
Insights from paper: Google : The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive Scale, Unbounded, Out of Order Data Processing

1. Abstract
In today’s world, unbounded, unordered, large-scale datasets are common.
These datasets require sophisticated data processing and faster results, such as event-time ordering and windowing.
The paper proposes that we must stop trying to groom unbounded datasets into finite pools of information that eventually become complete.
Instead, let's assume we will never know if or when we have seen our data. As practitioners, let’s use principled abstractions to manage trade-offs between correctness, latency, and cost.
The paper introduces the Dataflow Model, which supports this new approach. It allows flexible trade-offs along these dimensions and thoroughly examines its semantics, core design principles, and validation through real-world use cases.
This model is based on Google FlumeJava and Google MillWheel. If you want to learn these technologies, read my posts here and here, which are based on these papers.
2. Introduction
The paper provides a solid example of how to understand the challenges of streaming systems and how the currently available solutions are failing.
Example: A streaming video provider wants to monetize their content by displaying ads and billing advertisers. The platform supports online and offline views of content and ads.
Advertisers and content providers want to know the stats of videos and ads watched. They want this information quickly so that they can adjust budgets and bids, change targeting, tweak campaigns, and plan future directions.
Batch systems such as MapReduce, FlumeJava, and Spark suffer latency problems.
It is unclear how some streaming systems (Aurora, TelegraphCQ) would remain fault-tolerant for a given scale.
Many systems cannot provide exactly once semantics (Storm, Samza).
Many systems lack the temporal primitives necessary for windowing.
Some systems (Flink, CEDR, and Trill) provide windowing, but their windowing semantics and periodic punctuations are insufficient to express sessions.
MillWheel and Spark Streaming are both sufficiently scalable, fault-tolerant, and low-latency to act as reasonable substrates but lack high-level programming models that make calculating event-time sessions straightforward.
Lambda architecture systems can achieve many desired requirements but fail on the simplicity axis.
Conceptual contributions of the paper:
A single unified model, which:
Allows for calculating event-time ordered results, windowed by features of the data themselves, over an unbounded, unordered data source, with correctness, latency, and cost tunable across a broad spectrum of combinations.
Decomposes pipeline implementation across four related dimensions, providing clarity, composability, and flexibility
What results are being computed?
Where in event time are they being computed?
When in processing time, are they materialized?
How do earlier results relate to later refinements?
3. Separates the logical notion of data processing from the underlying physical implementation, allowing the choice of batch, micro-batch, or streaming engine to become one of simply correctness, latency, and cost.
Concrete contributions of the paper:
A windowing model that supports unaligned event-time windows and a simple API for their creation and use.
A triggering model that binds the output times of results to the pipeline's runtime characteristics, with a powerful and flexible declarative API for describing desired triggering semantics.
An incremental processing model that integrates retractions and updates into the windowing and triggering models described above.
Scalable implementations of the above on top of the MillWheel streaming engine and the FlumeJava batch engine, with an external reimplementation for Google Cloud Dataow, including an open-source SDK that is runtime-agnostic.
A set of core principles that guided the design of this model.
Brief discussions of our real-world experiences with massive-scale, unbounded, out-of-order data processing at Google motivated the development of this model.
Windowing
Windowing is required for some operations, such as aggregation, outer joins, and time-bounded operations, when dealing with unbounded data.
Windows may be either aligned, i.e., applied across all the data for the window of time in question, or unaligned, i.e., applied across only specific subsets of the data.
The diagram below highlights three major windows encountered when dealing with unbounded data.
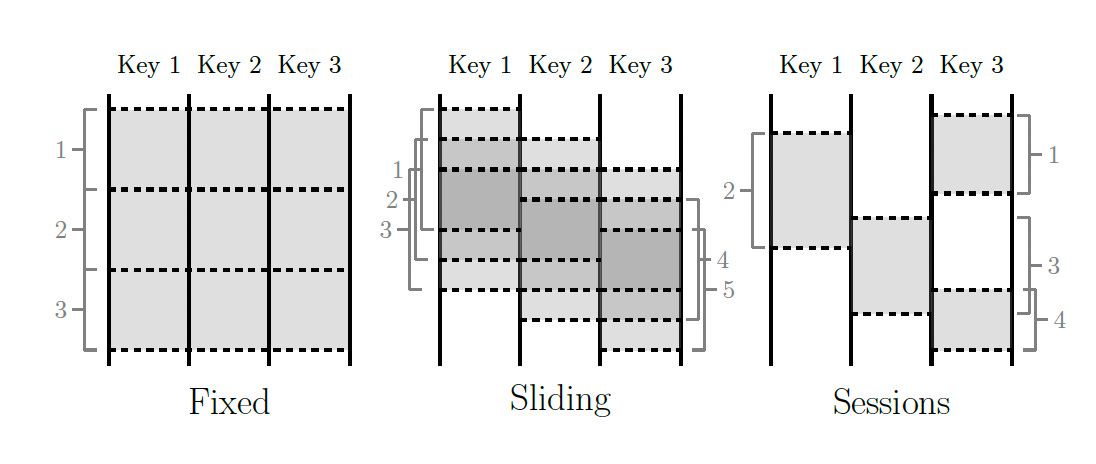
Fixed windows (tumbling windows) are defined by static window size, e.g., hourly or daily. They are generally aligned, i.e., every window applies across all data for the corresponding time.
Sliding windows are defined by a window size and slide period, e.g., hourly windows starting every minute. The period may be less than the size, meaning the windows overlap. Sliding windows are also typically aligned.
Sessions are windows that capture some period of activity over a subset of the data, in this case, per key. Typically, they are defined by a timeout gap. Any events that occur within a period less than the timeout are grouped as a session. Sessions are unaligned windows.
Time Domains
When processing data relating to events in time, there are two inherent domains to consider.
Event Time - It is the time at which the event occurred, i.e., a record of system clock time (for whatever system generated the event) at the time of occurrence.
Processing Time - It is when an event is observed at any given point during the processing within the pipeline, i.e., the current time according to the system clock.
Event time for a given event essentially never changes, but processing time changes constantly for each event as it flows through the pipeline and time marches ever forward.

