
Insights from paper: TiDB: A Raft based HTAP Database

1. Abstract
Hybrid Transactional and Analytical Processing (HTAP) databases allow the processing of transactional and analytical queries.
The challenging part is to provide a consistent view for distributed replicas.
Analytical requests should efficiently read consistent and fresh data from transactional workloads at scale and with high availability.
TiDB proposes extending the replicated state machine-based consensus algorithm.
So TiDB is a Raft-based HTAP database. The team designed a multi-raft storage system.
It consists of a row store and a column store. The row store is built using the Raft algorithm and asynchronously replicates Raft logs to learners.
The learners transform row format for tuples into column format, creating a real-time updatable column store.
This column store allows analytical queries to read fresh and consistent data efficiently. Also, note that the column store is isolated from the row store.
The team built an SQL engine to process large-scale distributed transactions and expensive analytical queries on this storage system.
Beyond that, the TiDB includes a powerful analysis engine called TiSpark. The engine helps TiDB to connect to the Hadoop ecosystem.
2. Introduction
The old RDBMSs do not provide scalability and high availability. So, at the beginning of the 2000s, internet applications preferred NoSQL systems like Google Bigtable and DynamoDB.
NoSQL systems loosen the consistency requirements and provide high scalability.
NewSQL systems like CockroachDB and Google Spanner provide the high scalability of NoSQL for OLTP read/write workloads while maintaining ACID guarantees for transactions.
In addition, SQL-based Online Analytical Processing (OLAP) systems are being developed quickly.
Multiple systems are very expensive to develop, deploy, and maintain, so the movement toward a single hybrid system has started. These are called HTAP systems.
HTAP systems should implement scalability, high availability, and transnational consistency. They must also efficiently read the latest data to guarantee throughput and latency with additional requirements of freshness and isolation.
Let’s understand these additional requirements of freshness and isolation.
Freshness: It means how recent data is processed by the analytical queries.
Some HTAP solutions are based on Extraction-Transformation-Loading (ETL) processing. ETL costs several hours or days, so it cannot offer real-time analysis.
The ETL phase can be replaced by streaming, but still, there are data consistency and governance issues.
Isolation: It refers to guaranteeing isolated performance for separate OLTP and OLAP queries.
Some in-memory databases enable analytical queries to read the latest version of data from transactional processing on the same server. It cannot achieve high performance.
OLTP and OLAP requests must be run on different hardware resources to guarantee isolated performance.
It is challenging to maintain up-to-date replicas for OLAP requests from OLTP workloads within a single system. Another challenge is maintaining data consistency among more replicates.
So we understood the problems by now. What is the solution?
High availability can be achieved using well-known consensus algorithms like Paxos and Raft. If we can extend these algorithms to provide consistent replicas, then our problem is solved.
TiDB does that only.
The team proposes a Raft-based HTAP database. It introduces dedicated nodes called learners to the Raft consensus algorithm.
The learners asynchronously replicate transactional logs from leader nodes to construct new replicas for OLAP queries.
In summary, they transform the row-format tuples in the logs into column format, which is better suited for OLAP queries.
The good part is that the latency of such replication is so short that it can guarantee data freshness for OLAP queries.
3. Raft-based HTAP
Raft and Paxos are two famous consensus algorithms.
They are the foundation of building consistent, scalable, and highly-available distributed systems.
Since the Raft algorithm is designed to be easy to understand and implement, the team selected Raft.
The diagram below shows the high-level ideas.
Data is stored in multiple Raft groups using row format to serve transactional queries.
Each group has a learner role to replicate data from the leader asynchronously.
Data replicated to learners are transformed to a column-based format.
The query optimizer is extended to explore physical plans accessing both row-based and column-based replicas.
Let’s understand the processing in detail.
A learner does not participate in leader elections, nor is it part of a quorum for log replication.
Log replication from the leader to a learner is asynchronous, so the leader need not wait for success before responding to the client.
The strong consistency between the leader and the learner is enforced during the read time.
Learners can be deployed in separate physical resources. This allows transaction queries and analytical queries to be processed in isolated resources.
Let’s now understand the challenges in the above processing.
How do you build a scalable Raft storage system to support highly concurrent read/write?
How do you synchronize logs with learners with low latency to keep data fresh?
How do you efficiently process both transactional and analytical
queries with guaranteed performance?
We will explore the solution of these challenges in the architecture section.
4. Architecture

The diagram above shows the high-level architecture of TiDB.
TiDB supports the MySQL protocol and is accessible by MySQL-compatible clients.
TiDB has three core components: a distributed storage layer, a Placement Driver, and a computation engine layer.
The distributed storage layer consists of a row store (TiKV) and a columnar store (TiFlash).
TiKV is an ordered key-value map. The key comprises the table and row IDs, and the value is the actual row data.
The large key-value map is split into many contiguous ranges using a range partition strategy. Each range is called a Region.
Each Region has multiple replicas for high availability.
The Raft consensus algorithm maintains consistency among replicas for each Region.
The leaders of different Raft groups asynchronously replicate data from TiKV to TiFlash.
TiKV and TiFlash can be deployed in separate physical resources.
Placement Driver (PD) is responsible for managing Regions.
It also supplies each key’s Region and physical location. It automatically moves Regions to balance workloads.
PD provides strictly increasing and globally unique timestamps. These timestamps also serve as our transaction IDs.
PD may contain multiple members and has no persistent state. On startup, a PD member gathers all necessary data from other members and TiKV nodes.
TiDB’s computation engine layer is stateless and scalable.
The SQL engine has a cost-based query optimizer and a distributed query executor. To support transactional processing, TiDB implements a two-phase commit (2PC) protocol based on Google Percolator.
TiDB also integrates with Spark. It is helpful to integrate data stored in TiDB and HDFS.
5. Multi-Raft Storage

The diagram above shows the architecture of the distributed storage layer in TiDB.
Here, multiple Raft groups manage data, so it is called multi-Raft storage.
5.1 Row-based Storage (TiKV)
A TiKV deployment consists of many TiKV servers.
Regions are replicated between TiKV servers using Raft. Each TiKV server can be either a Raft leader or a Raft follower for different Regions.
TiDB uses RocksDB to persist all the data.
The Raft leader handles read/write requests for the corresponding Region.
Let’s look into the basic Raft process before we proceed:
A Region leader receives a request from the SQL engine layer.
The leader appends the request to its log.
The leader sends the new log entries to its followers. The follower appends the entries to their logs.
The leader waits for its followers to respond. If a quorum of nodes responds successfully, the leader commits the request and applies it locally.
The leader sends the result to the client.
The above process is good from a data consistency and high availability perspective, but performance is not good because the steps are sequential, and there may be a high IO cost.
5.1.1 Optimization between Leaders and Followers
The second and third steps can run in parallel. If appending logs fail on the leader but a quorum of the followers successfully appends the logs, the logs can still be committed.
After sending the logs, the leader does not have to wait for the followers to respond. It can send further logs with the predicted log index. If errors occur, the leader adjusts the log index and resends the replication requests.
A different thread can handle the leader applying committed log entries (step four) asynchronously.
5.1.2 Accelerating Read Requests from Clients
The data is read from leaders in a linearizable manner. This means that after a value is read at a time t from a region leader, the leader must not return a previous version of the value for any read requests after time t.
Raft guarantees that once the leader successfully writes its data, the leader can respond to any read requests without synchronizing logs across servers. At this point, the quorum is established.
The important point is that the leader role for a region may have been moved to another TiKV server after the leader election. TiKV has the following two read optimizations.
Read index: When a leader responds to a read request, it records the current commit index as a local read index. After that, it sends heartbeat messages to followers to confirm its leadership role. The leader can return value only if he finds himself the leader.
Lease read: The leader and followers agree on a lease period, during which followers do not issue leader election requests so that the leader is not changed. In this lease period, the leader can respond to any read request without connecting to its followers. This approach works well if the CPU clock is on
each node does not differ very much.
5.1.3 Managing Massive Regions
To balance Regions across servers, the Placement Driver (PD) schedules Regions with constraints on the number and location of replicas.
One critical constraint is to place at least three replicas of a Region on different TiKV instances.
Depending on how busy the Regions’ workloads are, TiDB can adjust the frequency of heartbeats sent.
5.1.4 Dynamic Region Split and Merge
A large Region may become too hot to be read or written in a reasonable time. Hot or large Regions should be split into smaller ones to distribute the workload better.
Also, many Regions may be small and seldom accessed, so they need to be merged. Only adjacent Regions are merged in the key space to maintain the order between Regions.
A split operation divides a Region into several new, smaller Regions. Each new region covers a continuous range of keys in the original Region. The new Region that covers the rightmost range reuses the Raft group of the original Region.
The split process is like an update request in Raft:
PD issues a split command to the leader of a Region.
The leader transforms the command into a log and replicates it to all its follower nodes.
Once a quorum replicates the log, the leader commits the split command. The command is applied atomically to all the nodes in the Raft group.
For each replica of a split Region, a Raft state machine is created, forming a new Raft group.
The merge process is the reverse of the above. PD moves replicas of the two adjacent Regions to colocate them on separate servers. After that, two Regions are merged locally on each server. It has two phases. First, stop the service for one Region, and second, merge it with another.
5.2 Column-based Storage (TiFlash)
We have seen that TiFlash is composed of learner nodes.
They receive Raft logs from Raft groups and transform row-format tuples into column-format data.
Each table in TiFlash is divided into many partitions. Each partition covers a contiguous range of tuples.
During initializing a TiFlash instance, if there is too much data for fast synchronization, the leader sends a snapshot of its data.
After that, the TiFlash instance begins listening for updates from the Raft groups.
5.2.1 Log Replayer
The logs received by learner nodes are linearizable.
They are re-played in FiFO order to maintain the linearizability. The log replay has three steps:
Compacting logs: The transactional logs are classified into three statuses: prewritten, committed, or rollbacked. The compact process deletes invalid prewritten logs according to rollbacked logs and puts only valid logs into a buffer.
Decoding tuples: The logs in the buffer are decoded into row-format
tuples. Then, the decoded tuples are put into a row buffer.
Transforming data format: The buffer's size and time duration are checked, and based on that, data is transformed to columnar data and written to a local partition data pool.
5.2.2 Schema Synchronization
Learner nodes have to be aware of the newest schema for transformation.
The newest schema information is stored in TiKV. Each learner node maintains a schema cache, which is synchronized with TiKV’s schema through a schema synced.
TiDB has a two-stage strategy to manage the trade-off between the frequency of schema synchronization and the number of schema mismatches.
Regular synchronization: The schema syncer fetches the newest schema from TiKV periodically.
Compulsive synchronization: If the schema syncer detects a mismatched
schema, it proactively fetches the newest schema from TiKV.
5.2.3 Columnar Delta Tree
TiDB team designed a new columnar storage engine called DeltaTree.
It appends delta updates immediately and later merges them with the previously stable version for each partition.
The delta updates and the stable data are stored separately in the DeltaTree as shown in the below diagram.

In the stable space, partition data is stored as chunks, each covering a smaller range of the partition’s tuples. These row-format tuples are stored column by column.
Deltas are directly appended into the delta space in the order TiKV generates them to maintain linearizability.
The store format of columnar data in TiFlash is similar to Parquet. TiFlash compresses data files using the LZ4 compression to save their disk size.
5.2.4 Read Process
The learner nodes provide snapshot isolation so data can be read from TiFlash at a specific timestamp.
The learner sends a read index request to its leaders upon receiving a read request.
The leaders send the referred logs to the learner, and the learner replays and stores the logs.
Once the logs are written into DeltaTree, the specific data from DeltaTree is ready to respond to the read request.
6. HTAP Engines
TiDB provides an SQL engine to evaluate transactional and analytical queries.
The engine adapts the Google Percolator model to implement optimistic and pessimistic locking in a distributed cluster.
6.1 Transactional Processing
TiDB provides ACID transactions with snapshot-isolation (SI) or repeatable read (RR) semantics.
SI helps in reading the consistent version of the data in a transaction.
RR helps allow the consistent reading of data by different statements in a transaction.
TiDB uses MVCC, which avoids read-write locking and protects against write-write conflicts.
Let’s understand the collaboration of different components for a transaction.
SQL engine: It coordinates transactions. It receives clients' write and read requests, transforms data into a key-value format, and writes the transactions to TiKV using two-phase commit (2PC).
PD: It manages logical Regions and physical locations. It provides global, strictly-increasing timestamps.
TiKV: It provides distributed transaction interfaces, implements MVCC, and persists data to disk.
Now, let’s understand the optimistic and pessimistic locking.

The process of an optimistic transaction:
SQL engine asks PD for a timestamp to use as the transaction's start timestamp
(start ts) after getting the “begin” command from the client.
The engine executes SQL DMLs by reading data from TiKV and writing to local memory. TiKV supplies data with the most recent commit timestamp (commit ts) before the transaction’s start ts.
When the client issues the “commit” command, the engine starts the 2PC protocol. It randomly chooses a primary key, locks all keys in parallel, and sends prewrites to TiKV nodes.
If all prewrites succeed, the SQL engine asks PD for a timestamp for the transaction’s commit ts and sends a commit command to TiKV. TiKV commits the primary key and successfully responds to the SQL engine.
The engine returns success to the client.
The engine commits secondary keys and clears locks asynchronously.
For pessimistic transactions, users can opt for the read committed (RC) isolation level.
6.2 Analytical Processing
6.2.1 Query Optimization in SQL Engine
TiDB implements a query optimizer with two phases of query optimization:
Rule-based optimization (RBO) of the query, which produces a logical plan
Cost-based optimization (CBO) transforms a logical plan into a physical plan.
RBO has a rich set of transformation rules, including cropping unneeded columns, eliminating projection, pushing down predicates, deriving predicates, constant folding, eliminating “group by” or outer joins, and unnesting subqueries.
CBO chooses the cheapest plan from candidate plans according to execution costs.
TiDB implements scalable indexes to work in a distributed environment.
Regions split indexes in the same way as data and store them in TiKV as key values. Using an index requires a binary search to locate the Regions that contain relevant parts of the index.
6.2.2 TiSpark
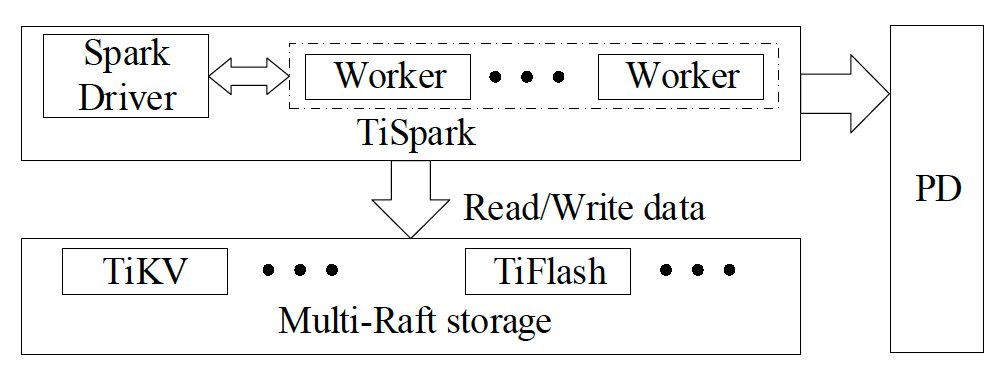
The diagram above shows how TiSpark integrates with TiDB.
Inside TiSpark, the Spark driver reads metadata from TiKV to construct a Spark catalog, including table schemas and index information.
The Spark driver asks PD for timestamps to read MVCC data from TiKV to ensure it gets a consistent snapshot of the database.
TiSpark can simultaneously read from multiple TiDB Regions and get index data from the storage layer in parallel.
6.3 Isolation and Coordination
Analytical queries often consume high CPU, memory, and I/O bandwidth resources. Isolating these resources makes sense for better performance.
Data is consistent across TiKV and TiFlash, so queries can be served by reading from either.
7. Related Work
Evolving from an existing database
Oracle introduced the Database In-Memory option in 2014 as the industry’s first dual-format, in-memory RDBMS.
SQL Server integrates two specialized storage engines into its core: the Apollo column storage engine for analytical workloads and the Hekaton in-memory engine for transactional workloads.
SAP HANA supports efficiently evaluating separate OLAP and OLTP queries and uses different data organizations for each.
Transforming an open-source system
Wildfire builds an HTAP engine based on Spark.
SnappyData presents a unified platform for OLTP, OLAP, and stream analytics.
Building from scratch
MemSQL(SingleStore) has an engine for scalable in-memory OLTP and fast analytical queries.
HyPer used the operating system’s fork system call to provide snapshot isolation for analytical workloads.
ScyPer extends HyPer to evaluate analytical queries on remote replicas at scale.
BatchDB is an in-memory database engine designed for HTAP workloads.
The lineage-based data store (L-Store) combines real-time analytical and transactional query processing within a single unified engine by introducing an update-friendly, lineage-based storage architecture.
Peloton is a self-driving SQL database management system. It attempts to adapt data origination for HTAP workloads at run time.
Cockroach DB is a distributed SQL database that offers high availability, data consistency, scalability, and isolation.
8. Conclusion
The team has presented a production-ready HTAP database TiDB.
TiDB is built on top of TiKV, a distributed, row-based store that uses the Raft algorithm.
TiDB has internally TiFlash as a columnar database.
Log replication between TiKV and TiFlash provides real-time data consistency with little overhead.
References
Wildfire: Concurrent Blazing Data Ingest and Analytics
HyPer: A Hybrid OLTP&OLAP Main Memory Database system based on virtual memory snapshots
Oracle Database In-Memory: A dual format in-memory database
BatchDB: Efficient Isolated Execution of Hybrid OLTP+OLAP Workloads for Interactive Applications
SnappyData: A Unified Cluster for Streaming, Transactions, and Interactive Analytics
ScyPer: A Hybrid OLTP&OLAP Distributed Main Memory Database System for Scalable Real-Time Analytics