
Insights from Paper - In Search of an Understandable Consensus Algorithm (Extended Version) RAFT

Abstract
In this post, I will discuss the RAFT algorithm presented in the paper.
What is Raft?
Raft is a consensus algorithm for managing a log replicated across servers/machines. (What is consensus algorithm? Take a deep breath; I will cover it.)
Raft is equivalent to Paxos (Another algorithm for the same task), but its structure is different, so it is easy to understand.
How is Raft able to do this?
There are two major points:
It separates different key elements of consensus. Some of those are
leader election, log replication, and safety.
It has reduced the number of states in the finite state machine.
Introduction
Let’s start with what a consensus algorithm is.
In simple words, a consensus algorithm allows a group of servers/machines to work so that the group survives even if some of its members fail.
Large-scale software systems are built using many machines, so a consensus algorithm plays a critical role in them.
At the time of writing the paper, Paxos was the most famous and used consensus algorithm. The challenge is that Paxos is very difficult to understand and complex to implement.
You will be amazed to know that the writers of this paper started with the primary goal of making the algorithm understandable.
It means they were looking to develop an algorithm that is easier to learn than Paxos and also easy to develop the intuition for implementation.
This way, Raft is created.
Raft has some similarities with another well-known consensus algorithm called Viewstamped Replication, but many great features in Raft are not there in other algorithms. Some of those are the following:
Strong Leader: Raft’s leader has a very strong form. For example, the log entries only flow from the leader to other servers.
Leader Election: The leader election process starts with a randomized timer instead of a fixed timer, making conflict resolution easy.
Membership Changes: Raft’s mechanism for membership change is quite different. It allows the cluster to continue working while the change process is going on.
Raft has several open-source implementations in different programming languages and is used by several large organizations. Let’s start by diving into Raft.
1. Replicated state machines
First, let’s understand the State machine and replicated state machine.
In simple terms, a state machine has different states, and based on some work on a given state, it moves to another state.
A replicated state machine (RSM) consists of several servers. Each server has the same state, and the collection of servers continues to work even if some of the servers are down.
Before understanding how the RSM is implemented, I want to describe its usage. The most critical use of RSM is to solve different fault-tolerance problems.
For example, Google File System (GFS) uses a separate replicated state machine to manage leader election and store configuration information that must survive leader crashes.
Chubby and Zookeeper are two famous RSMs.
You can read more about the GFS and Zookeeper papers in my articles. The links are in resources.
So, how is the RSM implemented?
The most common way to implement a Replicated state machine is by using a replicated log.
Each server stores a log.
The log contains a series of commands executed in the state machine in the stored order.
This means that each server log contains the same commands in the same order.
One important point to note here is that the state machine is deterministic. So, each server processes the same sequence of commands and produces the same output.
So now the question is, what does a consensus algorithm do?
The consensus algorithm's job is to make this replicated log consistent across the servers in a given group.

The consensus module on a server receives client commands and adds them to its log, as shown in the above diagram.
The consensus module on a server communicates to the consensus module on other servers. It is responsible for ensuring that every log eventually contains the exact requests in the same order in each server.
Each server’s state machine processes the log in the order, and the outputs are returned to clients. Given that the replicated logs are consistent, the outputs sent to the clients are the same.
Practically, a consensus algorithm should have the following properties:
Safety: The system should never return an incorrect result.
Availability: The system should be fully functional as long as any
majority of the servers are operational and can communicate
with each other and with clients.
Dependency on time: The system should not depend on timing to ensure log consistency.
Performance: A command should be completed as soon as a majority of the cluster has responded.
2. What’s wrong with Paxos?
Leslie Lamport’s Paxos protocol has become almost synonymous with consensus.
Paxos first defines a protocol capable of agreeing on a single decision, such as a single replicated log entry. We refer to this subset as single-decree Paxos.
Paxos then combines multiple instances of this protocol to facilitate a series of decisions, such as a log (multi-Paxos).
Paxos ensures both safety and liveness and supports changes in cluster membership. Its correctness has been proven, and it is efficient in the normal case.
Paxos has two significant drawbacks.
It is exceptionally difficult to understand. There have been several
attempts to explain Paxos in simpler terms.
It does not provide a good foundation for building practical implementations. There is no widely agreed-upon algorithm for multi-Paxos.
Paxos architecture is a poor one for building practical systems.
3. Designing for understandability
It must provide a complete and practical foundation for system building.
It must be possible for a large audience to understand the algorithm comfortably.
it must be possible to develop intuitions about the algorithm so that system builders can make the extensions that are inevitable in real-world implementations.
