
Insights from paper: Google BigLake: BigQuery’s Evolution toward a Multi-Cloud Lakehouse

1. Abstract
Google BigQuery is a cloud-native serverless data analytics platform at its core.
It has compute and storage decoupled (also called disaggregated ) architecture.
This paper describes BigLake, an evolution of BigQuery toward a multi-cloud lakehouse that better addresses customer requirements.
The paper describes three main innovations:
BigLake tables - An open-source table format
Design and implementation of BigLake Object tables.
Omni platform for deploying BigQuery on non-GCP clouds.
2. Introduction
Google Cloud released BigQuery in 2010 as the fully managed serverless multi-tenant cloud data warehouse. BigQuery’s architecture separates compute, storage and shuffle.
The large-scale analytics ecosystem has converged recently toward a so-called lakehouse architecture.
The architecture merges two areas:
Traditional data warehousing (OLAP/BI dashboarding and business reporting over structured relational data)
Data lakes (new workload types such as AI/ML, large-scale analytics over unstructured data, and workloads over open-format table formats such as Iceberg)
BigQuery’s query processing engine, Dremel, can process data in situ over various storage. You can read more about Dremel in my paper post.
BigQuery’s managed storage tier maintains a clean separation of compute and storage.
The read-and-write storage APIs allow third-party analytics engines like Spark or Presto to interact directly with data.
The paper provides an overview of how the team evolved BigQuery to BigLake.
The paper first describes BigLake tables, stored in open-source storage formats (Parquet and Iceberg), as first-class citizens within BigQuery.
Next, it describes the functionality behind BigQuery’s Read and Write APIs. These APIs extend infrastructure to support open-source data lakes on cloud object storage.
The paper describes BigLake managed tables that provide fully managed features like ACID transactions.
Next, the paper describes BigLake Object tables that extend BigQuery to support unstructured data. It also describes how Dremel is extended to perform image inference thoroughly within a relational query engine.
Finally, the last paper describes how lakehouse primitives in BigQuery are extended to other clouds through Omni. BigQuery Omni is a pioneering Google Cloud technology that allows us to ship the core architectural components of BigQuery on non-GCP clouds.
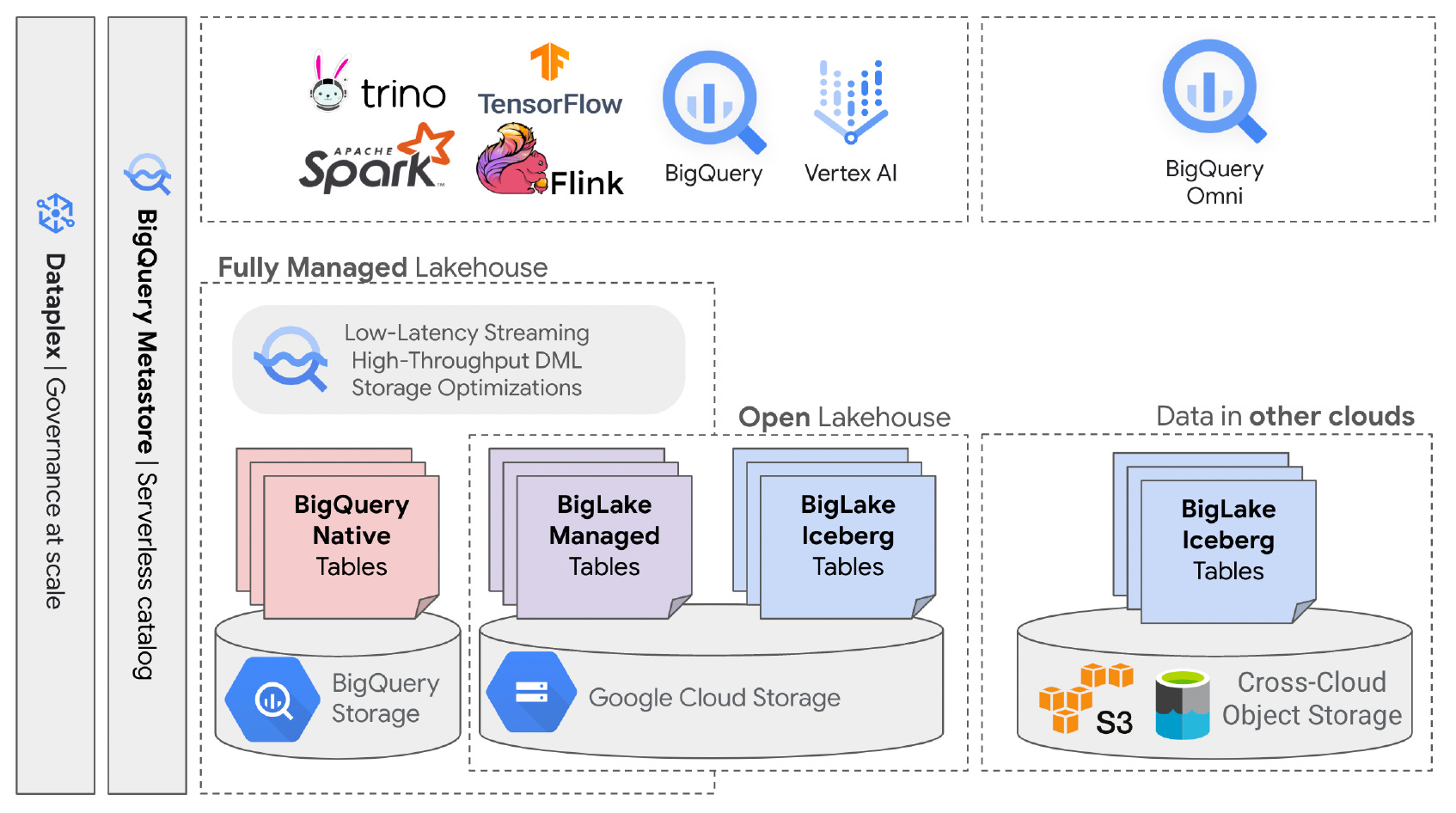
3. BigQuery Architecture
By now, you must have understood that BigQuery is a fully managed, serverless data warehouse. It enables scalable analytics over petabytes of data.
Let’s see its high-level architecture before we move ahead.

The data is in a replicated, reliable, distributed storage system. The elastic distributed compute nodes are responsible for data ingestion and processing.
It has a separate shuffle service to facilitate communication between compute nodes.
