
Insights from paper - Pinot: Realtime OLAP for 530 Million Users

Pinot started inside LinkedIn as an internal project in 2013. Pinot serves tens of thousands of analytical queries per second, offers near-realtime data ingestion from streaming data sources, and handles the operational requirements of large web properties.
Pinot was open-sourced in 2015, and in 2019, it became Apache Pinot.
Introduction
Nowadays, web companies generate large amounts of data. The end users want to analyze this ever-growing volume of data. The challenge is with scale and interactive-level performance required.
Pinot postulates the critical requirements for a scalable near-realtime OLAP service as follows:
Fast, interactive-level performance
Scalability
Cost-effectiveness
Low data ingestion latency
Flexibility
Fault tolerance
Uninterrupted operation
Cloud-friendly architecture
Let’s understand these requirements in a bit more detail.
Interactive-level responsiveness is the most critical problem. MapReduce and Spark have adequate throughput but their high latency and lack of online processing limit fluent interaction.
I mentioned the same issues in a previous post on Druid, which is quite similar to Pinot. Read my take on Apache Druid paper insights here: part I and part II.
Scalability is a critical concern. Any solution not offering near-linear scaling will eventually need to be replaced.
Cost-effectiveness is also a critical concern. Performance is intimately tied to cost-effectiveness. Increasing performance also has the side effect of improving cost-effectiveness.
Ingestion latency is another essential area. Many commercially available systems for analytics cannot handle single-row loads and rely on bulk loads for data ingestion.
Flexibility is expected from an analytical system. It is not good to limit users to pre-defined combinations of dimensions.
Fault tolerance and continuous operation are required in today’s world to satisfy the demands of end users.
Different use cases for near-realtime OLAP systems have different complexity and throughput requirements. Dashboards for millions of end users might have a few features but lower throughput use cases will typically have more complex features.
Related Work
The traditional RDBMS can also process OLAP-style queries, which are usually inefficient for these workloads.
For a smaller web company, building a read replica of the OLTP database is good, and then using it for analytical purposes. As data volumes increase, the cost of maintaining per-column indexes limits ingest rates for such setups.
Column stores, such as MonetDB, C-Store, and Vertica, offer significant performance improvements over the row-oriented RDBMS stores we talked about for analytical queries.
Column stores do not do very well for specific operations, such as single-row inserts, updates, and point lookups.
To get the best of both worlds, SAP HANA, DB2 BLU, Oracle Database in-memory, and MemSQL integrate row-oriented and column stores within the same database.
There is another approach to offline systems like Hive, Impala, and Presto. They offer distributed query execution on large data sets. These systems do not keep user data resident in memory. They are not suitable for repeated queries on the same data set. They cannot handle data that has not been written to durable distributed storage.
Another way to improve the performance of the OLAP system is to pre-aggregate data into cubes, then perform query execution on the pre-aggregated data. These performance improvements come at the expense of query flexibility.
There is another example of a specialized system — Druid. It is an asynchronous low-latency ingestion analytical store. Pinot, unlike Druid, has been optimized for handling both high throughput servings of simple analytical queries and more complex analytical queries at lower rates.
Pinot uses specialized data structures and specific high-throughput optimizations, serving low-complexity aggregation queries at tens of thousands per second.
Architecture
Pinot was developed at LinkedIn to deliver real-time analytics with low latency.
Pinot is optimized for the use of immutable append-only data and offers data freshness that is on the order of a few seconds.
Pinot powers customer-facing applications such as “Who viewed my profile” (WVMP) and newsfeed customization, which require low latency.
At Linkedin, business events are published in Kafka streams and are loaded onto HDFS. Pinot supports near-real-time data ingestion by reading events directly from Kafka and data push from offline systems like Hadoop. This dual sourcing is called lambda architecture.
Pinot transparently merges streaming data from Kafka and offline data from Hadoop.