As shown in the above diagram, the skew between the two domains will change dynamically.
3. Dataflow Model
3.1 Core Primitives
The Dataow SDK has two core transforms that operate on the (key; value) pairs flowing through the system.
ParDo for generic parallel processing.
Each input element to be processed (which may be a finite collection) is provided to a user-defined function (called a DoFn in Dataow), which can yield zero or more output elements per input.

In the above example, the operation (ExpandPrefixes) expands all prefixes of the input key.
GroupByKey for key-grouping (key; value) pairs.
The GroupByKey operation, on the other hand, collects all data for a given key before sending them downstream for reduction. See the example below:

If the input source is unbounded, we cannot know when it will end. The common solution to this problem is to window the data.
3.2 Windowing
The primary contribution here is support for unaligned windows. Most systems try to implement some variant of GroupByKeyAndWindow.
There are two insights of the above work:
Treating all windowing strategies as unaligned from the model's perspective is simpler.
Windowing can be broken apart into two related operations:
Set<Window> AssignWindows(T datum) - assigns the element to zero or more windows.
Set<Window> MergeWindows(Set<Window> windows - merges windows at grouping time.
To support event-time windowing natively, instead of passing (key; value) pairs through the system, Dataflow now passes (key; value; event time; window) 4-tuples.
Window Assignment
From the model's perspective, window assignment creates a new copy of the element in each window to which it has been assigned. See the example diagram below:

Window Merging
Window merging occurs as part of the GroupByKeyAndWindow operation.
Let’s take an example to understand it.

The diagram above shows four example data, three for k1 and one for k2. They are assigned 30 minutes timeout. We then begin the GroupByKeyAndWindow operation, which is a five-part composite operation:
DropTimestamps - Drops element timestamps, as only the window is relevant from here onwards.
GroupByKey - Groups (value; window) tuples by key.
MergeWindows - Merges the set of currently buffered windows for a key. The windowing strategy defines the actual merge logic. In this case, the windows for v1 and v4 overlap, so the sessions windowing strategy merges them into a new, larger session.
GroupAlsoByWindow - For each key, group values by window. After merging in the prior step, v1 and v4 are now in identical windows and thus are grouped together at this step.
ExpandToElements - Expands per-key, per-window groups of values into (key; value; event time; window) tuples, with new per-window timestamps. In this example, we set the timestamp to the end of the window. Still, any timestamp greater than or equal to the timestamp of the earliest event in the window is valid for watermark correctness.
API
Let’s see the examples briefly.
To calculate keyed integer sums:
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input
.apply(Sum.integersPerKey());
The same calculation but windowed into sessions with a 30-minute timeout:
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input
.apply(Window.into(Sessions.withGapDuration(
Duration.standardMinutes(30))))
.apply(Sum.integersPerKey());3.3 Triggers & Incremental Processing
We have two problems to fix after the windowing work is done.
We need some way of providing support for tuple-and processing-time-based windows.
We need some way of knowing when to emit the results for a window. Since the data concerning event time are unordered, we require another signal to
tell us when the window is done.
Using watermarks to solve the above problem has drawbacks, as they are either too slow or fast. So, watermarks alone are insufficient.
The paper uses triggers to stimulate the production of GroupByKeyAndWindow results in response to internal or external signals. Triggers complement the windowing model.
Windowing determines where data are grouped for processing in event time.
Triggering determines when, in processing time, the results of groupings are emitted as panes.
The system provides predefined trigger implementations for triggering at completion estimates at points in processing time and in response to data arrival.
The system also supports composing triggers into logical combinations. The users may define their triggers.
The triggers system provides a way to control how multiple panes of the same window relate to each other, in addition to controlling when results are emitted.
Discarding - Upon triggering, window contents are discarded.
Accumulating - Upon triggering, window contents are left intact in a persistent state, and later results refine previous results.
Accumulating & Retracting - Upon triggering, in addition to the Accumulating semantics, a copy of the emitted value is also stored in a persistent state. When the window triggers again in the future, a retraction for the previous value will be emitted first, followed by the new value.
3.4 Examples
Let’s work on the integer summation pipeline example we saw in the API section.
PCollection<KV<String, Integer>> output = input
.apply(Sum.integersPerKey());Let us assume we have an input source from which we observe ten data points. We will consider them in the context of both bounded and unbounded data sources.
The diagram below displays how these data relate together along both time axes.

The straight dotted line with a slope of one represents the ideal watermark, i.e., if there was no event-time skew and the system processed all events as they occurred.
In Dataow, the default triggering semantics are to emit windows when the watermark passes them.
Let us look at changing the trigger.
We apply a Window.trigger operation that repeatedly fires on one-minute periodic processing-time boundaries.
We also specify the Accumulating mode to refine our global sum over time.
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.accumulating())
.apply(Sum.integersPerKey());
We could switch to the Discarding mode to generate the delta in sums once per minute.
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.discarding())
.apply(Sum.integersPerKey());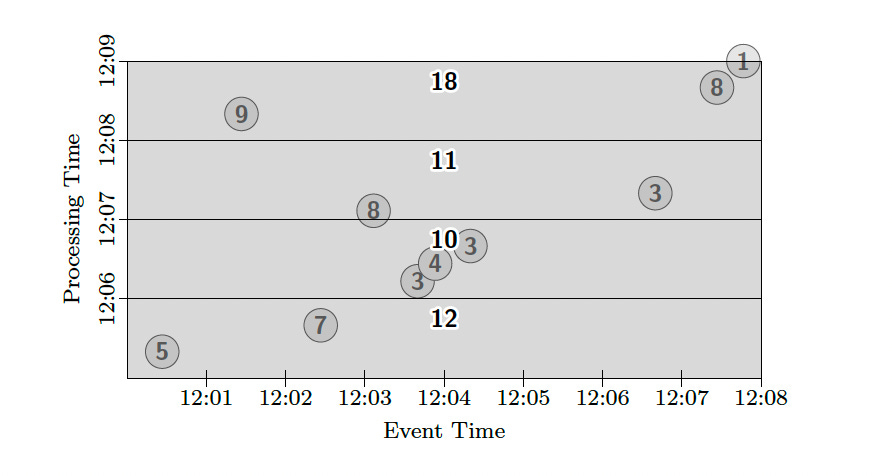
One more common windowing mode for the model is tuple-based windows. We can provide this sort of functionality by simply changing the trigger to fire after a certain number of data arrive, say two.
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtCount(2)))
.discarding())
.apply(Sum.integersPerKey());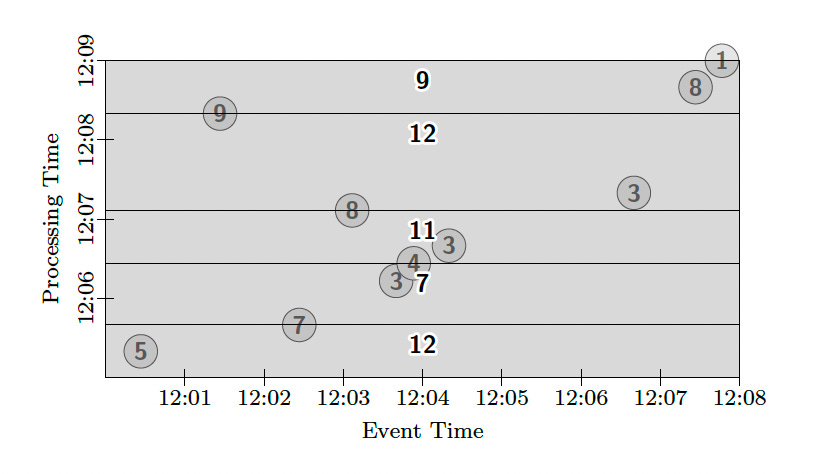
Let us now move to the other option for supporting unbounded sources.
To start with, let us window the data into fixed, two-minute Accumulating windows:
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES)
.accumulating())
.apply(Sum.integersPerKey());Here, we have not provided the trigger so the default trigger will be used. The watermark trigger fires when the watermark passes the end of the window in question.
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(Repeat(AtWatermark())))
.accumulating())
.apply(Sum.integersPerKey());
Let’s now execute in a micro-batch engine over this data source with one-minute micro-batches. The system would gather input data for one minute, process it, and repeat.