BigQuery also employs horizontal services, such as a control plane and job management, metadata/catalog, parser/frontend, and security/governance.
This disaggregated architecture allows close integration with open-source engines like Spark and Presto hosted in Google Dataproc that can write or read directly to/from BigQuery storage.
Similarly, close integration with Vertex AI allows the harnessing of powerful primitives for AI tasks for structured tables or unstructured data such as images, documents, or video.
It also allows shipping core pieces of BigQuery infrastructure, such as Dremel, on non-GCP clouds.
3.1 Dremel and In-Situ Analytics
Dremel is a massively scalable parallel query processing engine behind BigQuery. You can read about it in my Google Dremel paper post.
The Dremel was released in 2006. Initially, it had a tight coupling between storage and compute. Eventually, it evolved into a system with separate compute and storage to support in-situ data analysis.
To support a full suite of essential enterprise data warehousing features, BigQuery built support for Managed Storage.
BigQuery extended Dremel’s in-situ analytics capabilities to query open-source storage formats such as Parquet, Avro, and ORC on Google Cloud Storage (GCS) through external tables.
The above model was good from a storage perspective, but it lacks basic query optimization, data modifications, security, and governance.
BigLake tables were introduced to solve this problem. This allowed customers to use all the enterprise-grade functionality through the Storage APIs to manage data lakes running third-party engines like Apache Spark.
3.2 Storage APIs
The Storage API was added to BigQuery to allow external engines to access BigQuery-managed storage.
3.2.1 Read API
The BigQuery Read API offers a high-performance, scalable way of accessing BigQuery-managed storage and BigLake tables.
The Read API is implemented as a gRPC-based protocol.
It also provides a feature-rich governance layer that enforces the same coarse-grained and fine-grained access control and data visibility mechanisms as core BigQuery.
It has two methods:
CreateReadSession: It allows the user to specify the parameters of the table read that they will be performing. A given read session provides consistent point-in-time reads. This method returns a list of stream objects.
ReadRows: It is called using the stream objects provided by CreateReadSession. Multiple clients can be used to read data from individual streams.
The Read API embeds Superluminal, a C++ library that performs high-performance vectorized execution of GoogleSQL expressions and operators.
Superluminal enables efficient columnar scans of the data. It applies the projections, user/security filters, and data masking and transcodes the result into Apache Arrow.
3.2.2 Write API
The Write API provides a mechanism for scalable, high-speed, and high-volume streaming data ingestion into BigQuery.