Data and Query Model
Data in Pinot consists of records in tables. Each table has a fixed schema. Pinot supports integers of various lengths, floating point numbers, strings, and boolean data types. Arrays of these types are also supported. Each column can be either a dimension or a metric.
Pinot has a unique timestamp dimension column called a time column. The time column is used when merging offline and real-time data.
Tables are composed of segments. Each segment is a collection of records. A segment might have a few dozen million records. Data in segments are immutable. A typical segment is a few hundred megabytes up to a few gigabytes.
A table can have tens of thousands of segments. Segments in a table are replicated to ensure data availability.
Data orientation in Pinot segments is columnar. Pinot uses dictionary encoding and bit packing of values. It supports inverted indexes like Druid. You can read my paper on Druid to see examples.
Pinot supports a subset of SQL called PQL for querying. PQL supports selection, projection, aggregations, and top-n queries but does not support joins or nested queries.
Components
Pinot has the following four main components:
Controllers, Brokers, Servers, and Minions
Beyond these, Pinot depends on two external services Zookeeper and a persistent object store.
Pinot uses Apache Helix for cluster management.

Servers are responsible for hosting segments and processing queries on those segments.
A segment is stored as a directory in the UNIX filesystem. It has a segment metadata file and an index file.
The segment metadata file has information about the set of columns in the segment, their type, cardinality, encoding, various statistics, and the indexes available for that column.
The index file stores indexes for all the columns. This append-only file allows the server to create inverted indexes on demand.
For storage, servers have a pluggable architecture. It supports loading columnar indexes from different storage formats. The server can generate synthetic columns at runtime.
Distributed filesystems like HDFS or S3 can be used as storage.
Controllers are responsible for maintaining an authoritative mapping of segments to servers. The mapping is configurable.
Controllers own this mapping and trigger changes to it on operator requests or in response to changes in server availability.
Controllers support administrative tasks such as listing, adding, or deleting tables and segments.
All the metadata and mapping of segments to servers is managed using Apache Helix.
Brokers are responsible for routing incoming queries to appropriate server instances. They collect partial query responses from servers and merge them into a final result to return to the client.
Brokers use HTTP protocol to talk to clients so we can load balance them.
Minions are responsible for running compute-intensive maintenance tasks.
The controllers’ job scheduling system assigns tasks to minions.
For example, data purging is a maintenance task, as data in Pinot is immutable. A job is scheduled to download segments, remove the unwanted records, and rewrite and reindex them before finally uploading them back into Pinot, replacing the previous segments.
Zookeeper is responsible for storing metadata and communicating between cluster nodes. All the cluster management, segment assignment, and metadata store tasks are done in Zookeeper using Apache Helix.
Segment data is stored in the persistent object store. In LinkedIn, it is locally mounted NFS, but we can use other cloud-based systems like Azure Disk storage.
Common Operations
Segment Load: Apache helix uses two different state machines. One to model the cluster states and another to model segment states, as shown in the below diagram.
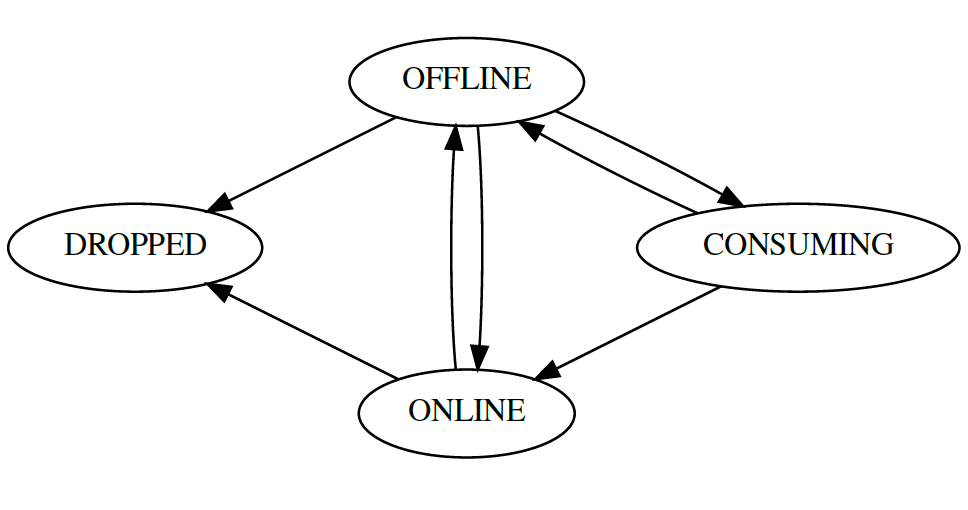
Initially, segments start in the OFFLINE state, and Helix requests server nodes to process the OFFLINE to ONLINE transition. After fetching them from the object store, servers are responsible for making them available.
The real-time data is modeled to transition from OFFLINE to CONSUMING state. Once this transition is done, a Kafka consumer is created with a given start offset to consume data. The diagram below summarizes the process.
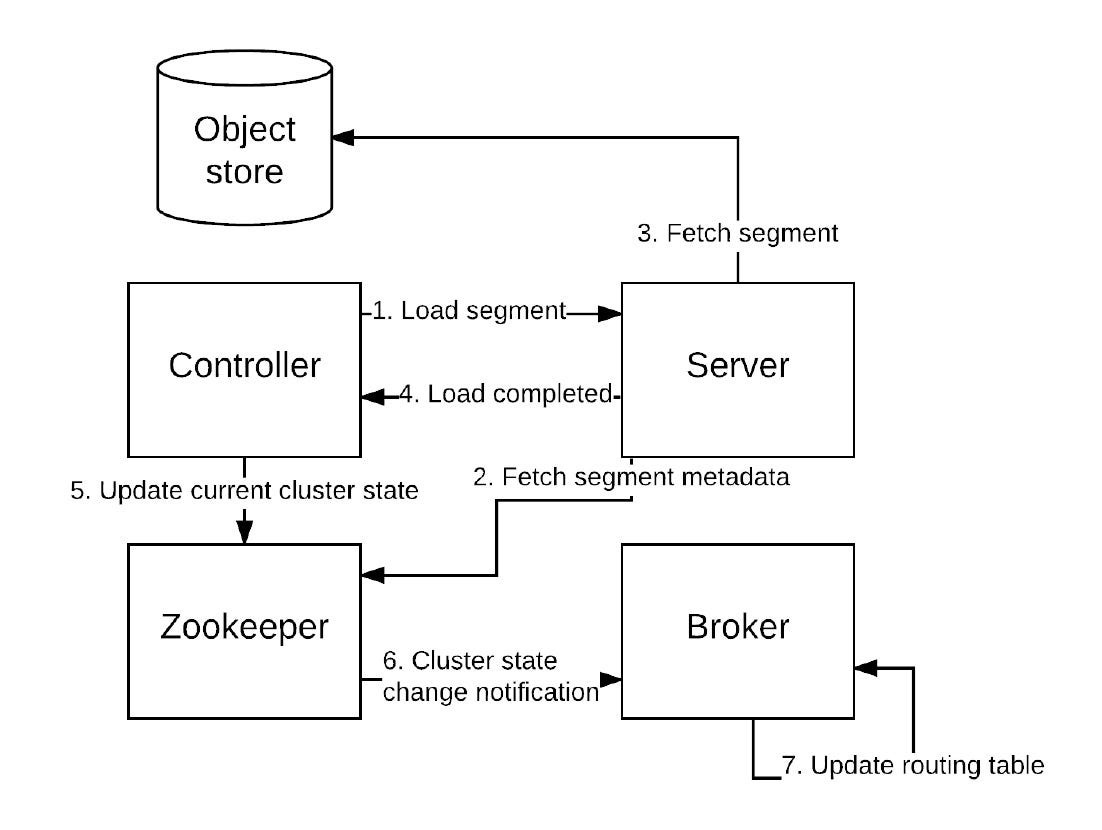
Routing Table Update: We have seen that brokers are responsible for routing incoming queries to appropriate server instances. How do they do that?
They maintain a routing table mapping between servers and available segments. When segments are loaded and unloaded, Helix updates the current cluster state. Brokers listen to these changes and update the routing table.
Query Processing: Following steps happen when a query comes to the broker:
The query is parsed and optimized.
A routing table for that particular table is picked at random.
All servers in the routing table are contacted and asked to process the query on a subset of segments.
Servers generate logical and physical query plans.
The query plans are scheduled for execution.
Upon completion of all query plan executions, the results are gathered, merged, and returned to the broker.
Query results may have been marked as partial due to errors or timeout.
The query result is returned to the client.
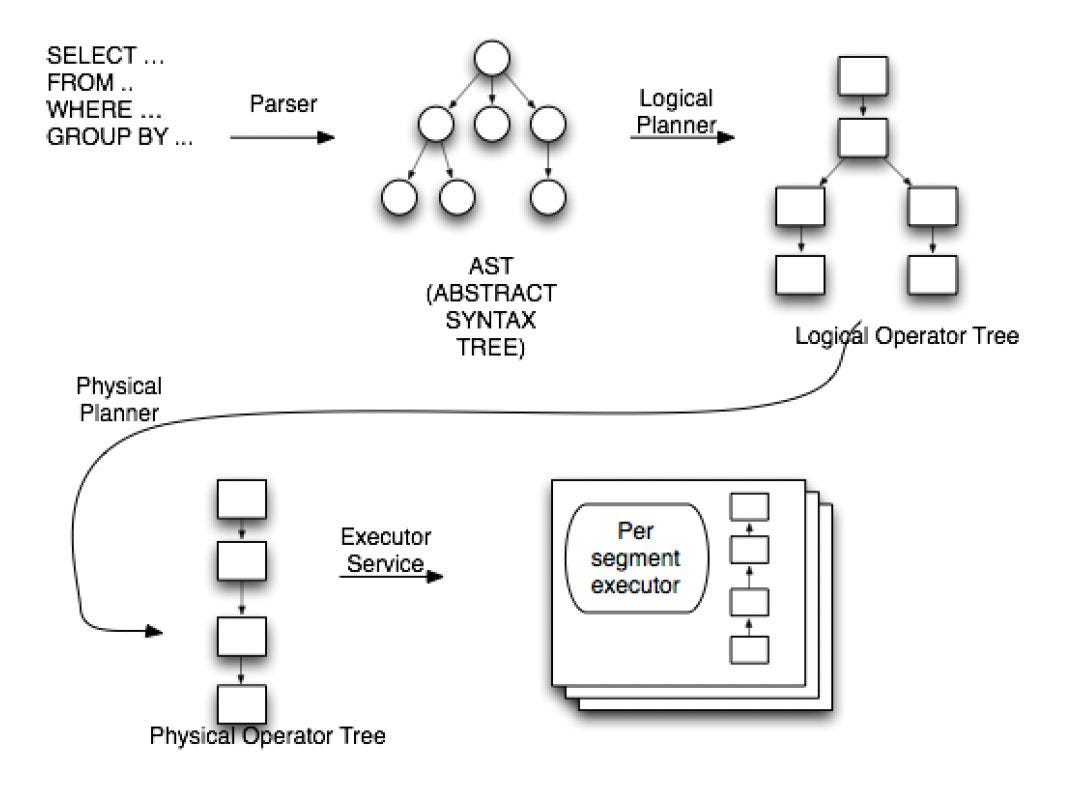
Query Planning Phases
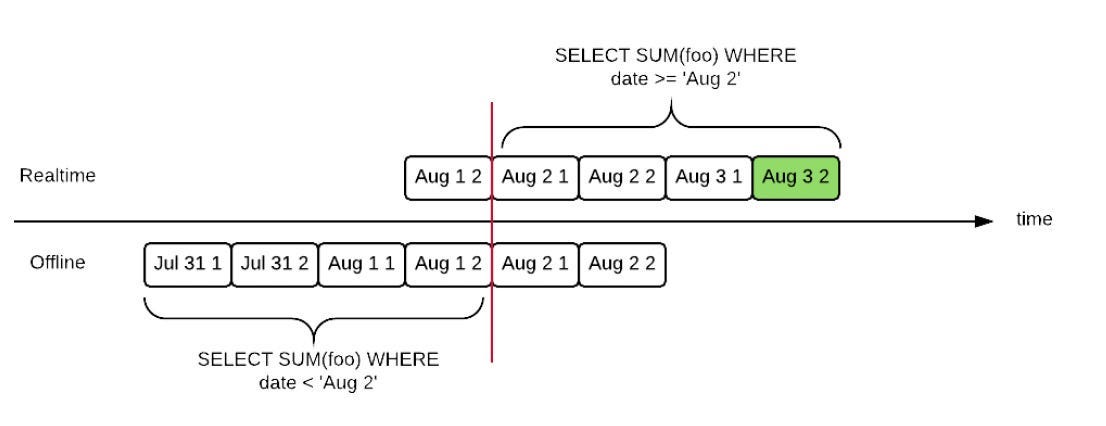