4. The Raft consensus algorithm
It is clear by now that Raft is an algorithm for managing a replicated log.
The following are the key properties of the Raft algorithm :
Election Safety: At most, one leader can be elected in a given term (a time of arbitrary length).
Leader Append-Only: A leader never overwrites or deletes entries in his log.
Log Matching: If two logs contain an entry with the same index and term, then the logs are identical to this index.
Leader Completeness: If a log entry is committed in a given term, it will be present in the leaders' logs for all higher-numbered terms.
State Machine Safety: If a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
Raft implements consensus by first electing a leader. The leader then has complete responsibility for managing the replicated log.
The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply them to their state machines.
A leader can fail or become disconnected from the other servers. In such cases, a new leader is elected.
Raft has divided the consensus into independent sub-problems.
Leader election: A new leader must be chosen when an existing leader fails.
Log replication: The leader must accept client log entries and replicate them across the cluster.
Safety: If any server has applied a particular log entry to its state machine,
then no other server may apply a different command for the same log index.
4.1 Raft basics
A Raft cluster has many servers. Most of the time, it has 5 servers so that the cluster can tolerate the failure of 2 servers.
At any given time, each server is in one of three states:
leader, follower, or candidate.
Normally, there is one leader who handles all client requests.
Followers respond to requests from leaders and candidates.
Candidates are used to elect a new leader.
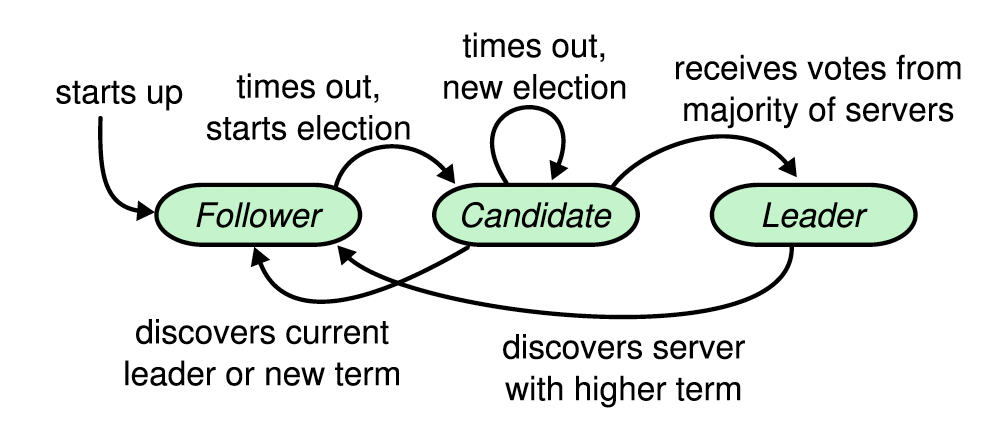
The diagram above shows all three states and transition functions from one state to another.
Raft divides time into terms of arbitrary length as shown in the below diagram.

Raft divides time into terms. The terms’s length (duration) is not fixed.
The term starts when a leader is elected. An integer represents the term, and these integers are consecutive.
When a candidate wins the election, he becomes the leader for the full term.
It is possible that an election results in a split vote (tie) and no candidate becomes a leader. In such cases, the election is held again.
There can be at most one leader per term.
The term is Raft's logical clock. Servers detect stale leaders and any old information using terms.
Let’s understand how all servers remain up to date for the term.
Each server stores a current term number. These numbers increase monotonically in each election.
When servers communicate, they exchange the term number. If a server has a small value, it updates the current term value to a larger value.
One important point to note here: Whenever a candidate or leader finds that its current term number is out of date, it immediately transitions to a follower state.
A server in any state rejects the request if the term number in the request is smaller than its current term number.
Different servers may transition between terms at different times.
Raft uses RPC to communicate between servers. There are only two types of RPC for basic algorithms:
RequestVote RPC: It is initiated by candidates during an election.
AppendEntries RPC: Leaders initiate the replication of log entries. It also provides a form of heartbeat.
There is one more RPC, which is used for transferring snapshot information between servers, but it is not used in the basic consensus algorithm.
4.2 Leader election
When a server starts, It starts with a follower state.
A server remains in a follower state if it receives valid RPCs from a leader or candidate.
If a follower receives no communication over a period called the election timeout, it assumes that there is no viable leader. In such a case, the follower begins an election to choose a new leader.
A follower increments its current term, transitions to the candidate state, and starts an election.
It votes for itself and issues RequestVote RPCs parallel to each other server in cluster.
There are three possible outcomes of the process:
The follower wins the election.
Another server establishes itself as the leader.
There is no winner in the election.
Let’s discuss these outcomes in detail.
The first outcome of the current follower becoming a candidate and winning the election is simple. The candidate gets the majority of votes, so it wins. This is natural, as each server can vote at most one server per election on a first-come-first-served basis.
Once a candidate becomes the leader after the election, he sends heartbeat messages to all of the other servers, telling them that he is the leader.
So, let’s assume a candidate is waiting for other servers' votes. During this period, it may receive an AppendEntries RPC from another server claiming to be the leader. If this leader’s term (included in the RPC request) is at least as large as the candidate’s current term, then the leader is legitimate, and the candidate becomes a follower of this leader.
If both of the above scenarios do not occur, there will be no winner. This is possible because some other followers may have tried to win the election in this term after becoming candidates. This is called a split vote. In this case, candidates will time out and start a new election by incrementing their term.
One interesting point to note is that the third outcome can be repeated infinitely if the algorithm is not designed carefully.
Raft randomizes election timeouts so that split votes are rare and, even if they occur, they are resolved quickly.
4.3 Log replication
The leader is responsible for serving client requests.
Each client request contains a command to be executed by the RSM.
The leader appends this command to its own log as a new entry.
After that, it issues AppendEntries RPC calls in parallel to each other cluster server to replicate this entry.
This entry will be safely replicated in other servers(we will talk about that later), and then the leader applies the command to the state machine and returns the result to the client.
Here, there is one very critical point to note: the leader tries indefinitely to send AppendEntries RPC calls to all followers until all of them eventually store all log entries.

The above diagram shows how the logs are organized in Raft.
Each log entry stores a state machine command (received from the client) along with the term number when the leader received the entry.
Inside the box associated with each log index, the server's term is shown as the top value (like 1 in the first cell) and the command as the bottom value (like x←3 in the first cell). Each horizontal bar shows the log of one server.
The leader decides when it is safe to apply (sometimes also called execute) a log entry to the state machines.
An applied entry is called committed.
Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines.
A log entry is committed once the leader who created the entry has replicated it on a majority of the servers.
In the diagram above, the log entry at index 7 is committed. Any entries in the leaders’s log previous to this one are also committed.
The leader keeps track of the highest committed log index.
The leader includes this index in future AppendEntries RPCs so that the other servers eventually find this. They use it to apply ( or execute ) the entry in the local state machine in the log order.
We have seen the log-matching property at starting of this section. Let’s understand that in detail. There are two points in this property:
If two entries in different logs have the same index and term, then they store the same command.
If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
A leader creates at most one entry with a given log index in a given term, so the first point is clear.
How the second point is guaranteed?
When the leader sends the AppendEntries RPC, it includes the index and term of the entry in its log that immediately precedes the new entries.
If the follower does not find an entry with the same index and term in its log, it refuses the new entries. The consistency check acts like an indication step on top of the initial empty state. Whenever logs are extended, this is verified, and the second point is guaranteed.
So we are good for all normal operations. But what happens when the leader crashes?
It is possible that the leader did not fully replicate all of the entries in its log before it crashed.
In such a case, the follower may have missing entries that are present on the leader or extra entries that are not present on the leader. Both types of entries are also possible simultaneously.
This is handled in the Raft by overwriting the follower’s log. Take note that leaders’ log entries are append-only. We will see this in detail in the safety section.
If we want a follower’s log to be consistent with the leader’s log, then we need to know the latest entry in the follower’s log up to which there is a match. Once we know this, followers' unmatched entries are deleted, and correct entries from the leader’s log are appended.
In implementation, a leader maintains a next index for each follower. It is the index of the next log entry the leader will send to the follower.
If the leader and follower logs are inconsistent, the AppendEntries consistency check will fail in the next AppendEntries RPC. In the next call of AppendEntries RPC ( you can say it a retry), the leader will decrement the nextIndex.
This will continue, and eventually, the log indexes will be consistent between leader and follower. The AppendEntries RPC will succeed at that point, and the follower will overwrite the required log entries.
We can argue that it is not an optimized way to fix the inconsistency, as leaders and followers may be diverted too much, and many RPCs will be required to achieve consistency.
The paper doubts that such cases will occur in practice. If they do, when rejecting an AppendEntries request, the follower can include the term of the conflicting entry and the first index it stores. This will reduce the number of RPC calls.
4.4 Safety
Whatever we have discussed until now is insufficient to ensure that each state machine executes the same commands in the same order.
For example, a follower might be unavailable while the leader commits several log entries. Then, this follower becomes a candidate for a term and is elected as a leader. In this case, it will overwrite these entries with new entries. Now, we are in a situation where different state machines might execute different command sequences.
How to fix this?
Raft algorithm has one more restriction for this as follows:
The leader for any given term contains all the entries committed in previous terms. It is called Leader Completeness Property. This way, it is not possible for a follower to become a leader in the previous example scenario.
With this property discussed, we must understand how Raft commits entries from previous terms.
First, the basic point: A leader knows that an entry from its current term is committed once it is stored on a majority of the servers.
Let’s assume a leader crashes before committing an entry. Future leaders will attempt to finish replicating the entry for all followers.
Let’s discuss a proper example for this case.
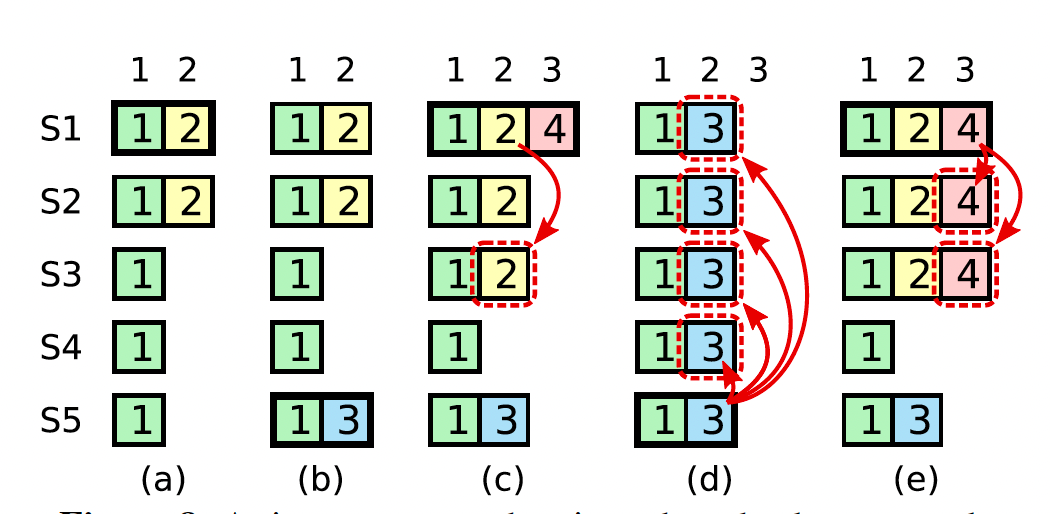
The diagram above shows a time sequence.
(a) S1 is the leader and partially replicates the log entry at index 2.
(b) S1 crashes. S5 is elected leader for term 3 with votes from S3, S4, and itself, and accepts a different entry at log index 2.
(c) S5 crashes. S1 restarts is elected leader and continues replication. At this point, the log entry from term 2 has been replicated on a majority of the servers, but it is not committed.
Here onwards, we will see the problem,
(d) Let’s say S1 crashes. S5 could be elected leader and overwrite the entry with its own entry from term 3. Assume S1 replicates an entry from its current term on a majority of the servers before crashing.
(e) This entry ( value 4 at index 3) is committed. So S5 cannot win the election.
At this point, all preceding entries in the log are also committed, which is incorrect.
Now let’s look at the solution:
Raft never commits log entries from previous terms by counting replicas ( which we assumed in point (d) in the diagram).
This way, only log entries from the leader’s current term are committed by counting replicas. All prior entries are committed indirectly because of the Log Matching Property.
The paper has a safety argument section where the Leader Completeness Property is proved correct by contradiction. I assume this is of theoretical interest and leaving it for the readers to explore further.
4.5 Follower and candidate crashes
We have not talked about what happens when a follower or candidate fails.
If a follower or candidate crashes, then future RequestVote and AppendEntries RPCs sent to it will fail.
Raft takes care of this failure by retrying indefinitely, as Raft RPCs are idempotent.
There are two scenarios:
If the crashed server restarts, then the RPC will complete successfully.
If a server crashes after completing an RPC but before responding, then it will receive the same RPC again after it restarts.
4.6 Timing and availability
During the requirement discussion, we discussed how Raft’s safety must not depend on timing.
In simple terms, the system must produce correct results even if some event happens more quickly or slowly than expected.
Let’s understand different timings before we dive deep into the election process, which is critical from a timing point of view.
BroadcastTime: It is the average time a server takes to send RPCs in parallel to every server in the cluster and receive their responses.
ElectionTimeout: It is the election timeout.
MTBF: It is the average(mean) time between failures for a single server.
Raft will be able to elect and maintain a steady leader as long as the system satisfies the following timing requirements:
BroadcastTime <= ElectionTimeout <= MTBF
The broadcast time should be an order of magnitude less than the election timeout so that leaders can reliably send the required heartbeat messages.
The election timeout should be a few orders of magnitude less than MTBF so the system can progress.
5. Cluster membership changes
In this section, we will discuss how to handle changes in cluster membership, such as adding a new server.
The most important point is that the configuration change mechanism has to be safe. We can not have two leaders at any point in time.
We must use a two-phase approach to ensure that configuration changes are safe.
Raft implements this approach via the following:
First, the cluster switches to a transitional configuration (called joint consensus).
Once the joint consensus has been committed, the system transitions to the new configuration.
Let’s understand how the joint consensus works. It combines both the old and new configurations:
Log entries are replicated to all servers in both configurations.
Any server from either configuration may serve as a leader.
Agreement (for elections and entry commitment) requires separate majorities from both the old and new configurations.
Joint consensus allows individual servers to transition between configurations simultaneously without compromising safety. During joint consensus, the cluster continues to service client requests.
Cluster configurations are stored and communicated using special entries in the replicated log.

The above diagram shows the timeline for a configuration change.
Dashed lines show configuration entries that have been created but not committed.
Solid lines show the latest committed configuration entry.
There is no point in time in which the old cluster and the new cluster can both make decisions independently.
6. Log compaction
As time passes, logs in a cluster can grow without bounds.
If we allow this, there will be availability problems. The old log entries must be discarded.
Raft uses a snapshotting mechanism. The entire current system state is written to a snapshot on durable storage, and then the entire log up to that point is discarded.

The above diagram shows how snapshotting is done.
Each server takes snapshots independently. It covers just the committed entries in its log.
The state machine writes its current state to the snapshot.
There are two metadata associated with a snapshot:
The last included index is the index of the last entry in the log that the snapshot replaces.
The last included term is the term of the entry in point 1.
The leader must occasionally send snapshots to followers that lag behind.
Raft uses a log-structured merge (LSM ) trees approach for compaction.
Raft uses a new RPC called InstallSnapshot to send snapshots to followers that are too far behind.

The diagram above has the summary of the InstallSnapshot RPC.
When a follower receives a snapshot with this RPC, it must decide what to do with its existing log entries. There are two possibilities:
The snapshot contains new information. The follower discards its entire log, which is superseded by the snapshot and may possibly have uncommitted entries that conflict with it.
When a follower receives a snapshot that describes a prefix of the follower’s log, the log entries covered by the snapshot are deleted, but entries following the snapshot are still valid and must be retained.
7. Client interaction
We have converted almost all aspects of server-side work. Let’s discuss how clients interact with Raft.
The first point is that clients send all of their requests to the leader.
When a client first starts up, it connects to any random server in the cluster. If the server is not the leader, it redirects the request to the leader.
Before we proceed, there is one important point to discuss. Raft is built to implement linearizable semantics. What is it?
In simple terms, it means each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response.
We have discussed that the client can send duplicate retry requests. How can the leader know this? The solution is that the client assigns unique serial numbers to every command.
The cluster tracks the latest serial number processed for each client, along with the associated response. If it receives a command with the serial number already executed, it responds immediately without re-executing the request.
8. Implementation and evaluation
The Raft team implemented the algorithm in C++. It contains roughly 2000 lines of code without tests. The source code is freely available. I have added the link to the resources.
There are many independent third-party open-source implementations of Raft.
If you are curious to know how the algorithm performs in evaluating the three criteria of understandability, correctness, and performance, read the evaluation section in the original paper.
9. Related work
There are a few important and famous categories of consensus algorithms/implementations. I am listing them below:
Lamport’s original description of Paxos
Elaborations of the original Paxos
Implementation of consensus algorithms like Chubby, ZooKeeper, and Spanner
Performance optimizations for Paxos
Viewstamped Replication (VR) - an alternative approach to consensus
10. Conclusion
It is normal to design algorithms for correctness, efficiency, and/or conciseness, but understandability is also very important. Developers can achieve all other goals by implementing them practically.
This paper prioritizes understandability and develops a replicated state machine approach to implementing a consensus algorithm.
Resources
The RAFT Paper: https://raft.github.io/raft.pdf
Paxos made simple Paper : https://lamport.azurewebsites.net/pubs/paxos-simple.pdf
Viewstamp Replication Revisited Paper: https://pmg.csail.mit.edu/papers/vr-revisited.pdf