It is also implemented as a gRPC-based wire protocol.
It supports multiple streams, exactly-once delivery semantics, stream-level, and cross-stream transactions.
4.BigLake Tables
For quite a long time(many years), BigQuery supported basic read-only external tables. The customers were looking for full enterprise-grade functionality for external tables like internal tables.
The team solved this problem by creating BigLake tables.
BigLake tables provide uniform enterprise data management features across various analytics engines and storage platforms.
The key ideas behind BigLake tables are two-fold.
They extend external open-source data lake tables to be first-class citizens in BigQuery.
These tables provide enterprise functionality to the broader analytics engine
ecosystem through the Read/Write APIs.
The initial release used a delegated access model. The subsequent release provided performance acceleration through physical metadata caching.
4.1 Delegated Access Model
Normally, query engines forward the querying user credentials to the object store.
This model does not work for BigLake tables for two reasons:
Credential forwarding implies that the user has direct access to raw data files. So users can bypass fine-grained access controls such as data masking or row-level security.
BigLake tables need to access storage outside of the context of a query to perform maintenance operations.
BigLake tables rely on a delegated access model. Users associate a connection object with each table. This object contains service account credentials granted read-only access to the object store.
The table uses these connection credentials to process queries and perform background maintenance operations.
4.2 Fine-Grained Security
BigLake tables provide consistent and unified fine-grained (row and column-level) access controls.
This is independent of storage or analytics engine.
BigLake tables offer a stronger security model where the Read API establishes a security trust boundary and applies the same fine-grained access controls before data is returned to the query engine.
4.3 Performance Acceleration
BigQuery has tables which are not backed by modern managed table formats like Apache Iceberg, Apache Hudi or Databricks Delta Lake.
The listing operation on these table files is too slow.
To accelerate query performance, BigLake tables support a feature called metadata caching.
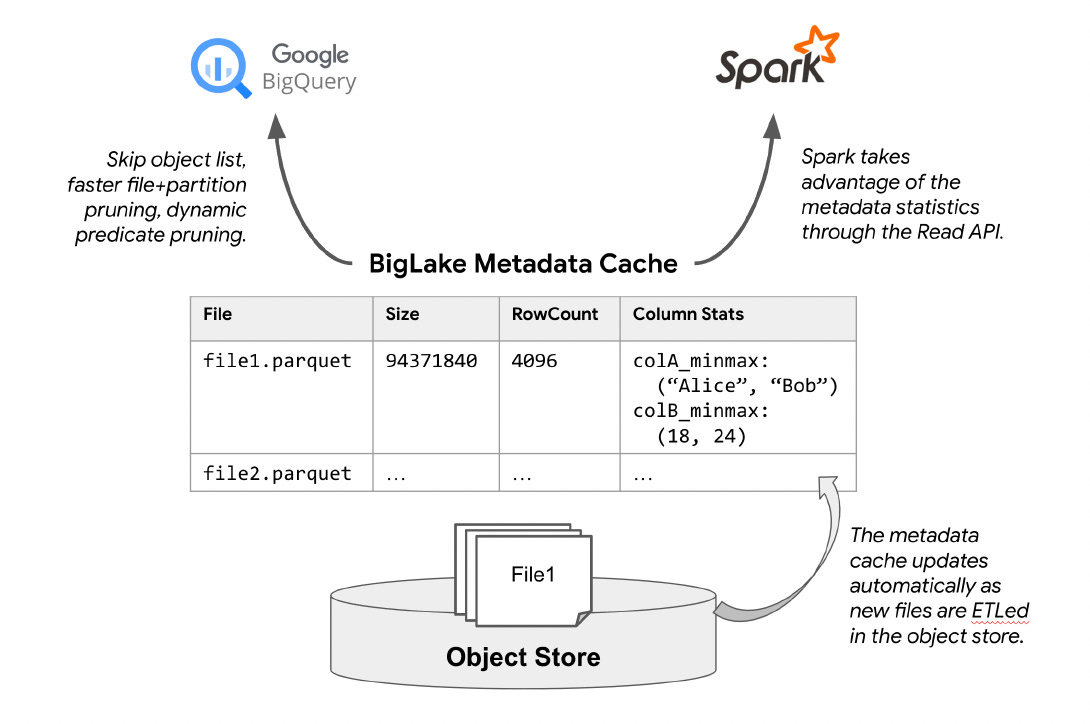
The diagram above shows how BigLake automatically collects and maintains physical metadata about files in object storage.