Pinot dynamically merges data streams that come from offline and real-time systems. It is done using hybrid tables. These tables may have overlapping data. When a query arrives for such data in Pinot, it creates two queries — one for the offline part, which queries data before the time boundary, and a second one for the real-time part, which queries data at or after the time boundary.
An example is shown in the below diagram for hybrid table query processing.
Server-Side Query Execution: We have seen that when a query arrives to a server, a logical and physical query plan is generated. The available indexes and physical record layouts may be different. Pinot to do specific optimizations for such exceptional cases.
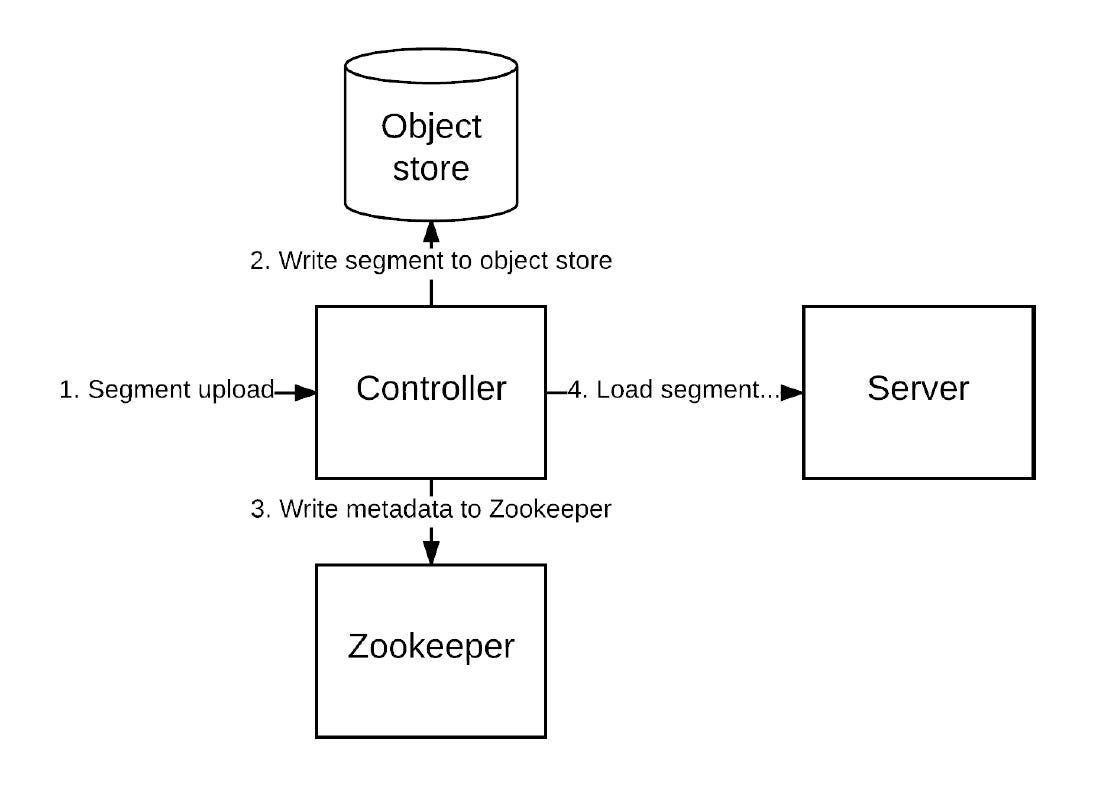
Data Upload: The segments are uploaded to the controller using HTTP POST. As we have seen, controllers are responsible for maintaining an authoritative mapping of segments.
