
Insights from Paper: Google Napa : Powering Scalable Data Warehousing with Robust Query Performance at Google

1. Abstract
Google services generate a vast amount of data. It is challenging to store and serve these planet-scale data sets.
Scalability, sub-second query response times, availability, and strong consistency are incredibly demanding requirements. In addition, ingestion of massive amounts of streaming data needs to be supported.
A team at Google developed and deployed in the production of an analytical data management system called Napa. Napa meets all the above-said requirements.
Napa aggressively used materialized views. It provides robust query processing and flexible configuration for clients.
2. Introduction
Google business users interact with the data through sophisticated analytical front-ends to gain insights into their businesses.
These front-ends issue complex analytical queries over vast amounts of data and expect a response time of a few milliseconds. A massive stream of updates continuously updates multiple petabytes of data.
Users require the query results to be consistent and fresh.
Napa was built to replace Google Mesa. At the time of this writing, it had been operational for multiple years. Napa inherited many petabytes of historical data from Mesa.
Let’s discuss the key aspects of Napa.
Robust Query Performance:
The clients expect low query latency (a few milliseconds) and consistent maintenance of this low latency.
Flexibility:
The clients require the flexibility to change system configurations to fit their dynamic requirements. For example, not all clients require the same freshness for ingested data or are willing to pay for “performance at any cost.”
High-throughput Data Ingestion:
The clients expect the system to be performant under a massive update load.
3. Napa’s Design Constraint
Napa’s client differs in three perspectives:
Query performance
Data freshness
Cost
Query performance and query latency are used interchangeably.
Data freshness is measured by the time between adding a row to a table and making it available for querying.
Costs are primarily machine resource costs.
One important point about query performance is that clients look for not only low latency but also predictable query performance.
3.1 Clients Need Flexibility

Napa’s clients can be categorized as making a three-way tradeoff between data freshness, resource costs, and query performance.
First, let’s define ingestion and storage from Napa’s perspective.
“Ingestion” refers to data being presented to Napa and beginning its merge into the system.
“Storage” refers to the new data applied to the base table and all materialized views it affects.
Now, let’s understand different problems.
Always sacrifice freshness: If ingestion is tightly coupled with storage, it can only go as fast as the storage bandwidth.
Sacrifice query performance or consistency: If storage is tightly coupled with the view, either query performance or consistency will be sacrificed.
4. Design Choices Made By Napa
Napa has to be highly scalable to process a stream of updates and simultaneously serve millions of queries with good performance.
Napa relies on materialized views for predictable and high query performance.
Napa’s high-level architecture consists of three main components, as shown in the below diagram.

The ingestion framework is responsible for committing updates to the tables, which are called deltas. Deltas are write-optimized to satisfy the durability requirements.
The storage framework incrementally applies updates to tables and their views. Napa tables and their views are maintained incrementally as log-structured merge forests. Deltas are constantly consolidated to form larger deltas.
Query serving is responsible for answering client queries. At query time, the system merges necessary deltas of the table (or view). Google F1 Query is used as the query engine for data stored in Napa.
Napa decouples ingestion from view maintenance.
It also decouples view maintenance from query processing.
4.1 Providing Flexibility to Clients
Users specify their requirements regarding expected query performance, data freshness, and costs.
These requirements are translated to internal database configurations, such as the number of views, quota limits on processing tasks, and the maximum number of deltas that can be opened during query processing.
Napa introduced the concept of a Queryable Timestamp (QT).
It provides clients with a live marker.
It indicates freshness since [Now() - QT] indicates data delay.
The client can query all data up to the QT timestamp.
The continual advancement and staying within QT's freshness target indicate that the system is able to apply updates to the tables and views within the cost constraints given in user configuration.
Let’s understand the three categories of Napa clients and how the system uses QT advancement criteria for those.
Tradeoff freshness
Some Napa clients are cost-conscious. Good query performance and moderate costs are important.
For such a client, Napa’s QT advancement criteria is contingent on maintaining a moderate number of views and fewer deltas to merge at query execution time. To keep the cost low, Napa will use uses fewer worker tasks.
Tradeoff query performance
Some Napa clients require fresh answers but have low or moderate query performance demands.
For these clients, the QT advancement criteria is contingent on
fewer views but relatively more deltas that must be merged at query execution time. The query performance is lower because of more deltas for each table and view.
Tradeoff costs
Some Napa clients need good query performance and data freshness
is of utmost importance for them, even at higher costs.
For such clients, QT advancement criteria are contingent on numerous views, and the number of deltas at merge time is very low.
