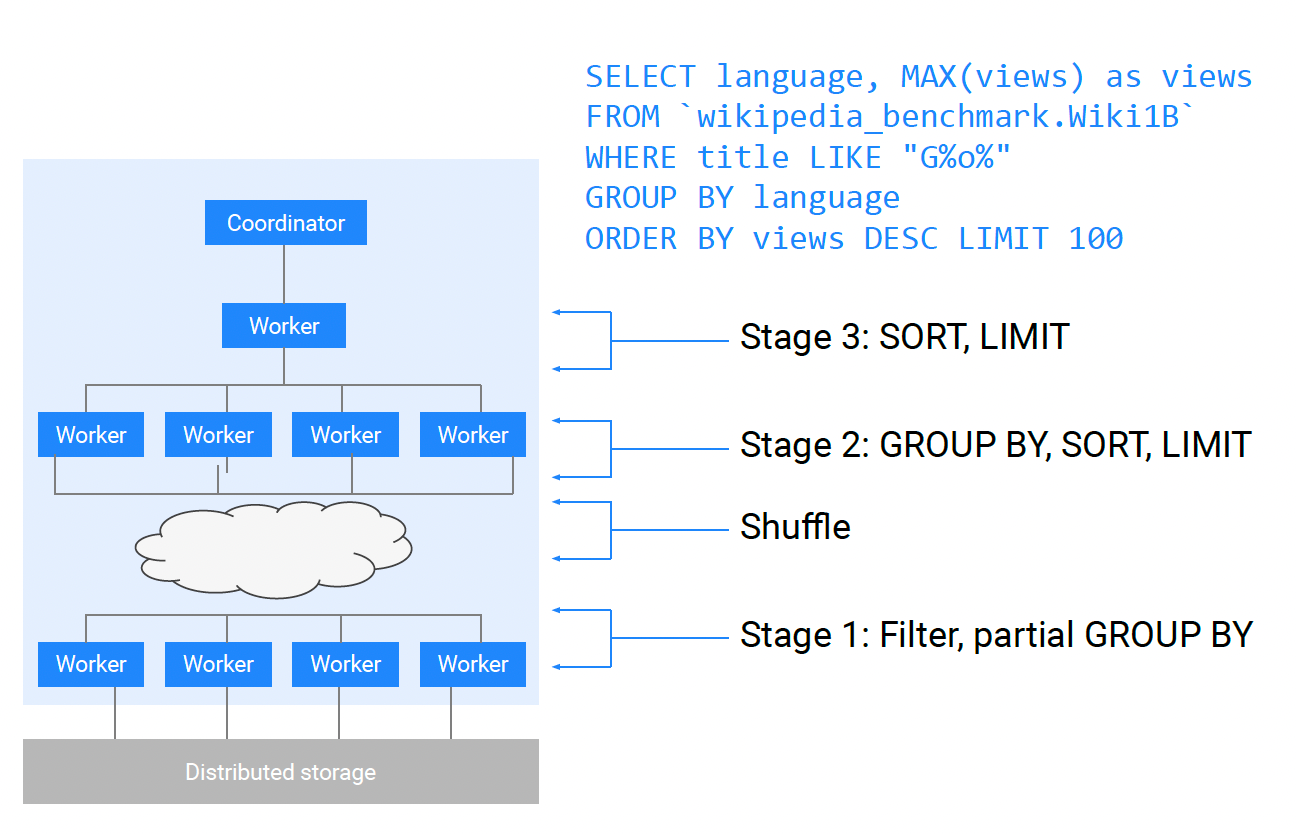
Dynamic Query Execution
There are multiple optimizations that query engines can apply based on the shape of the data.
Dremel has chosen a path where the query execution plan can dynamically change during runtime based on the statistics collected during query execution.
This approach became possible with the shuffle persistence layer and centralized query orchestration by the query coordinator.
6. Columnar Storage For Nested Data
Many new applications and data models started writing semistructured data with flexible schemas in the early 2000s.
JSON became popular. Google introduced Protocol Buffers, Facebook came up with Thrift, and the Hadoop community developed Avro.
The previous Dremel paper spearheaded the use of columnar storage for semistructured data. Google used protocol buffers extensively in all of its applications.
Many open-source columnar formats for nested data have been followed as given below:
Twitter and Cloudera announced the Parquet file format.
Facebook and Hortonworks came up with ORC.
Apache Foundation announced Apache Arrow.
The Dremel paper proposed repetition and definition levels to track repeated and optional fields.
There are tradeoffs between different approaches taken by all providers. The main design decision behind repetition and definition levels encoding was to encode all structured information within the column to be accessed without reading ancestor fields.



In 2014, the team began the storage migration to an improved columnar format called Capacitor and added many new features. A few of them are discussed next.
6.1 Embedded evaluation
The team embedded filtering directly into the Capacitor data access library to make it as efficient as possible. The library includes a mini query processor which evaluates SQL predicates.
Capacitor uses several techniques to make filtering efficient
Partition and predicate pruning
Vectorization
Skip-indexes
Predicate reordering
6.2 Row reordering
The capacitor encodes values using several standard techniques, including dictionary and run-length encodings. Row reordering works surprisingly well in practice.
The diagram shows size differences when enabling reordering on 40 internal Google datasets. Overall, the savings were 17%, with some datasets reaching up to 40% and one reaching up to 75%.


6.3 More complex schemas
Protocol buffers allow defining recursive message schemas. The maximal recursion depth used in a given dataset is not known beforehand. Dremel did not initially support recursive messages of arbitrary depth.
Capacitor added support for these types of schemas.
Protocol Buffers added an extension to support messages without schema. Now, schemaless messages can be supported using ‘Any.’
7. Interactive Query Latency Over Big Data
The conventional wisdom is that colocating processing with data reduces data access latency. Dedicated machines should be more performant than shared serverless machine resources.
Dremel implemented the latency-reducing techniques given below to overcome the notion.
Standby server pool
Speculative execution
Multilevel execution trees
Column-oriented schema representation
Balancing CPU and IO with lightweight compression
Approximate results
8. Conclusions
The team is proud that they got many things right and humbled they got wrong.
The original paper got right below things:
Architectural choices of disaggregated computing and storage
On-demand serverless execution
Columnar storage for nested, repeated, and semistructured data
In situ data analysis
The things that the team got wrong are:
Need for a reliable and fast shuffle layer
Importance of providing a managed storage option
Need for rigorous SQL language design
References
Procella: Unifying Serving and Analytical Data at YouTube
The Seattle Report on Database Research
In-memory Query Execution in Google BigQuery
Processing a Trillion Cells per Mouse Click
Hyper Dimension Shuffle: Efficient Data Repartition at Petabyte Scale in SCOPE
Azure Data Lake Store: A Hyperscale Distributed File Service for Big Data Analytics