Controllers ensure segment integrity, verify that the segment size would not put the table over quota, write the segment metadata in Zookeeper, and then update the cluster state by making the segment ONLINE.
The below diagram shows the data upload process:
Realtime Segment Completion: We have seen that the real-time data comes in Pinot via Kafka. There are independent replicas where this happens.
Each replica starts consuming from the same start offset and has the same end criteria for the real-time segment. Once the end criteria are reached, the segment is flushed to disk and committed to the controller.
Two different consumers can diverge after some time. Pinot has a segment completion protocol that ensures that independent replicas have a consensus on the final segment's contents.
When a segment is completed, the server polls the leader controller for instructions and tells its own Kafka offset. The controller can return one of the following single instructions to the server.
HOLD, DISCARD, CATCHUP, KEEP, COMMIT, and NOTLEADER.
There is a state machine at the controller which takes care of the reply from servers. Once enough replicas have contacted the controller or enough time has passed, a replica is committed.
A new blank state machine is started on the new leader controller if a controller fails. This only delays the segment commit but otherwise has no effect on correctness.
Cloud-Friendly Architecture:
Pinot has been specifically designed to be able to run on cloud infrastructure.
Pinot needs a compute substrate with local ephemeral storage and a durable object storage system. Any public cloud provider can provide both.
The local storage is only used as a cache and can be recreated by pulling data from the durable object storage or Kafka. It means we can remove any node and replace it with a blank one.
Also, all user-accessible operations for Pinot are done through HTTP. It helps if you want to load-balance them.
Scaling Pinot
Query Execution
Pinot’s query execution model has been designed to accommodate new operators and query shapes.
Pinot’s physical operators are specialized for each data representation. Pinot has operators for each different data encoding. We can add new index types and specialized data structures for query optimization.
Without user awareness, we can deploy new index types and encodings.
Indexing and Physical Record Storage
Pinot support bitmap-based inverted indexes. On top of it, Pinot physically reorders the data based on primary and secondary columns. It helps in running certain types of queries significantly faster.
Iceberg Queries
The queries where only aggregates that satisfy specific minimum criteria are returned are called iceberg queries.
For example, an analyst might be interested in knowing which countries contribute the most page views for a given page. For such a query, re-turning the countries that exceed a minimum page view threshold is sufficient.
There is a concept of iceberg cubing that expands on OLAP cubes and helps answer iceberg queries.
There is advanced work on the iceberg cube called star-cubing. It improves the iceberg cubing technique by making it more efficient to compute.
In star-cubing, a pruned hierarchical structure of nodes called a star tree is constructed and can be efficiently traversed to answer queries. Star trees consist of nodes of pre-aggregated records. Each tree level contains nodes that satisfy the iceberg condition for a given dimension and a star node that represents all data for this particular level.
For example, the below diagram shows a simple query to obtain the sum of all impressions with a simple predicate.
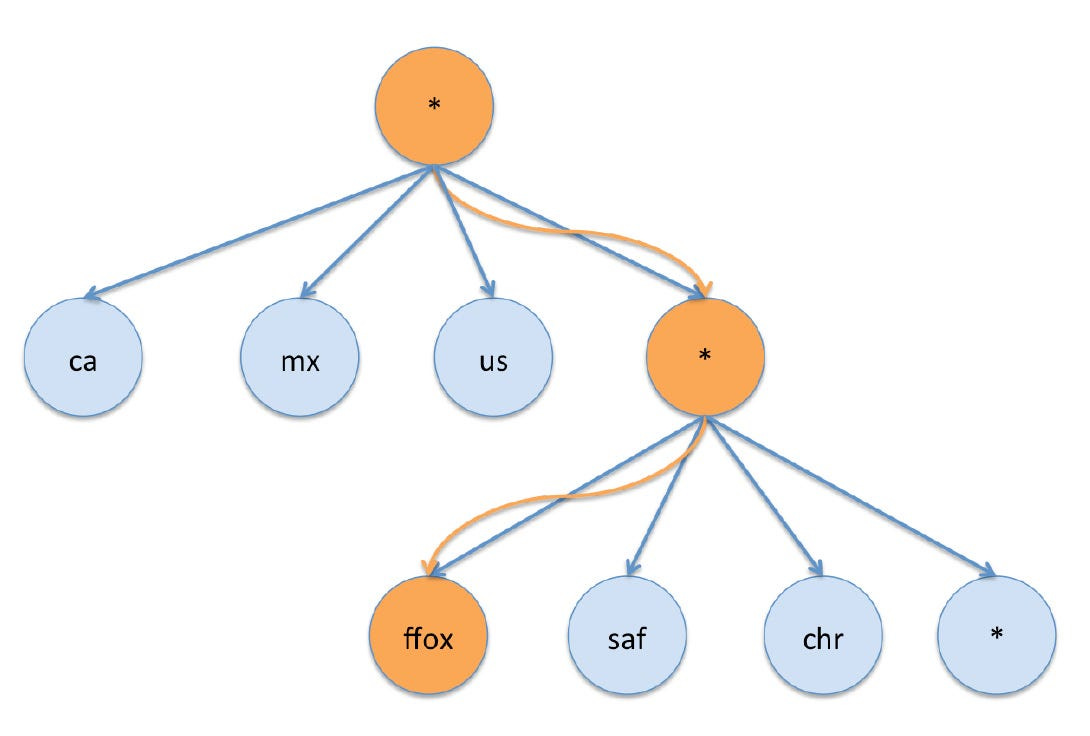
To answer the query, each level of the tree is navigated until finding the node that contains the aggregated data that answers this specific query.
We can answer more complex queries also, as shown in the below diagram.
 from Table where Browser = ‘firefox’ or Browser = ‘safari’ group by Country")
Query Routing and Partitioning
Pinot pre-generates a routing table for unpartitioned tables, which is a list of mappings between servers and their subset of segments to be processed.
Pinot supports various query routing options. The default query routing strategy in Pinot is a balanced strategy that divides all the segments in a table equally across all available servers.
Pinot has a unique routing strategy for large clusters that minimize the number of hosts contacted in the cluster for any given query.
Selecting an exact minimal subset of segments from a given set of segments is an NP-hard problem. Pinot has implemented a random greedy strategy that produces an approximately minimal subset, ensuring a balanced load across all servers. The algorithms are listed in the paper. I am omitting them for brevity.
Multitenancy
Pinot supports multitenancy, with multiple tenants colocated on the same hardware.
To prevent any given tenant from starving other tenants of query resources, a token bucket distributes query resources on a per-tenant basis.
Please note that I am leaving two sections of papers: Pinot in Production and Performance. The reason is straightforward. This section contains facts and figures of experiments LinkedIn did on Pinot clusters. There is no conceptual material there.
Conclusion
The paper covered Pinot as a production-grade system that serves tens of thousands of analytical queries per second in a demanding web environment. It also covered the lessons learned from scaling such a system.