4.2 Data Availability
Napa guarantees that the system will remain operational despite such outages.
Napa provides this level of fault tolerance by replicating client databases at multiple data centers and ensuring that the replicas are mutually consistent.
Napa decouples the execution of data and metadata operations.
Data operations are executed asynchronously at each of the replicas.
Metadata operations are used periodically to ensure that the replicas remain synchronized.
Relatively infrequent metadata operations use Spanner to ensure all replicas' mutual consistency. The queryable timestamp indicates a state at which all tables and views in a database are globally consistent across all data centers.
5. System Architecture
Napa’s high-level architecture consists of data and control planes, as shown in the diagram below.
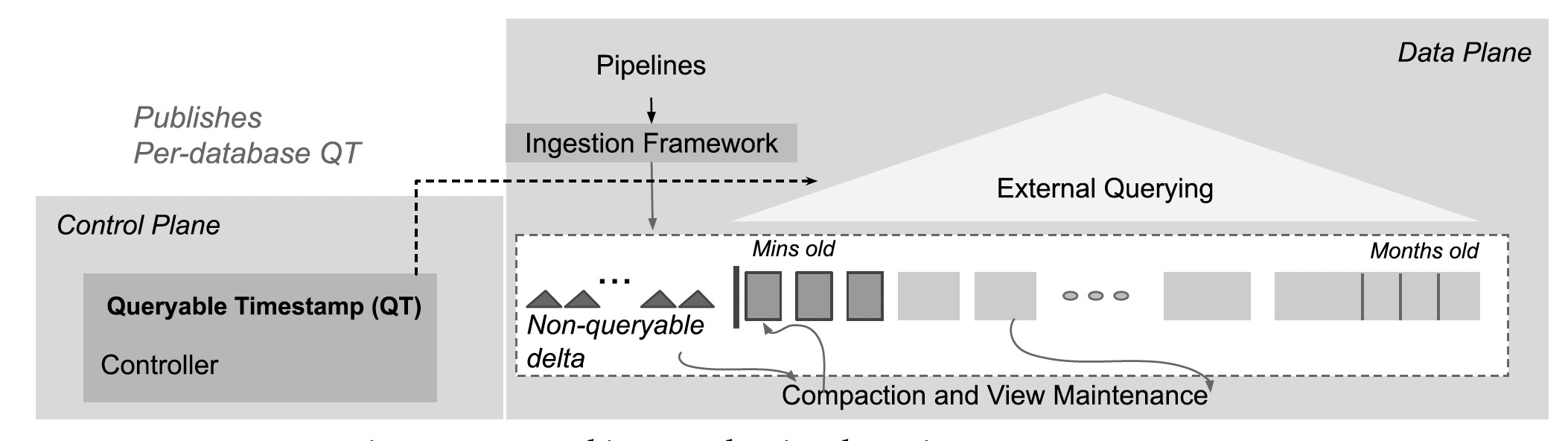
This architecture is deployed at multiple data centers to manage the replicas at each data center.
The data plane consists of ingestion, storage, and query serving.
The control plane comprises a controller that coordinates work among the various subsystems.
The controller is also responsible for synchronizing and coordinating metadata transactions across multiple data centers.
Napa clients create databases and tables along with their associated schemas. The clients can optionally create materialized views for each table.
Napa uses the Google File System (Colossus) as a disaggregated storage infrastructure.
Napa uses Spanner for strict transaction semantics.
Napa uses F1 Query for query serving and large-scale data processing, such as view creation and maintenance.
Napa relies on views as the main mechanism for good query performance.
Napa tables/materialized views are sorted, indexed, and range-partitioned by their (multi-part) primary keys.
Range-partitioned indexed tables can effectively answer most Napa queries.
The Napa controller schedules compaction and view update tasks to keep the count of deltas for a table to a configurable value.
Napa supports database freshness of near-real time to a few hours.
6. Ingesting Trillions of Rows
The ingestion framework aims to allow ingestion pipelines to insert trillions into Napa without a major overhead.
One of Napa’s key techniques is to decouple ingestion from view maintenance.
The ingestion framework contributes to this design via two mechanisms.

The framework has to accept data, perform minimal processing, and make it durable.
All ingested rows are assigned a metadata timestamp for ordering and then marked as committed after other durability conditions, such as replication, have been satisfied.
The framework provides knobs to limit the peak machine costs by allowing configurations to increase or decrease the number of tasks that accept
data and perform the ingestion work of batching, aggregating, and
replicating.
Clients deliver the data to be ingested to any one of the Napa replicas/
Napa is responsible for ensuring that the data is ingested at all the replicas to ensure availability.