There is a scalable physical metadata management system called Big Metadata for BigQuery native tables. This system is used for other tables also.
BigLake tables cache file names, partitioning information, and physical metadata from data files, such as physical size, row counts and per-file column-level statistics in a columnar cache in this metadata system.
The statistics collected in this system enable both BigQuery and Apache Spark query engines to build optimized high-performance query plans.
The result of this accelarion on official TPC-DS 10T benchmark is given in below diagram.
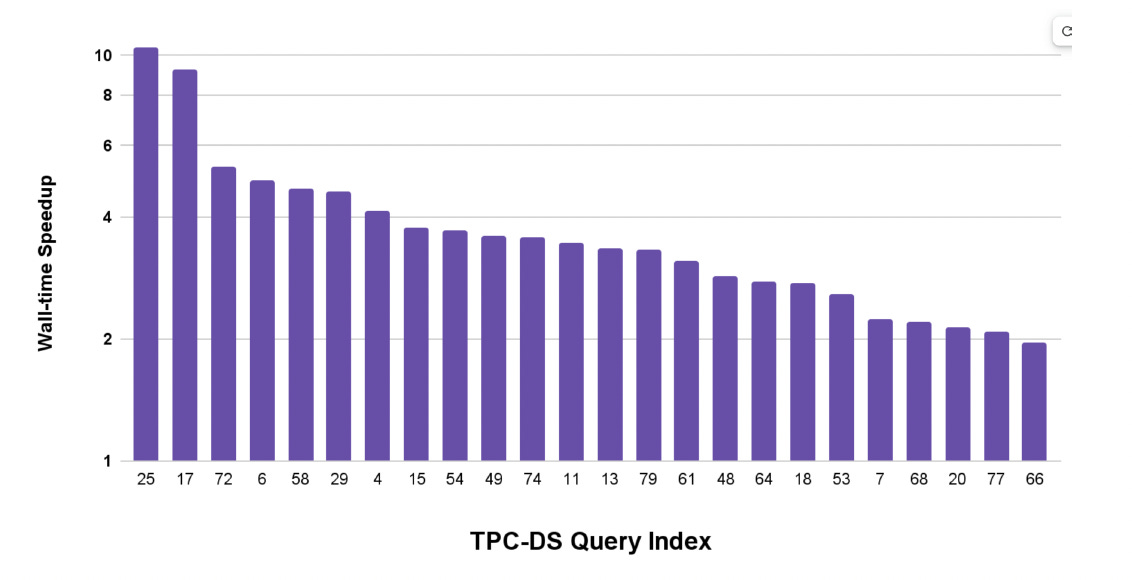
It shows the TPC-DS query speedup for a subset of the queries. The wall clock execution time decreased by a factor of four with metadata caching.
4.4 Accelerating Spark Performance over Storage APIs
A lot of BigQuery customers use Apache Spark SQL in addition to BigQuery SQL.
The open-source Spark BigQuery Connector provides an out-of-the-box integration of the storage APIs with Spark DataFrames using Spark’s DataSourceV2 interface.
Spark executors perform a parallel read of the streams returned from read session. The read API returns the rows in the Apache Arrow columnar data. Spark natively support Arrow so it minimizes the memory copies.
Initially read API was using Dremel’s row-oriented Parquet reader. The rows are then translated into the Superluminal columnar in-memory format. It is slow because of the translation required from row based to column based format.
The team implemented a vectorized Parquet reader that can directly emit Superluminal columnar batches from Parquet.
We have learned about the Big Metadata statistics in the last section. The CreateReadSession API is extended to return this data statistics. The Spark connector uses these statistics to improve query plans.
On the TPC-H benchmark, Spark performance against BigLake tables now match or exceed the baseline of Spark’s direct GCS reads.
4.6 BigLake Managed Tables (BLMTs)
BigLake managed tables are fully managed by BigQuery.
They stored data in open-source formats in customer owned cloud storage buckets.
BLMTs support DML, high-throughput streaming through the Write API, and background storage optimizations.
We have already seen that these tables stores metadata in Big Metadata. The storage format of the metadata is Apache Iceberg.
So users can export the Iceberg snapshot of the metadata to cloud storage and now any query engine compatible with Iceberg can query the data.
There are couple of benefits of BLMTs over open-source formats like Iceberg/Delta Lake.
BLMTs are not constrained by the need to atomically commit metadata to an object store.
Open table formats store the transaction log along with the data. The log can be tempered.