References
My articles on Druid:
https://www.hemantkgupta.com/p/insights-from-paper-part-i-druid
https://www.hemantkgupta.com/p/insights-from-paper-part-ii-druid
The original Pinot paper: https://cwiki.apache.org/confluence/download/attachments/103092375/Pinot.pdf
Bottom-up computation of sparse and iceberg cube: Kevin Beyer and Raghu Ramakrishnan. 1999. . In ACM SIGMOD Record, Vol. 28. ACM, 359–370.
Optimizing druid with roaring bitmaps: Samy Chambi, Daniel Lemire, Robert Godin, Kamel Boukhalfa, Charles R Allen, and Fangjin Yang. 2016. In Proceedings of the 20th International Database Engineering & Applications Symposium. ACM, 77–86.
Better bitmap performance with roaring bitmaps: Samy Chambi, Daniel Lemire, Owen Kaser, and Robert Godin. 2016. Software: practice and experience 46, 5 (2016), 709–719.
Computing Iceberg Queries Efficiently: Min Fang, Narayanan Shivakumar, Hector Garcia-Molina, Rajeev Motwani, and Jeffrey D Ullman. 1999. In International Conference on Very Large Databases (VLDB’98), New York, August 1998. Stanford InfoLab.
Untangling cluster management with Helix: Kishore Gopalakrishna, Shi Lu, Zhen Zhang, Adam Silberstein, Kapil Surlaker, Ramesh Subramonian, and Bob Schulman. 2012. In ACM Symposium on Cloud Computing, SOCC ’12, San Jose, CA, USA, October 14–17, 2012. 19.
Oracle database in-memory: A dual format in-memory database: Tirthankar Lahiri, Shasank Chavan, Maria Colgan, Dinesh Das, Amit Ganesh, Mike Gleeson, Sanket Hase, Allison Holloway, Jesse Kamp, Teck-Hua Lee, et al. 2015. In Data Engineering (ICDE), 2015 IEEE 31st International Conference on. IEEE, 1253–1258.
C-store: a column-oriented DBMS: Mike Stonebraker, Daniel J Abadi, Adam Batkin, Xuedong Chen, Mitch Cherni- ack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, et al. 2005. In Proceedings of the 31st interna- tional conference on Very large data bases. VLDB Endowment, 553–564.
The vertica analytic database: C-store 7 years later: Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan, Nga Tran, Ben Vandiver, Lyric Doshi, and Chuck Bear. 2012. Proceedings of the VLDB Endowment 5, 12 (2012), 1790–1801.
Hive: a warehousing solution over a map-reduce framework: Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, Zheng Shao, Prasad Chakka, Suresh Anthony, Hao Liu, Pete Wyckoff, and Raghotham Murthy. 2009. Proceedings of the VLDB Endowment 2, 2 (2009), 1626–1629.
Avatara: OLAP for web-scale analytics products: Lili Wu, Roshan Sumbaly, Chris Riccomini, Gordon Koo, Hyung Jin Kim, Jay Kreps, and Sam Shah. 2012. Proceedings of the VLDB Endowment 5, 12 (2012), 1874–1877.
Star-cubing: Com- puting iceberg cubes by top-down and bottom-up integration: Dong Xin, Jiawei Han, Xiaolei Li, and BenjaminWWah. 2003. In Proceedings of the 29th international conference on Very large data bases-Volume 29. VLDB En- dowment, 476–487.
Druid: A real-time analytical data store: Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. 2014. In Proceedings of the 2014 ACM SIGMOD international conference on Management of data. ACM, 157–168.
Spark: Cluster Computing with Working Sets: Matei Zaharia, Mosharaf Chowdhury, Michael J Franklin, Scott Shenker, and Ion Stoica. 2010. HotCloud 10 (2010), 10–10.
A multidimensional OLAP engine implementation in key-value database systems: Hongwei Zhao and Xiaojun Ye. 2013. In Workshop on Big Data Benchmarks. Springer, 155–170