7. Queryable Timestamp
The queryable timestamp (QT) of a table is a timestamp that indicates the freshness of data that can be queried.
If QT(table) = X, the client can query all data ingested into the table before time X. The data after time X is not part of the query results.
The value of QT will advance from X to Y once the data ingested in the (Y-X) range has been optimized to meet the query performance requirements.
Optimizing the underlying data for reads and ensuring views are available to speed up the queries is an important criterion for ensuring good query performance.
A table in Napa is a collection of all of its delta files.
Each delta corresponds to an update received for the table over a window of time, as shown in the diagram below.
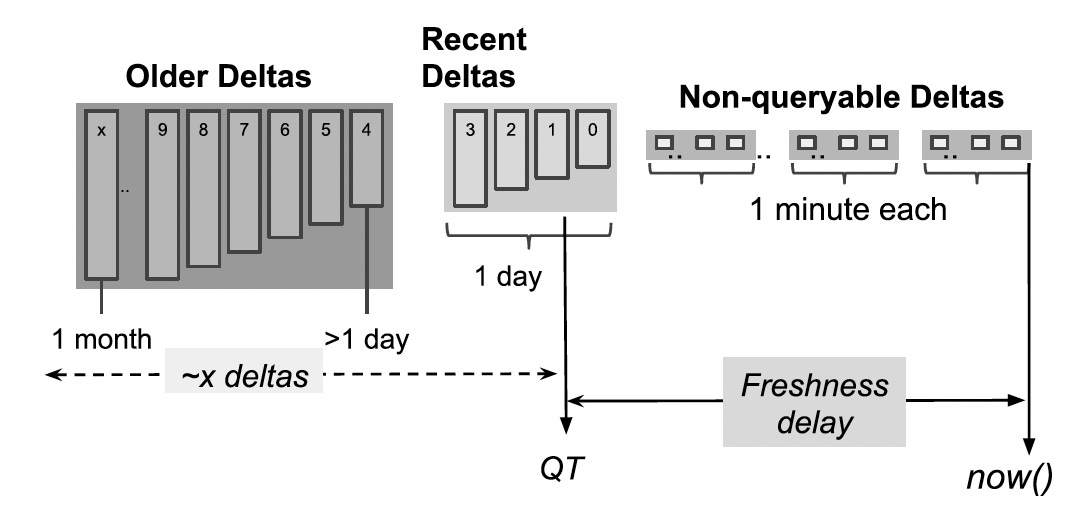
Each delta is sorted by its keys, range partitioned, and has a local B-tree like index. These deltas are merged as needed at query time.
Napa is a column store. It has to manage the dual concerns of maintaining views on the tables while achieving fast lookups.
Napa combines B-trees and PAX in the physical design to achieve these seemingly disparate goals.
QT depends on the progress of background operations, such as compactions and incremental view maintenance. The database's QT is the minimum of all the tables' QT. Each replica has a local value of QT.
8. Maintaining views at scale
Napa’s storage subsystem maintains views and compacts deltas, as well as ensuring data integrity and durability.
Napa supports materialized views that are joined to multiple tables.
View maintenance skews happen when the updates on the base tables are transformed into updates on the views.
The key aspects of the view maintenance framework include the following:
Use of F1 Query as a “data pump”
Replanning to avoid data skews
Intelligence in the loop
8.1 Query Optimization Challenges in View Maintenance
Efficiently processing large amounts of data means that one has to be careful not to destroy beneficial data properties such as sortedness and partitioning.
There are three classes of views based on the cost of maintaining them
The cheapest views to maintain in the framework are those
that share a prefix with the base table.
The second class of views are those that have a partial prefix
with the base table but not a complete prefix.
The third class of views are those where the base table and
views do not share any prefix.
8.2 Mechanics of Compaction
Compaction combines multiple input deltas into a single output delta.
Compacting asynchronously for querying reduces merging work at query time and leverages the compacted result across multiple queries.
Since the delta files are individually sorted, compaction is essentially merge sorting.
9. Robust Query Serving Performance
Obtaining query results within the order of milliseconds is a critical requirement for some Napa clients.
This section describes how the query-serving subsystem achieves robust performance using Queryable Timestamp (QT), materialized views, and various other techniques.
9.1 Reducing Data in the Critical Path
Napa uses multiple techniques to reduce the amount of data read to answer queries on the critical path.
If possible, Napa uses views to answer a query instead of the base table.
When F1 workers read data from Delta Servers, filters and partial aggregations are pushed down to minimize the amount of bytes transferred to F1 workers via the network.