We have seen many examples of batching. Let’s now consider this pipeline executed on a streaming engine.
Most windows are emitted when the watermark passes them. Note, however, that the datum with value 9 is actually late relative to the watermark.
Once the 9 finally arrives, it causes the first window (for event-time range [12:00; 12:02)) to retrigger with an updated sum)

Suppose we want lower latency via multiple partial results for all our windows. In that case, we can add some additional processing-time-based triggers to provide us with regular updates until the watermark passes.
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(SequenceOf(
RepeatUntil(
AtPeriod(1, MINUTE),
AtWatermark()),
Repeat(AtWatermark())))
.accumulating())
.apply(Sum.integersPerKey());
The paper provides one more special example, covering Sessions with Retracting. I am leaving that to be figured out in the paper for curious readers. You will thank me later.
4. Implementation and Design
4.1 Implementation
The team has implemented this model internally in FlumeJava, with MillWheel used as the underlying execution engine for streaming mode.
The core windowing and triggering code is quite general, and a significant portion is shared across batch and streaming implementations.
4.2 Design Principles
The team believed in the below core set of principles:
Never rely on any notion of completeness.
Be flexible to accommodate the diversity of known use cases and those to come in the future.
Encourage clarity of implementation.
Support robust analysis of data in the context in which they occurred.
5. Conclusions
The future of data processing is unbounded data.
Based on the many years of experience with real-world, massive-scale, unbounded data processing within Google, the team believes the model presented here is a good step in the right direction.
It supports the unaligned, event-time-ordered windows modern data consumers require.
It provides flexible triggering and integrated accumulation and retraction.
It abstracts away the distinction between batch, micro-batch, and streaming, allowing pipeline builders to make more fluid choices between them.
It allows pipeline builders to appropriately balance the dimensions of correctness, latency, and cost to fit their use case.
It clarifies pipeline implementations by separating the notions of what results are being computed, where in event time they are being computed, when in processing time they are materialized, and how earlier results relate to later refinements.
References
Post on Apache Spark Streaming
TelegraphCQ: Continuous Dataflow Processing
NiagaraCQ: A Scalable Continuous Query System for Internet Databases
Semantics and Evaluation Techniques for Window Aggregates in Data Streams
Flexible time management in data stream systems
SECRET: a model for analysis of the execution semantics of stream processing systems