5. Supporting Unstructured Data
In today’s world, most of the data is unstructured such as documents, audio, and images. It is harder to analyze than structured or semi-structured data.
BigQuery Object tables provide a SQL interface to object store metadata. BigLake enables users to analyze unstructured data using local and remote system with SQL commands.
Let’s understand these object tables.
5.1 Object Tables
Object tables are system-maintained tables.
Rach row in the table represents an object, and columns contain attributes of that object. The attributes may be URI, object size, MIME type, creation time etc.
So you can imagine that the select * on this table is like doing ls/dir command on file system.
The BigLake features are naturally extended for the unstructured data.
Fine-grained Security: Object tables uses the same delegate access model we saw for structured data.Object tables can generate signed URLs for each object they have access to.
Scalability: Object tables store object store metadata as table data. It means we are inheriting the scalability of BigQuery. For example, listing billions of files will not hours now.
Metadata Caching: Object tables reuse much of the metadata caching mechanism we studied in Big Metadata system.
5.2 Inference and Integration with AI/ML
BigQuery ML supports both inference within the query engine and outside the query engine.
5.2.1 In-Engine Inference
SELECT uri , predictions FROM
ML. PREDICT (
MODEL dataset1.resnet50 ,
(
SELECT ML. DECODE_IMAGE ( data ) AS image
FROM dataset1.files
WHERE content_type = 'image/jpeg '
AND create_time > TIMESTAMP ('23 -11 -1 ')
)
);The code above shows In-engine inference on images.
The query applies the ResNet image classification model to JPEG files. It reads an object table named dataset1.files and filters it down to JPEG images. It generates inference directly in BigQuery using a imported model named dataset1.resnet50. At last it returns the object URI and the inferred class.
5.2.2 External Inference
CREATE OR REPLACE MODEL
mydataset.invoice_parser
REMOTE WITH CONNECTION
us.myconnection
OPTIONS (
remote_service_type = ' cloud_ai_document ',
document_processor = 'proj/my_processor '
);
SELECT *
FROM ML. PROCESS_DOCUMENT (
MODEL mydataset . invoice_parser ,
TABLE mydataset . documents
);The code above shows external inference using Document AI.
The query uses a proprietary Document AI model to parse receipts. It first registers a Cloud Document AI processor endpoint as a remote model. After that it executes inference remotely on all the files referenced by the object table named mydataset.documents. Finally it returns all the fields extracted from each document.
BigQuery supports two forms of external inference:
Customer-owned models hosted on Vertex AI.
Inference using Google’s first-party models.
6. Omini
BigQuery Omni is a novel approach for cross-cloud data analytics.
Customers can analyze data residing in BigQuery managed storage, Google Cloud Storage (GCS), Amazon S3, and Azure Blob Storage in-place using Omini.
Omni enables BigQuery’s compute engine to run on all major cloud platforms (AWS, Azure, GCP) by bringing Dremel to the data.
Customers do not need to move or copy data across clouds to GCP.
The diagram below shows the implementation approach of Omni.

The critical pieces of the BigQuery data plane runs on foreign clouds using Kubernetes clusters. The control plane still runs on the GCP.
6.1 Architecture and Deployment
Omni uses a hybrid cross-cloud architecture consisting of many micro services connected via Stubby.
Stubby is Google’s internal RPC framework and supports policy-based authorization.
Each micro service has its own set of authorization rules that define which other services can talk to it. These rules are defined statically, and remain constant throughout a deployment’s lifetime.
Omni is a regional service with full regional isolation guarantees. Omni’s deployment consists of two components:
Binary deployments of pre-built binaries such as Dremel
Configuration deployments that consist of serialized configuration files.
All binaries and config files are built from Google’s Piper source system.
Omni follows a multi-phase rollout deployment model similar to BigQuery on GCP, where the deployment of binaries/configs progresses through one or more regions at a time.
Config deployments are separate from binary deployment and usually follow a shorter time window or the entire deployment phase.
Omni’s control plane consists of the same micro services that are used in BigQuery on GCP. Users interact with standard BigQuery public APIs hosted by the control-plane.
All query requests from users are handled by the Job Server. The Job Server does various preprocessing tasks, such as query validation, IAM-based authorization, metadata lookup, and then forwards the query to the data-plane on the foreign cloud.
Data plane components include the Dremel query engine, and caching layer, and a few required infrastructure dependencies. The data-plane also runs a few Borg dependencies, such as Chubby to provide a consistent runtime execution environment across all clouds.
6.2 VPN/Networking
There is a secure communication required between control plane and data plane.

The diagram above provides an overview of how Omini ensure this secure channel.
Omni uses a QUIC-based zero-trust VPN. This VPN enables network endpoints hosted outside of Google production data centers to transparently communicate with services within Google.
6.3 Security
Omni is a multi-tenant system. It is built to provide the same level of security benefits as a single tenant architecture.
Omini has built various defense-in-depth security features into its architecture.
Object access credentials scope (Per-Query Isolation)
LOAS based addition authentication through untrusted proxy(Per Query/Regional isolation)
Security Realms (Regional isolation)
Human Authentication
Binary Authorization
6.5 Dremel on Non-GCP Clouds
Dremel runs natively on Borg infrastructure within Google. The Omini team built a minimal borg-like environment in AWS that consists of key services used by Dremel.
Chubby Google’s distributed lock service
Stubby Google’s internal RPC framework that supports policy-based authorization
Envelope, a sidecar container equivalent to jobs running in Borg
Dremel’s in-memory shuffle tier
Pony, a high performance user-space host networking stack
All above services are migrated to AWS to make them run natively in AWS VPC.
6.6 Operating in a Multi-Cloud Environment
The services required to operate the query engine are managed by a large number of teams within Google.
Omini team indexed heavily on providing the same release and support experience for these teams in order to reduce the cost of supporting Omni.
This required building integrations or adapters into Google’s release system, monitoring, logging, crash analysis, distributed tracing, internal DNS, and service discovery systems.
Creating bridges to these existing systems has proven to be very beneficial to the operation of Omni.
6.6 Cross Cloud Analytics
Data analytics users commonly have data in multiple clouds and regions.
Customers have business needs to bring this data together.
Omini did two innovations in this space through both cross-cloud queries and cross-cloud materialized views.
6.6.1 Cross-Cloud Queries
Most databases and data analytics engines do not allow a direct join between tables residing in different regions (or clouds).
The Omni architecture provides a way to avoid data transfer complications by leveraging the availability of a fully managed query engine in multiple clouds.
BigQuery users can execute a query that joins data from a GCP region with one or more Omni regions in a single SQL statement as shown in the below code.
SELECT o.order_id , o.order_total , ads.id
FROM local_dataset.ads_impressions AS ads
JOIN aws_dataset.customer_orders AS o
ON o.customer_id = ad.customer_idOmini parses each query and identify if there are any tables that are located in remote regions.
If it find table references to one or more regions then Omini retrieve the remote table metadata. It split the query into regional subqueries with appropriate filter push down.
Omini then submit new queries as cross-region Create Table As Select queries that run in the remote regions and push the data back into the local tables.
The BigQuery query engine running locally in each region executes the corresponding query and pushes the results to the primary region.
Once the remote queries are complete, all the remote data is available in temporary tables in the same region. The query is then rewritten to perform a regular join between local and temp tables.
6.6.2 Cross-Cloud Materialized Views
Omni supports incremental cross cloud data transfer.
Cross Cloud Materialized Views (CCMV) provide incremental replication of data from Omni region to GCP region by maintaining the replication state. It is shown in the diagram below:

Omni CCMVs replicate incrementally to reduce egress costs.
Omini first create a local materialized viewin the foreign-cloud region with object storage as the storage medium. This local materialized view is periodically refreshed.
The materialized view replication process relies on stateful file based replication that copies the files from AWS S3 to Google’s Colossus file system.
Network throughput is controlled through Google Cloud projectquotas. Customers are charged based on the physical bytes copied.
7. Conclusion
The paper presents three key innovations in BigQuery toward a multi-cloud lakehouse.
BigLake tables evolve pieces of core BigQuery storage and metadata infrastructure to unify managed warehouse data with open-source data lakes. It provcides uniform fine-grained governance and significant performance improvements. The fully managed BigLake tables that provide ACID transactions and other valuable features.
BigLake Object tables supports unstructured data. It allows integrating data types like documents, images, and audio into an enterprise data warehouse. both Both in-engine and external inference techniques enable several use-cases spanning analytics and AI/ML.
Omni allows our lakehouse features to enable multi-cloud use cases
by seamlessly shipping Dremel and other key dependencies on non-
GCP clouds.
References
Databricks Delta Lake paper post
Large-scale cluster management at Google with Borg
Vortex: A Stream-oriented Storage Engine For Big Data Analytics
The Chubby Lock Service for Loosely-Coupled Distributed Systems