Napa relies on parallelism to reduce the amount of data each subquery has to read. Napa maintains sparse B-tree indexes on its stored data. It uses them to quickly partition an input query into thousands of subqueries that satisfy the filter predicates.
9.2 Minimizing the Number of Sequential I/Os
When a query is issued, Napa uses the QT value to decide which metadata version to process.
The metadata, in turn, determines what data needs to be processed. Therefore, metadata reads are critical to query serving.
Napa ensures all metadata can always be served from memory without contacting the persistent storage.
All data reads go through a transparent distributed data caching layer through which file I/O operations pass.
The distributed cache is read-through and shares work on concurrent read misses of the same data.
The distributed caching layer significantly reduces the number of I/Os but cannot eliminate them.
Napa performs offline and online prefetching to further reduce the number of sequential I/Os in the critical path.
9.3 Combining Small I/Os
Napa aggressively parallelizes the work by partitioning the query into fine-grained units and then parallelizing I/O calls across deltas and queried columns.
Napa uses QT to limit the number of queryable deltas to combat amplification on tail latency.
Lazy merging across deltas:
Each Delta Server must merge rows across all deltas based on the full primary key when processing a subquery.
Size-based disk layout:
Napa uses a custom-built columnar storage format, which supports multiple disk layout options based on delta sizes.
The PAX layout can combine all column accesses into one I/O for lookup queries for small deltas.
A column-by-column layout is used for large deltas that is I/O efficient for scan queries but requires one I/O per column for lookup queries.
9.4 Tolerating Tails and Failures
Napa adopts the principle of tolerating tail latency rather than eliminating it.
For a non-streaming RPC, Napa uses the hedging mechanism, which sends a secondary RPC identical to the original one to a different server after a certain delay and waits for a faster reply.
Napa estimates its expected progress rate for a streaming RPC and requires the server to execute it periodically to report progress.
Pushdown operators like filtering and partial aggregation must be carefully handled in progress reporting as they can significantly reduce the data size.
10 Related Work
For analytical data management, many commercial solutions are available from Teradata, Oracle, IBM, Microsoft, Snowflake, and Amazon.
Data analytics systems have evolved from the tight coupling of storage and computing to the disaggregated model of decoupled storage and computing.
Amazon Aurora decouples the transaction and query processing layer from the storage layer.
Redshift supports materialized views that are not continuously maintained.
Snowflake projects itself as a “virtual data warehouse,” which can be spun up on demand and brought down.
Napa provides continuous ingestion and high-performance querying with tunable freshness. It advances the idea of disaggregation by decoupling its architectural components: ingestion, aggregation, indexing, and querying.
Data analytics within Google :
Tenzing was Google's early attempt at building a large-scale data management system. It offered SQL over Map-Reduce on data stored in Colossus and Bigtable.
Dremel is a scan-based querying system that enables large-scale querying of Google’s log data using thousands of machines.
Procella is a recent scan-based system that improves upon Dremel by using an advanced storage format to support filter expressions, zone maps, bitmaps, bloom filters, partitions, and sorting by keys.
Napa is a fully indexed system optimized for key lookups, range scans, and efficient incremental maintenance of indexes on tables and views. It can easily support both ad-hoc and highly selective and less diverse queries.
Comparison with Mesa:
Napa is designed to replace Mesa as a multi-tenant, multi-homed, distributed, globally replicated data management system.
Napa advances the state of the art in database configuration to meet the end client’s freshness, cost, and query performance tradeoffs.
Napa has superior consistency semantics. It provides a single database-level queryable timestamp. Napa also supports views with full SQL generality.
Napa uses F1 Query, an SQL engine, to process user queries and maintain tables, materialized views, and indexes.
Napa is better than Mesa regarding query latency and the cost of running the system.
LSM-based Indexing Systems:
Napa uses a variant of B+-trees that exploits Napa tables' multi-part keys.
Log-structured merge-trees (LSM) adapt B-tree indexes for high update rates. Napa belongs to a class of LSM systems that trade high write throughput for fast reads.
Writes are written to level files, which are compacted to form larger ones. Reads merge these at run-time.
11. Conclusion
Napa is an analytical data management system.
It serves critical Google dashboards, applications, and internal users.
It has a combination of characteristics that is perhaps unique:
Relying on materialized views to ensure that most queries are sub-second look-ups.
Maintaining views while ingesting trillions of rows and giving clients
the flexibility to tune the system for data freshness, query latency, and costs.
Napa’s configurability means that the same system can serve cost-conscious and high-performance clients in different configurations.
References
Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases